
Enhancing AI Initiatives with Ontologies and Controlled Vocabularies with Howard Diesel

Executive Summary
This webinar outlines key concepts and strategies for enhancing data modelling through the adoption of knowledge graphs and semantic clarity. Howard Diesel emphasizes the transition from traditional Enterprise Data Models to ontological frameworks, highlighting the importance of effective master data management and precise terminology. He addresses the challenges encountered in implementing Enterprise Data Models, including semantic inconsistencies, and proposes strategies for navigating these issues.
The webinar further explores the balance between UML and object-oriented modelling while integrating business definitions with Enterprise Data Models. By transforming conceptual models into logical data frameworks, organisations can better manage data at an enterprise level, ultimately leading to improved clarity, standardization, and insight generation in their data practices.
Webinar Details
Title: Enhancing AI Initiatives with Ontologies and Controlled Vocabularies With Howard Diesel
Date: 24 February 2025
Presenter: Howard Diesel
Meetup Group: DAMA SA User Group
Write-up Author: Howard Diesel
Contents
Technical Transformation of Data Model to Knowledge Graph
Business Language and Achieving Semantic Clarity
Data Modelling and Semantics
From Enterprise Data Model to Ontology
Strategies for Achieving Semantic Clarity in Enterprise Data Modelling
Challenges of Implementing Enterprise Data Models
Master Data Management and Terminology
Business Rule Manifesto and its Application in Data Modelling
Approaches in Data Modelling and Standardization
Understanding Definition Management
UML and Object-Oriented Modelling in Data Modelling
Challenges in Balancing Data Models and UML Class Models
Using UML and Knowledge Graphs in Enterprise Data Model and Local Data Analysis
Implementing Knowledge Graph Systems
Integration of Business Definitions and Enterprise Data Models
Process of Transforming a Conceptual Model into a Logical Data Model
The Implications of Abstraction in Academic Discussion
Managing Enterprise-Level Data Models
Managing Definition Management and Semantic Inconsistencies in the Business
The Importance of Definitions in Data Modelling
Technical Transformation of Data Model to Knowledge Graph
Howard Diesel opens the webinar and welcomes attendees. He takes a moment to share his intention to outline a technical transformation process of a data model to a knowledge graph, focusing on importing data into Neo4j Aura.
Figure 1 "Data Model to Knowledge Graph"
Business Language and Achieving Semantic Clarity
Over the past few weeks Howard notes that he has been discussing the importance of improving semantic clarity. Howard notes Marco Wobben’s presentation with regards to business language has been instrumental in this effort. CaseTalk, a tool developed by Marco Wobben, effectively extracts essential facts from our business. To enhance our semantic clarity, Howard notes that one should conduct an audit to assess our common understanding and definitions of data within the organization, ultimately striving for a more unified approach to semantics.

Figure 2 Data Model to Knowledge Graph Deck

Figure 3 Semantic Clarity Recap

Figure 4 Semantic Chain - Looking for More Meaning
Data Modelling and Semantics
The importance of foundational business definitions in data modelling was highlighted in discussions led by experienced trainers like Steve Hoberman. Howard reflects on his own experiences with the Data Modelling Scorecard at the South African central bank, noting that premature jumps into data modelling often led to misunderstandings about business definitions. Howard emphasises a structured approach and advocates for progressing from a business glossary to more complex artifacts like ontologies, facilitating machine-readable data models that can enhance knowledge graphs.
The development of an ontology is crucial for uncovering previously overlooked insights and addressing inconsistencies within organizational semantics. The challenge remains in ensuring semantic clarity, especially when using Large Language Models (LLMs) that may produce hallucinations due to existing disagreements in organizational definitions.
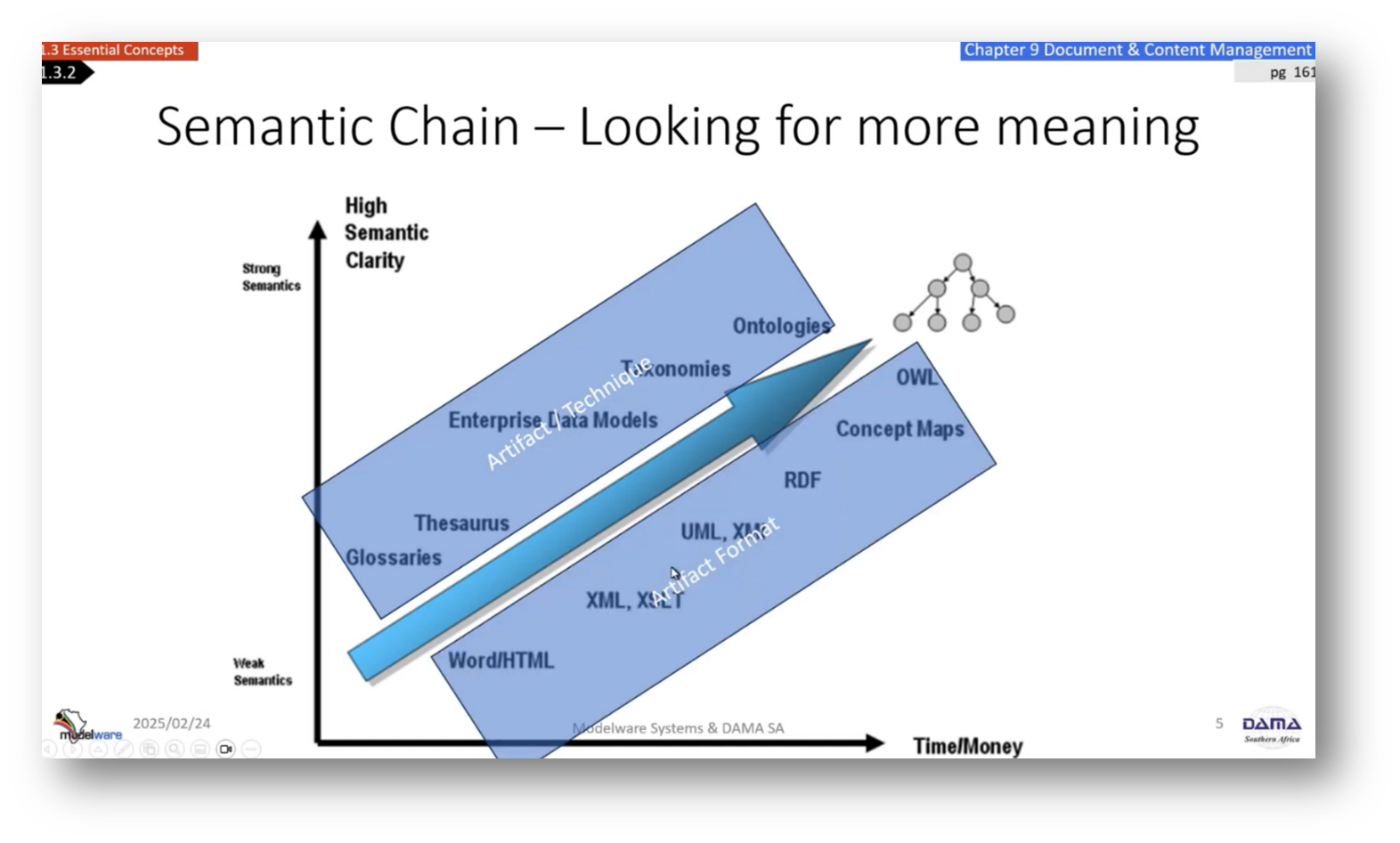
Figure 5 Artifact Technique and Format
From Enterprise Data Model to Ontology
Howard outlines the steps for transitioning from an Enterprise Data Model to a taxonomy and ontology using Visual Paradigm. He highlights the process of moving from a conceptual data model to a logical data model, and then to a class diagram, eventually converting it to JSON or OWL gUFO to integrate into a knowledge graph. Howard mentions the importance of writing business definitions, adding the influence of the methodologies of Mark Atkins and Terry Smith. This methodology helps establish core concepts relevant to business processes.
Eliciting business facts through detailed documentation of daily events by business personnel is invaluable when creating a business glossary. Recognising the ongoing learning opportunities from frameworks like CaseTalk that can enhance modelling efforts. When data modelling, a key challenge arises from the tendency of modellers to project their own biases onto customer definitions, rather than aligning with business experts. Effective data modelling requires a comprehensive understanding of business requirements and definitions, which can differ significantly across departments, leading to fragmented views of concepts like "customer."
It is imperative to prioritise clear definitions, involving dictionaries and architecture processes, and managing issues such as ownership and lifecycle. The complexity increases when trying to consolidate departmental interpretations into a cohesive enterprise definition, revealing that rushing into data modelling without sufficient groundwork can result in a loss of essential context and understanding.
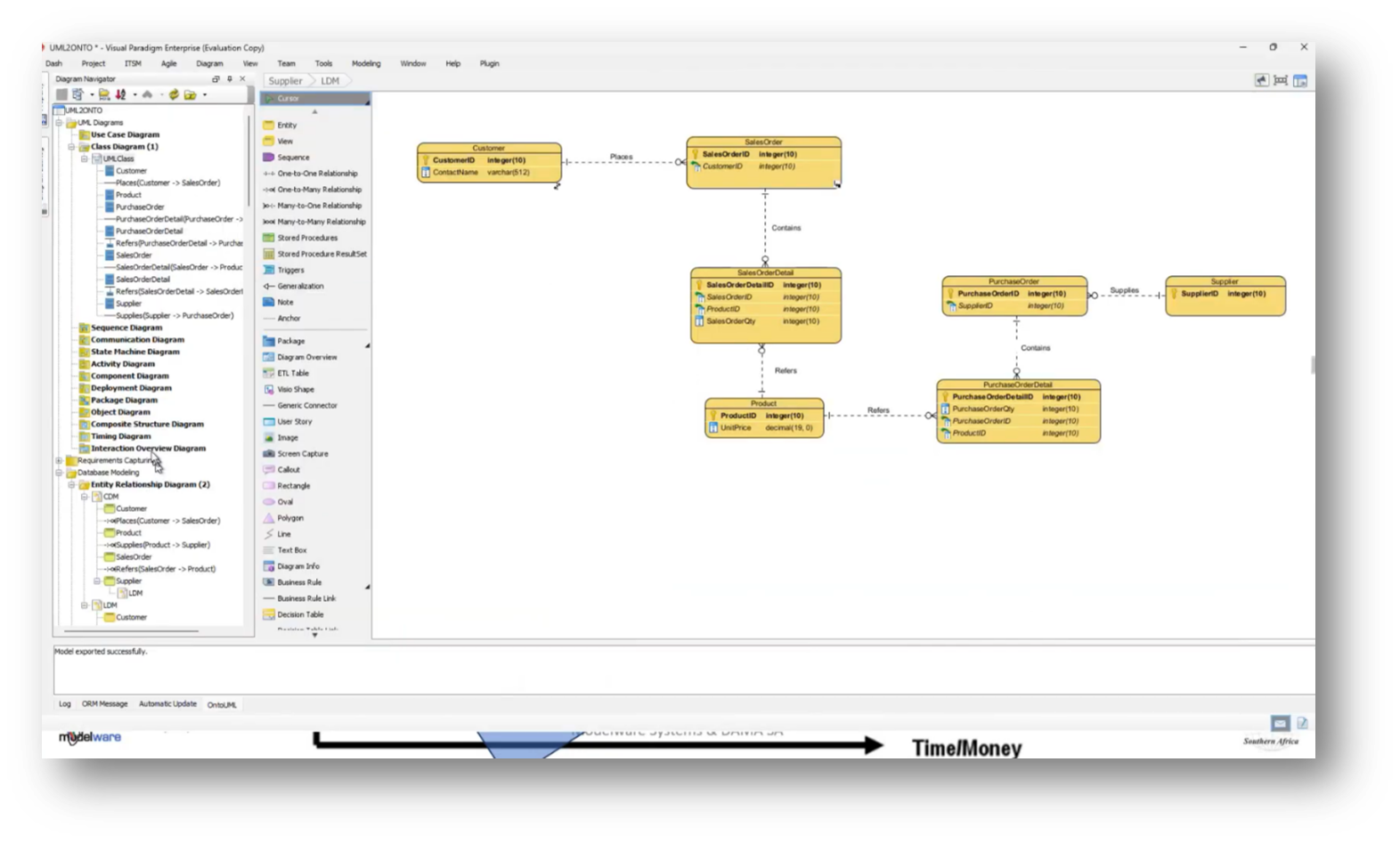
Figure 6 Logical Data Model

Figure 7 Class Diagram
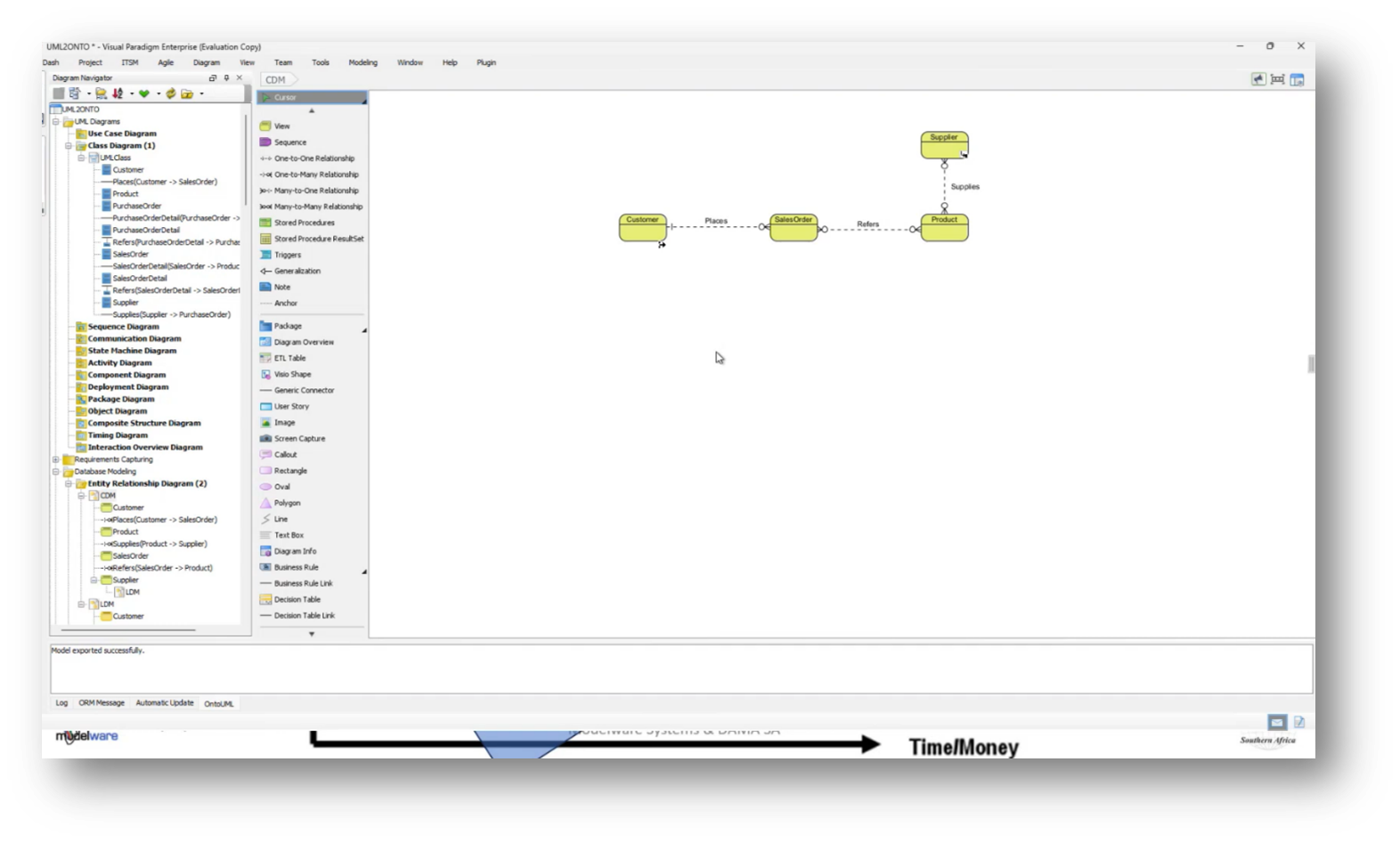
Figure 8 Conceptual Data Model
Figure 9 "Business Language FIRST"
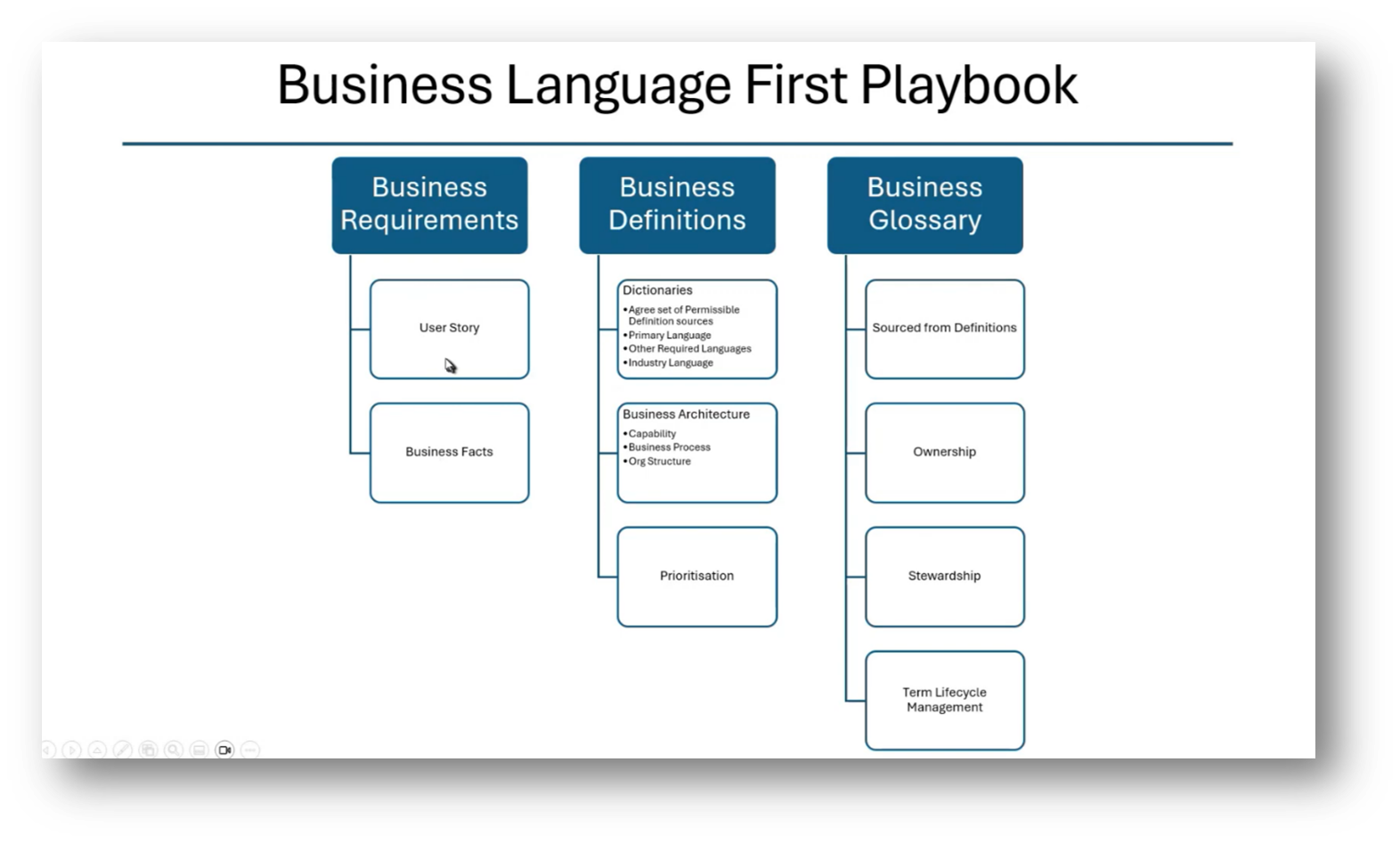
Figure 10 Business Language First Playbook

Figure 11 Customer Definition
Strategies for Achieving Semantic Clarity in Enterprise Data Modelling
Achieving semantic clarity in Enterprise Data Modelling within organisations can be challenging. Two of the attendees share their recognition that a lack of consensus on terminology and definitions hinders effective communication. Engaging business stakeholders in workshops is essential, though often difficult. A suggestion was made to gain practical experience by working in various business functions to better understand their needs.
Making a concerted effort to create consistency in data definitions is imperative. Additionally, Howard notes that many data warehouse projects fail due to delays in delivering results and expresses scepticism about the successful implementation of enterprise-wide master data management due to the difficulty of achieving organisational consensus.
Information architects and data architects play a crucial role in establishing and maintaining a consistent understanding of terminology across an organisation. They must balance the need for a comprehensive enterprise perspective with the dynamic nature of business departments, which often leads to evolving definitions. Consensus on terminology is essential, but lengthy definitions can hinder progress, as businesses continuously adapt.
Howard emphasises clear, full-sentence explanations of relationships between terms can enhance understanding. It is important to focus on relevant terms for each engagement, acknowledging that not every aspect can be addressed comprehensively.
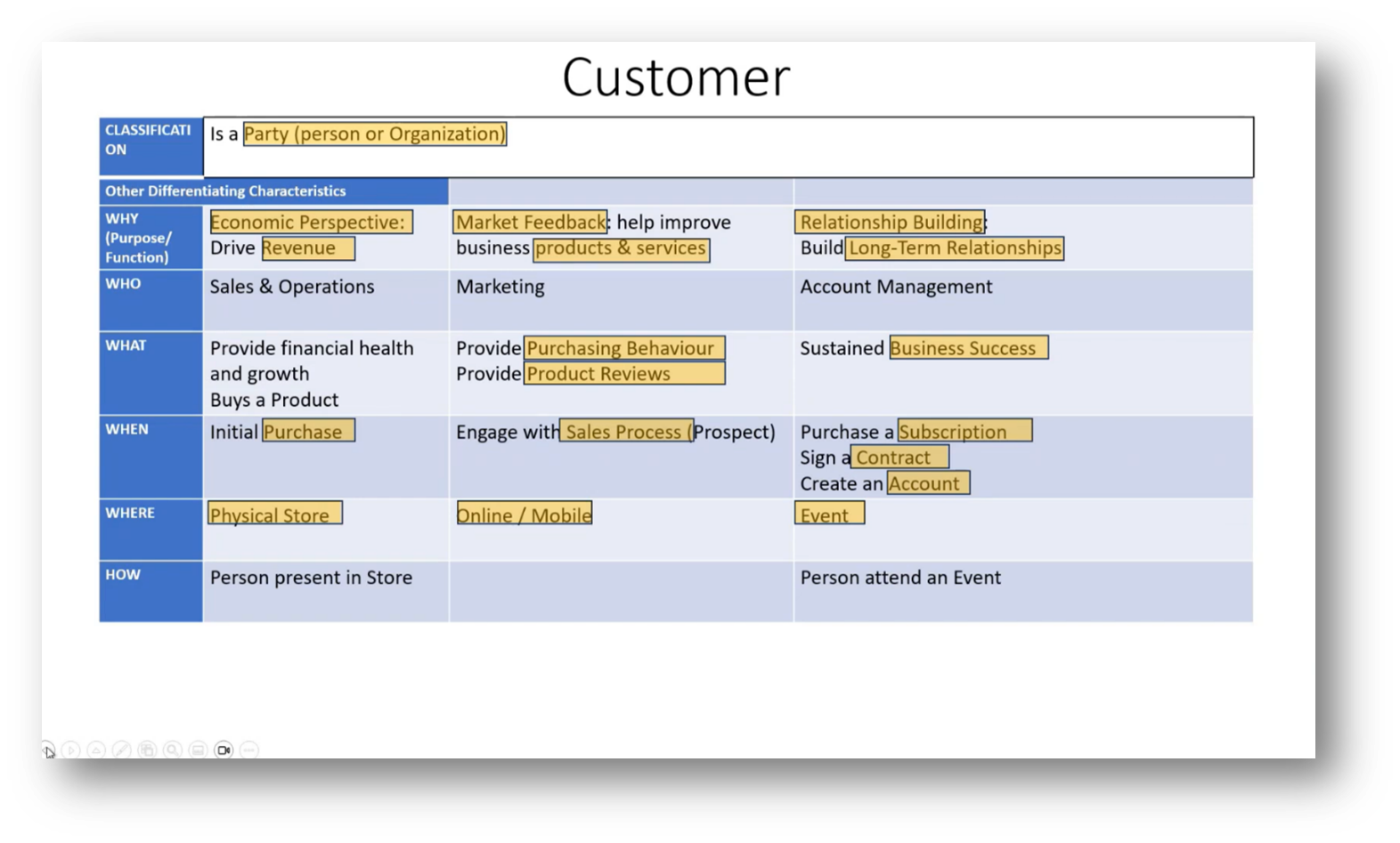
Figure 12 Breaking Apart the Definition

Figure 13 Customer Related Terms
Challenges of Implementing Enterprise Data Models
The challenges and time-consuming nature of developing an Enterprise Data Model is highlighted. An attendee reflects on their experience, which took approximately 18 months to establish nine basic concepts and various entities, underscoring the importance of achieving consensus on definitions to facilitate progress. This discussion points out the complexities that arise from differing terminologies. Despite these challenges, there is significant value gained from the effort invested in creating a well-defined model, prompting considerations about the depth of exploration necessary in future developments.
Master Data Management and Terminology
Two more attendees voice their experienced challenges surrounding master data terminology, highlighting the difficulties in achieving consensus across different business entities. One notes that while progress has been made in standardising key terms, discrepancies still exist, particularly in areas affected by diverse legislative requirements, complicating the aggregation of data for reporting. The other emphasises the importance of aligning organisational structures to improve reporting outcomes, while acknowledging the need for flexibility in accommodating regional definitions. Lastly, nuanced differences in terminology could lead to misunderstandings, especially among stakeholders from various regions, such as South Africa and Switzerland.
Business Rule Manifesto and its Application in Data Modelling
An attendee recounts a conference in Nashville in the early 2000s where Ronald Ross discussed the business rule manifesto, emphasising the importance of defining business rules as terms, facts, and constraints before creating a data model. They then highlight how extracting these terms helps identify relationships among them. Howard shares that this approach resonates with the work of Mark Atkins and Terry Smith, who categorised inquiries into six key elements: why, what, when, how, and where, treating each as a rule. This iterative process of agreement on statements leads to the identification of additional terms, prompting questions about the sufficiency of the analysis and determining when to conclude the process.

Figure 14 A Structured Approach to Dissecting a Definition
Approaches in Data Modelling and Standardization
The progression from business language to a detailed data model is emphasised. Howard then highlights the importance of precise definitions, business rules, relationships, and attributes. He addresses the need for taxonomy to better understand classifications and hierarchies, including the rules for navigating these. Transitioning to ontologies adds complexity through relationships and reasoning, which culminates in knowledge graphs that reveal discrepancies between various models, enabling identification of misalignments. This is critical for effective integration in data warehouses, as evidenced by past challenges in consolidation efforts. The speaker notes a desire to leverage ontology principles to enhance the accuracy of outputs from large language models (LLMs), particularly as their organisation struggles with internal consistency. The ultimate goal is to foster a more coherent enterprise definition while managing the inherent discrepancies within data-driven recommendations.
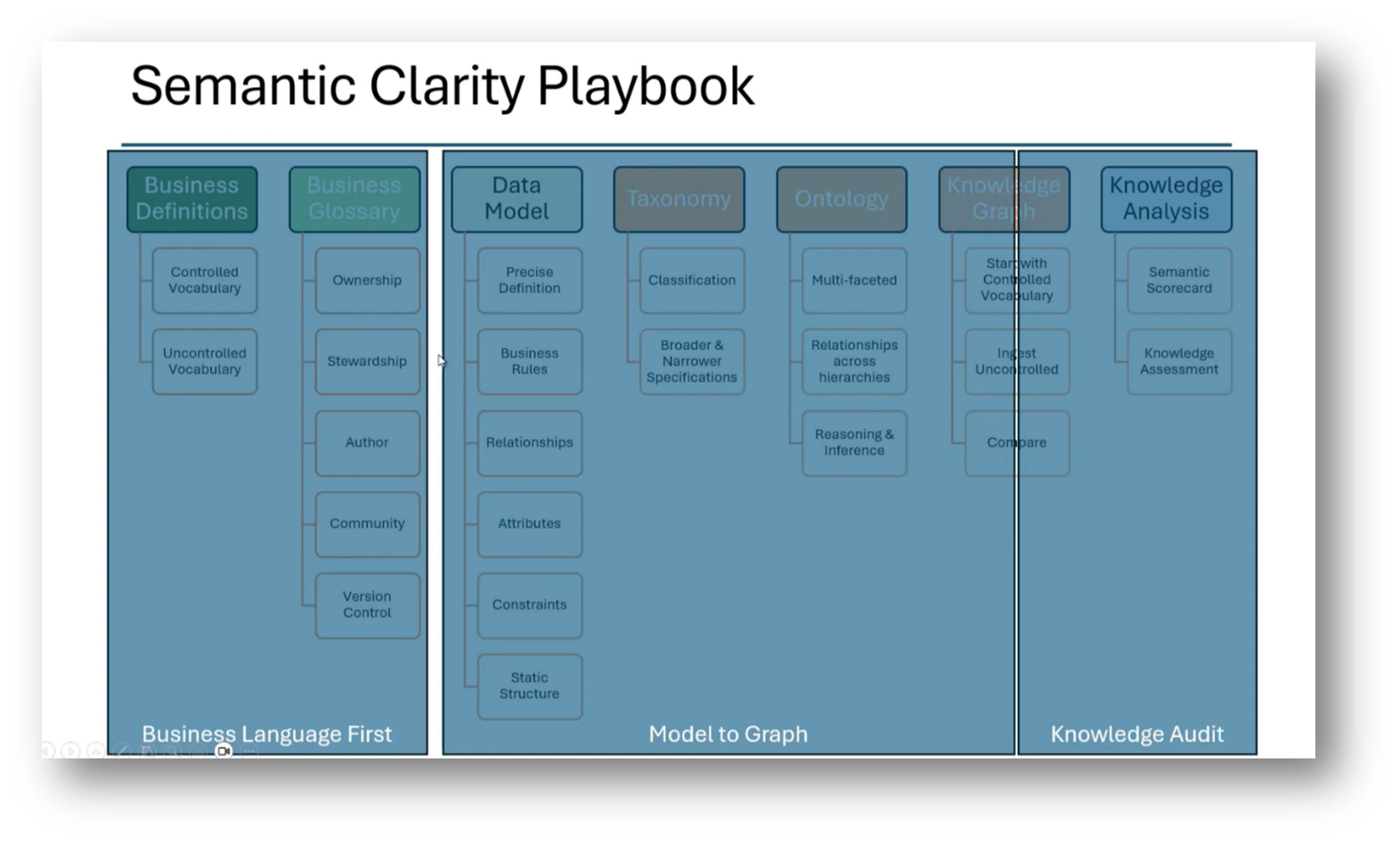
Figure 15 Semantic Clarity Playbook
Understanding Definition Management
Definition management, a term introduced recently in discussions around term life cycle management, focuses on the discovery, management, and harmonisation of various definitions for terms used within different units or at different data levels. It encompasses not only the agreement on common definitions but also understanding differences and changes due to factors like regulations.
The distinction between term and definition management arises in that while term management primarily deals with managing sets of business terms and their usage, definition management pertains specifically to the various definitions of those terms. This broader concept includes aspects such as quality characteristics of definitions, team management, and procedural workflows, highlighting the complexity of managing terms and definitions effectively.
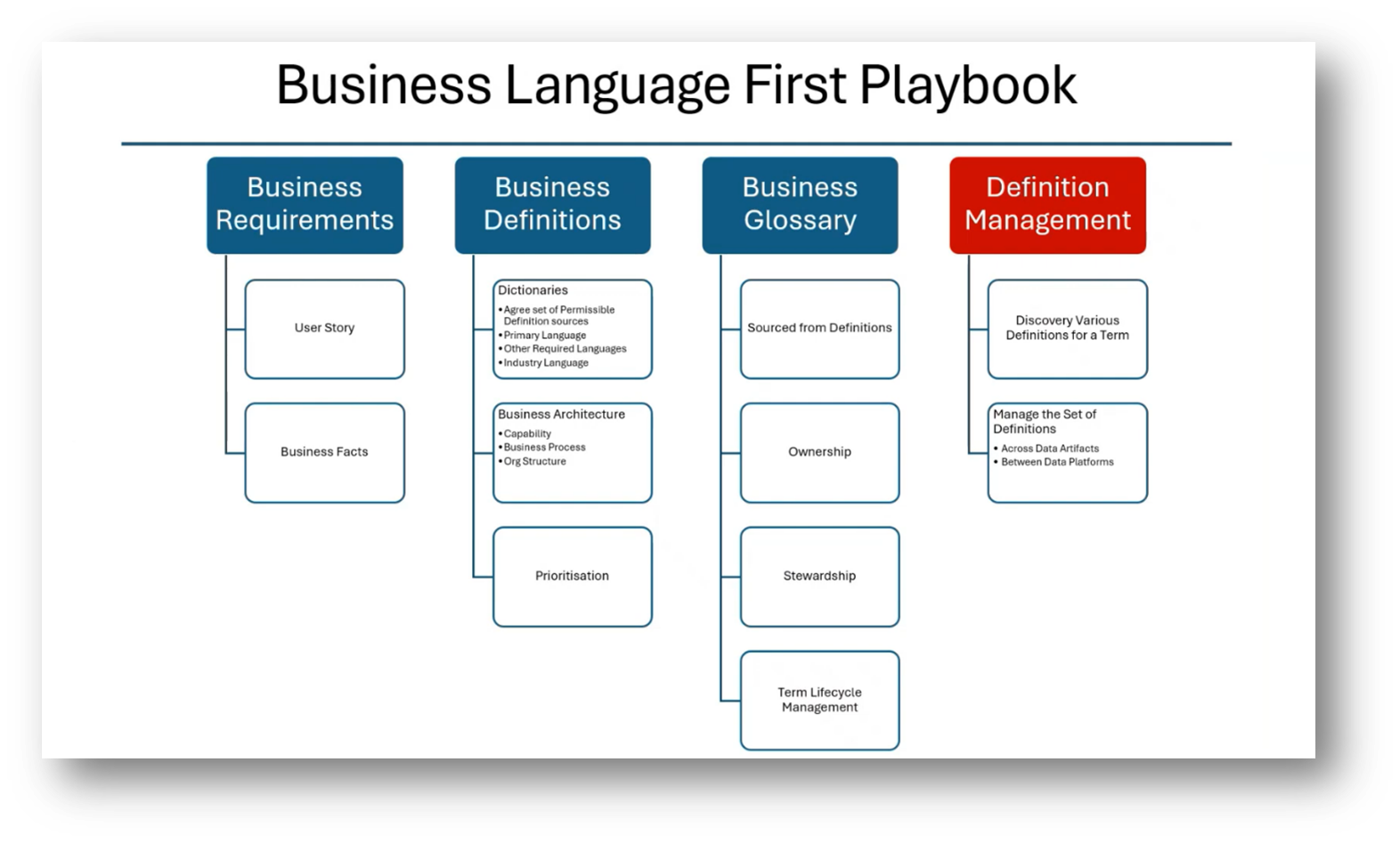
Figure 16 Business Language First Playbook
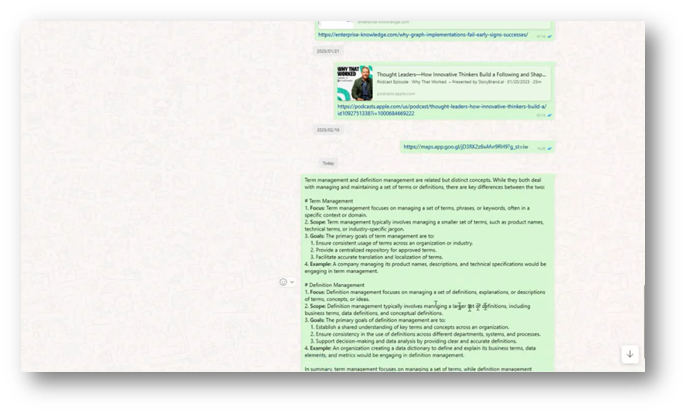
Figure 17 Definition or Term Management and Definition Management
UML and Object-Oriented Modelling in Data Modelling
Howard discusses the progression from conceptual to logical data modelling using UML, highlighting its ability to add various constructs that enhance the understanding of entities and classes. He draws from his experience as a DBA and notes the contrasts between data models and object-oriented class models, especially concerning super types and subtypes, which can be implemented seamlessly in class models without the complications present in physical data models.
The class model supports abstraction and categorisation, leading to a more powerful framework compared to traditional data models. Ultimately, this progression facilitates the transition from class models to ontologies, enriching the data model with additional meaning and insights.
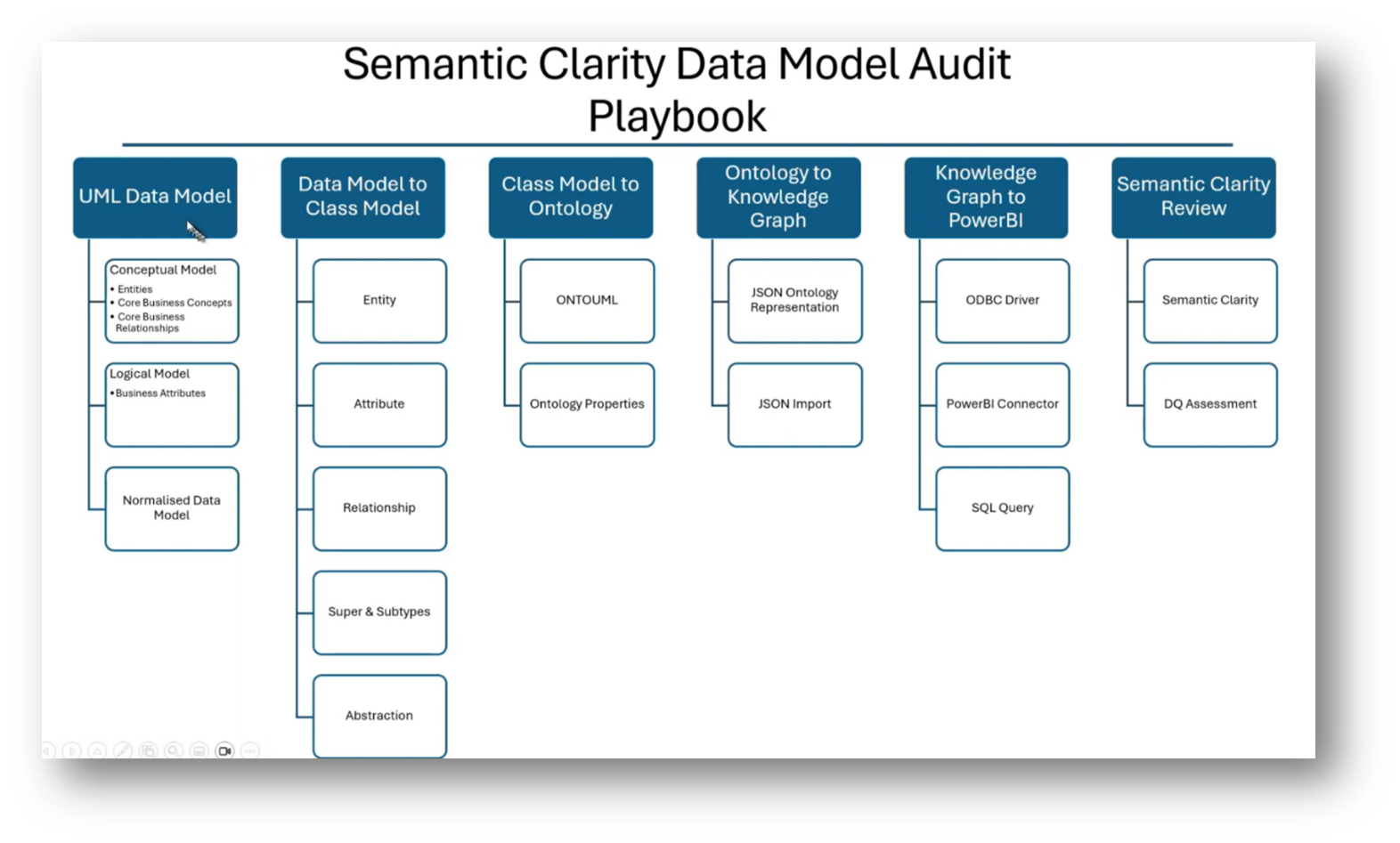
Figure 18 Semantic Clarity Data Model Audit Playbook
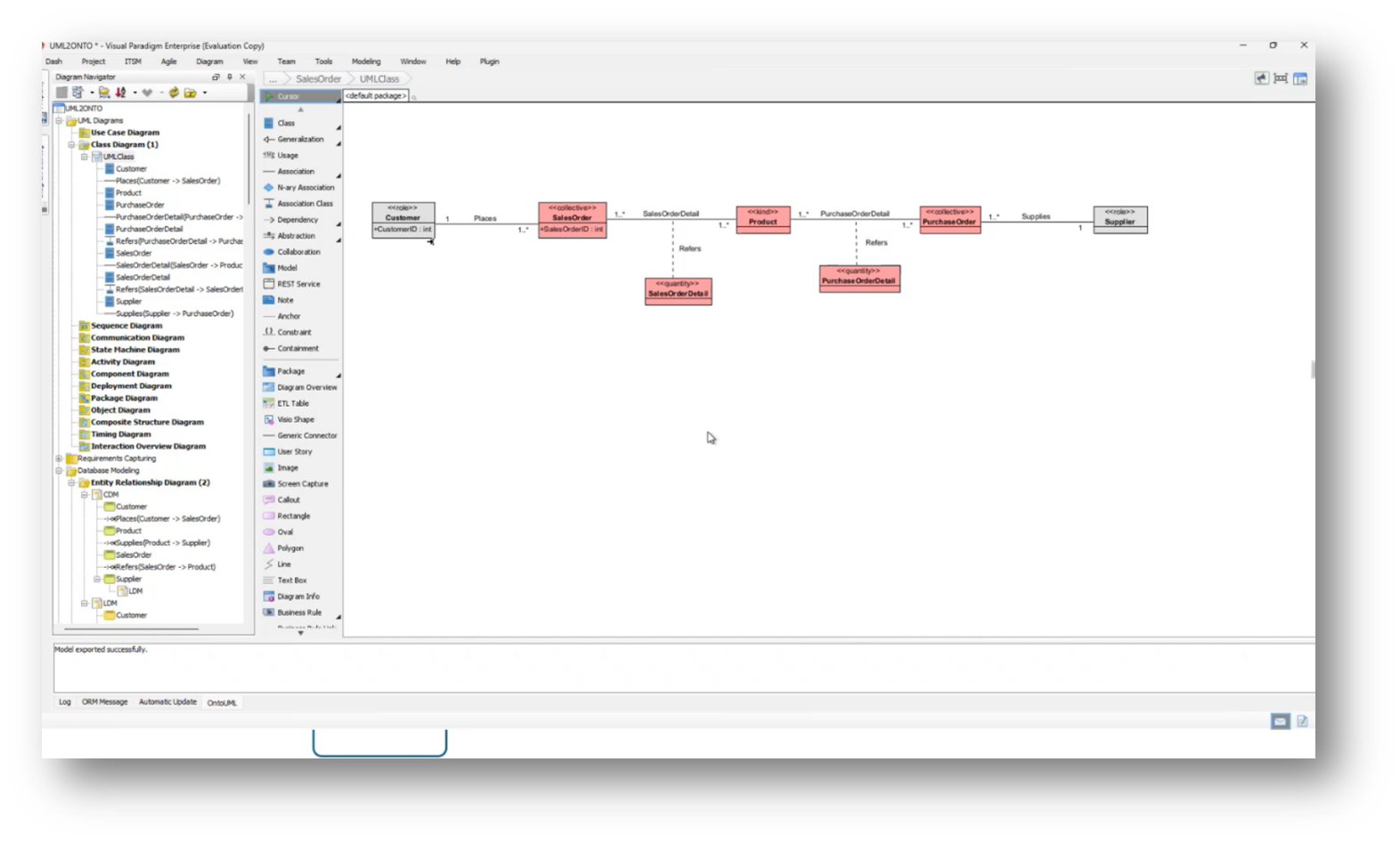
Figure 19 Class Diagram
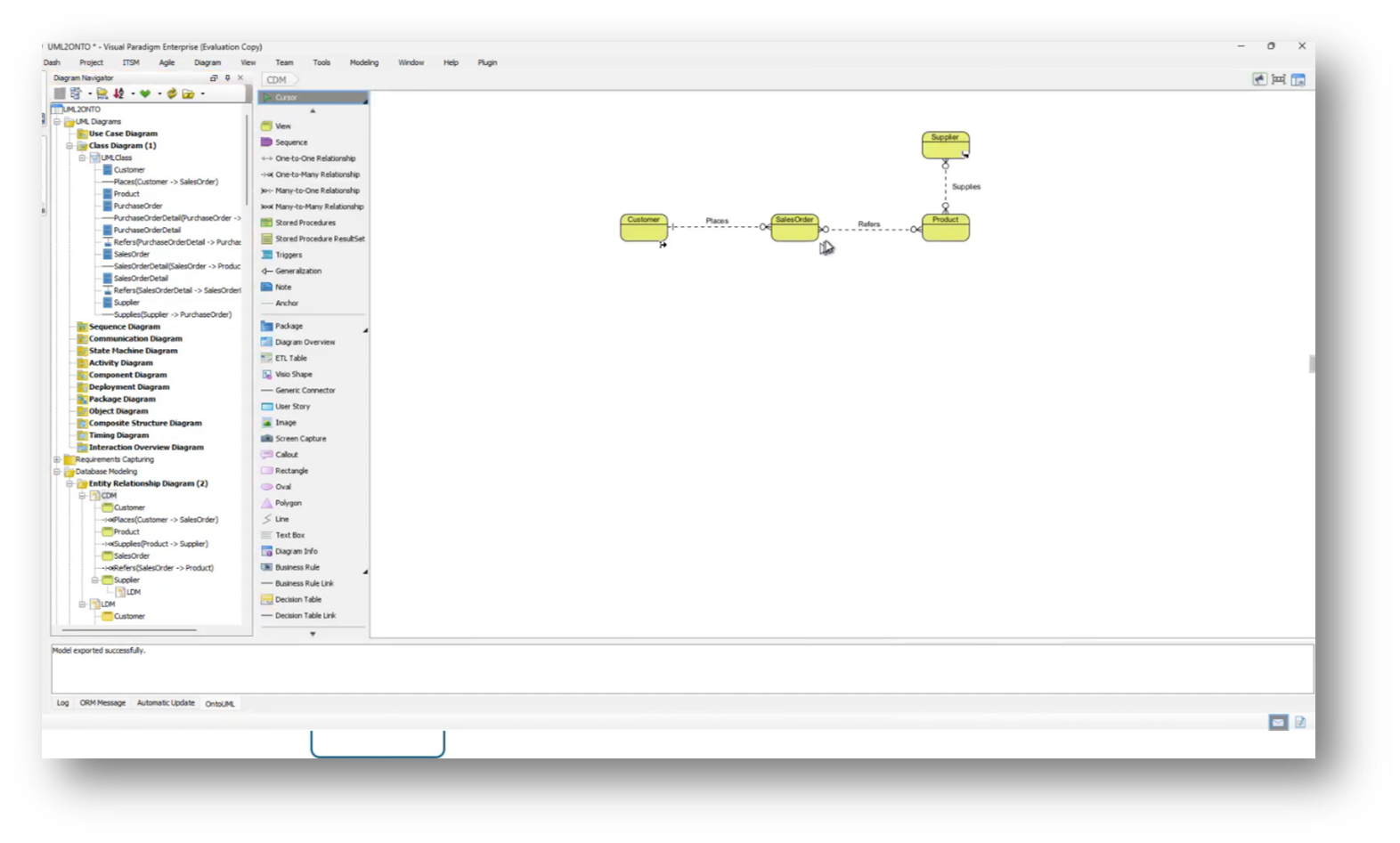
Figure 20 Conceptual Data Model
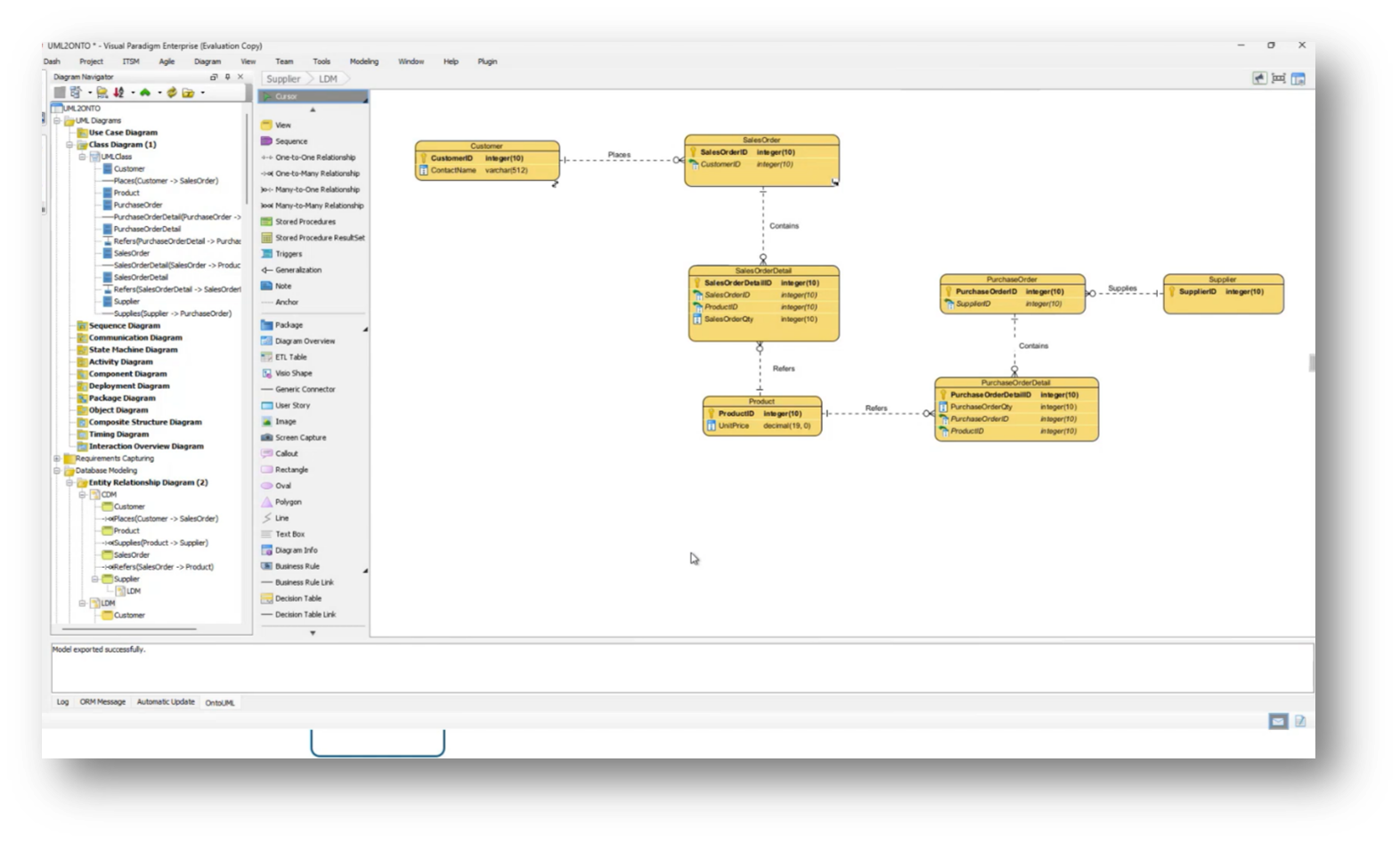
Figure 21 Logical Data Model
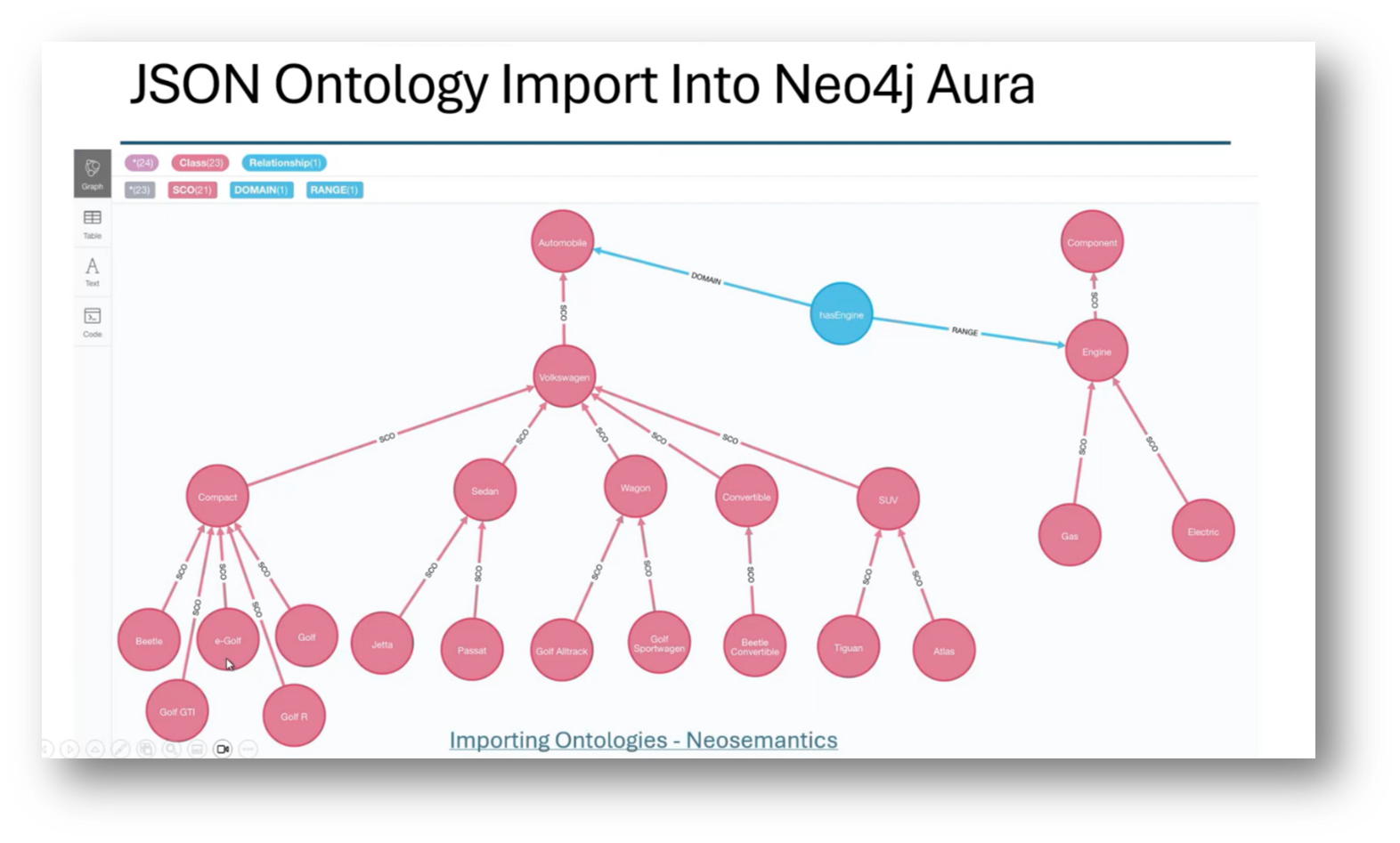
Figure 22 JSON Ontology Import Into Neo4j Aura
Challenges in Balancing Data Models and UML Class Models
The data model and the UML class model often do not align, particularly when comparing a normalised data model, which typically contains fewer tables than the number of entities represented in UML. A successful approach to bridging this gap involves utilising association classes, which provide details about specific relationships, such as linking products to sales and purchase orders.
While the conceptual model can accommodate many-to-many relationships, transitioning to a logical data model necessitates normalisation to achieve an appropriate physical design. Challenges arise, especially with super types and subtypes, where a single database table might represent multiple classes in UML, highlighting the misalignment between the two modelling approaches.
Using an RDF-based ontology and knowledge graph for managing taxonomy structures over traditional relational databases presents advantages. Howard highlights how representing hierarchies, including subtypes and supertypes within the automobile taxonomy, can be efficiently achieved through graph databases, which allow for easier management and cross-mapping of information. He then touches on the challenges of translating these hierarchical structures into physical data models, emphasising that constraints often drive the transformation from information models to data models. Additionally, it notes the flexibility of UML class models in accommodating taxonomy structures and defining relationships between broader and narrower terms, contrasting this with the rigidity of physical data models.

Figure 23 “Semantic Clarity Data Model Audit Playbook”
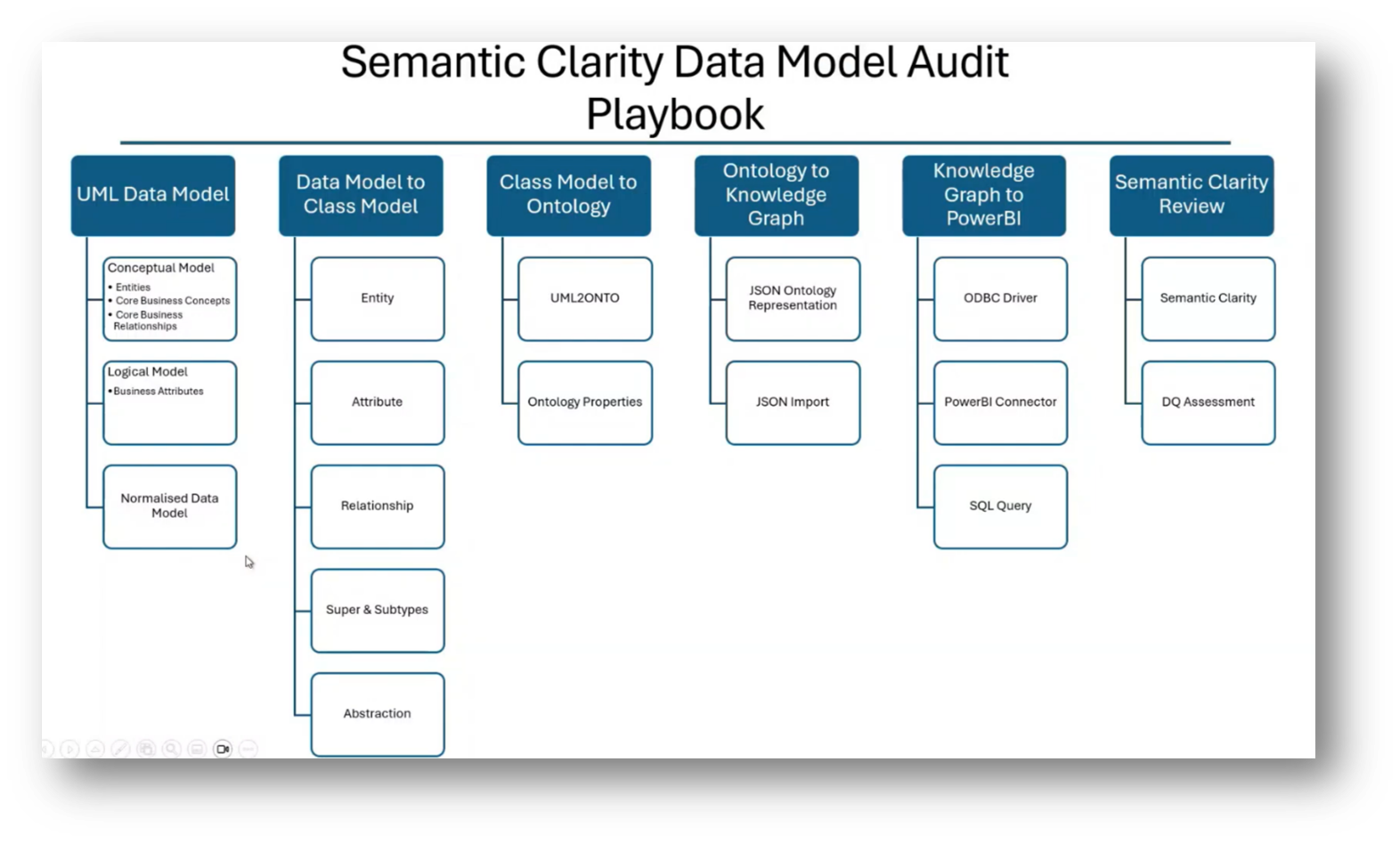
Figure 24 Semantic Clarity Data Model Audit Playbook Diagram
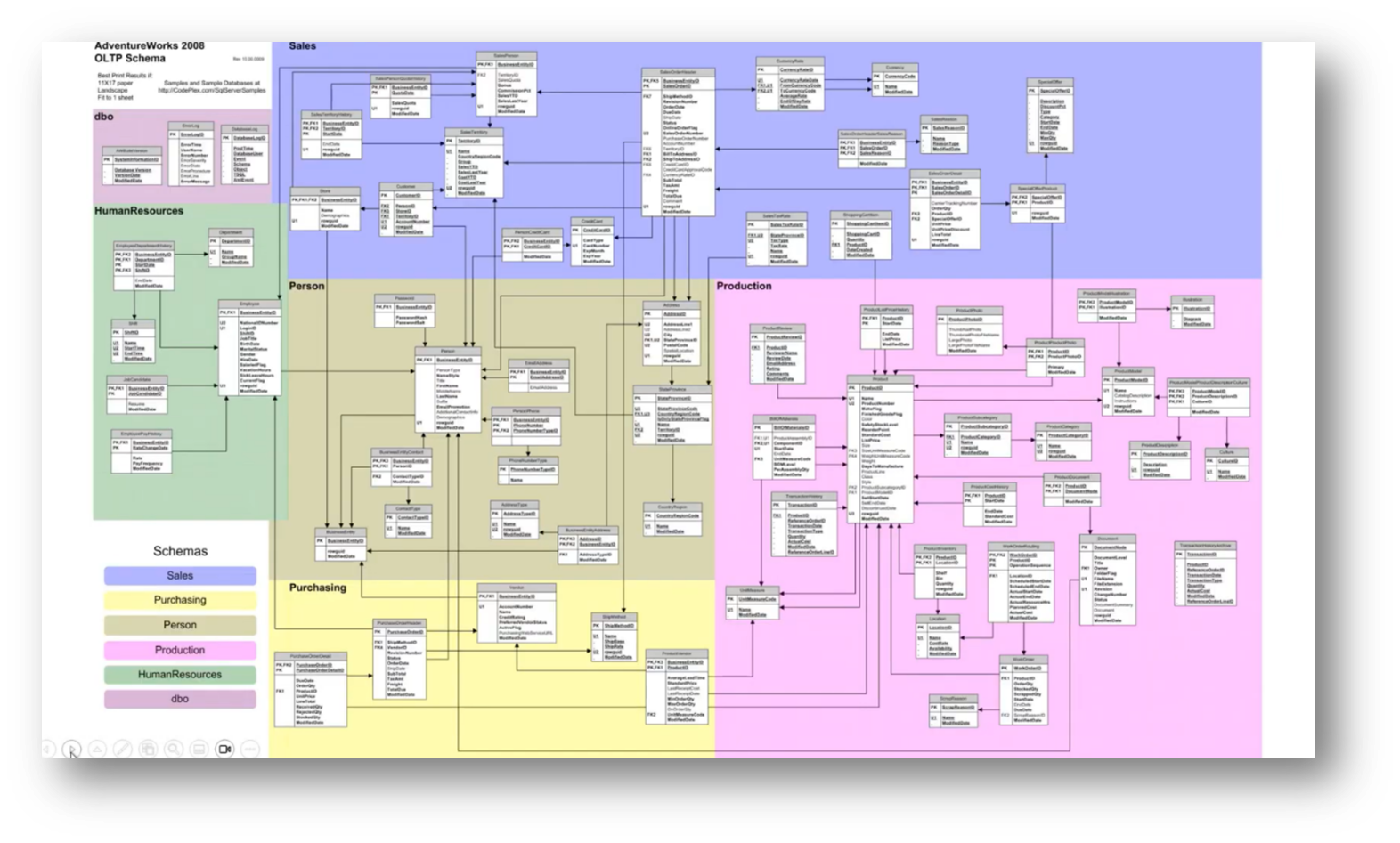
Figure 25 Enterprise Data Model
Using UML and Knowledge Graphs in Enterprise Data Model and Local Data Analysis
The technique employed involves creating a UML data model that progresses through conceptual, logical, and normalised stages before mapping to a class model. From the class model, it transitions into an ontology and ultimately exports into a knowledge graph. This process enables comparison between the Enterprise Data Model, exemplified by the Adventureworks database, and localised departmental models, identifying differences in semantics.
The enterprise model is complex, utilising a party model that includes various business entities like vendors and customers. By analysing and comparing the two models within the knowledge graph, discrepancies in relationships, such as those between sales orders and customers, can be readily identified.
Figure 26 Neo4j Aura
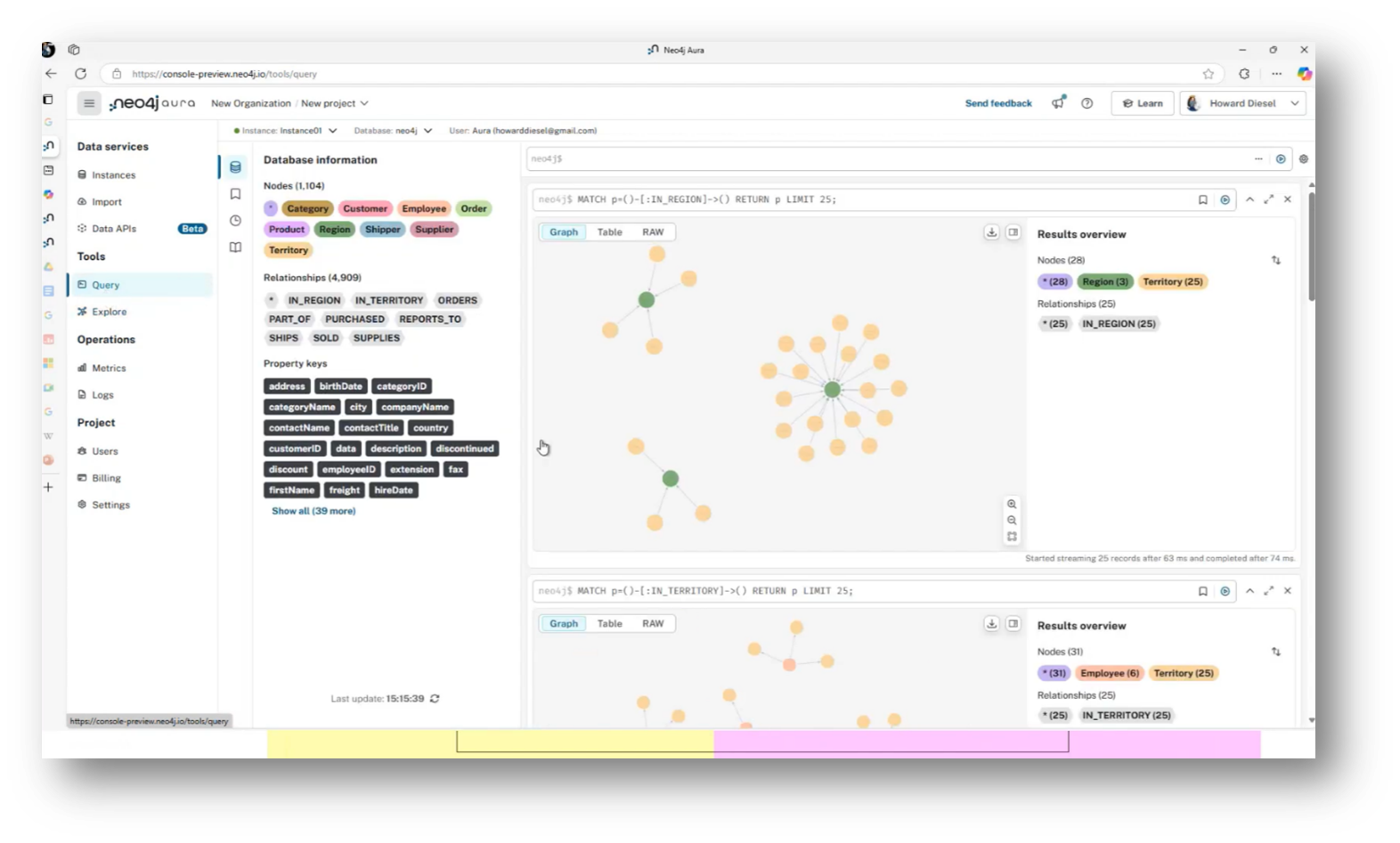
Figure 27 Database Information
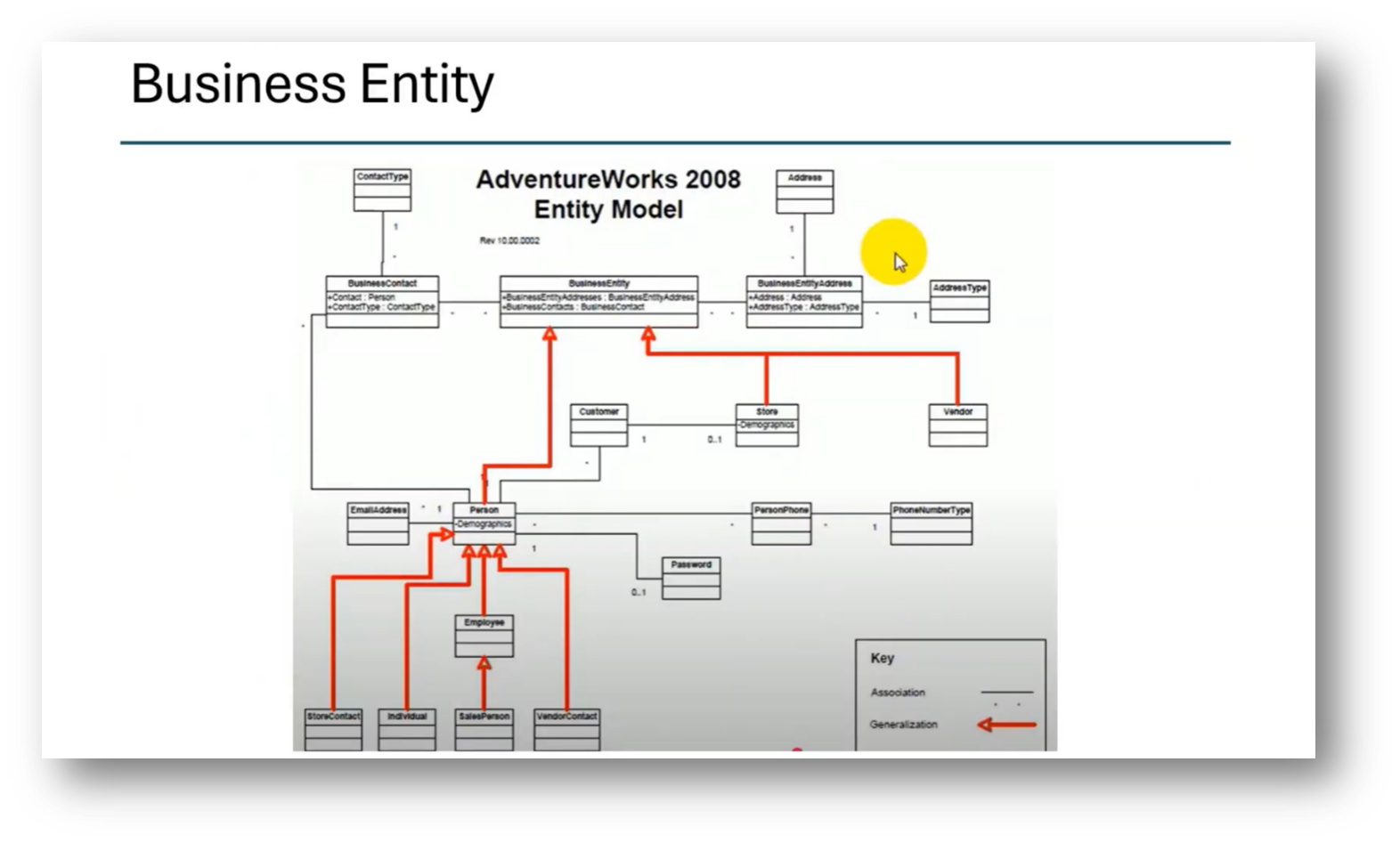
Figure 28 Business Entity
Implementing Knowledge Graph Systems
The process of developing a knowledge graph begins with utilising a graph database to explore entities and their relationships, such as understanding how a region relates to a territory and subsequently to customers and orders. By analysing these relationships, discrepancies between the knowledge graph and the Enterprise Data Model can be identified. Initially, a high-level conceptual model is created using UML, which is then translated into a logical data model. This logical model leads to a physical data model, ensuring careful consideration of associations, navigability, multiplicity, inheritance, and abstraction so that the final UML class model can be refined, documented, and effectively integrated into the knowledge graph system.
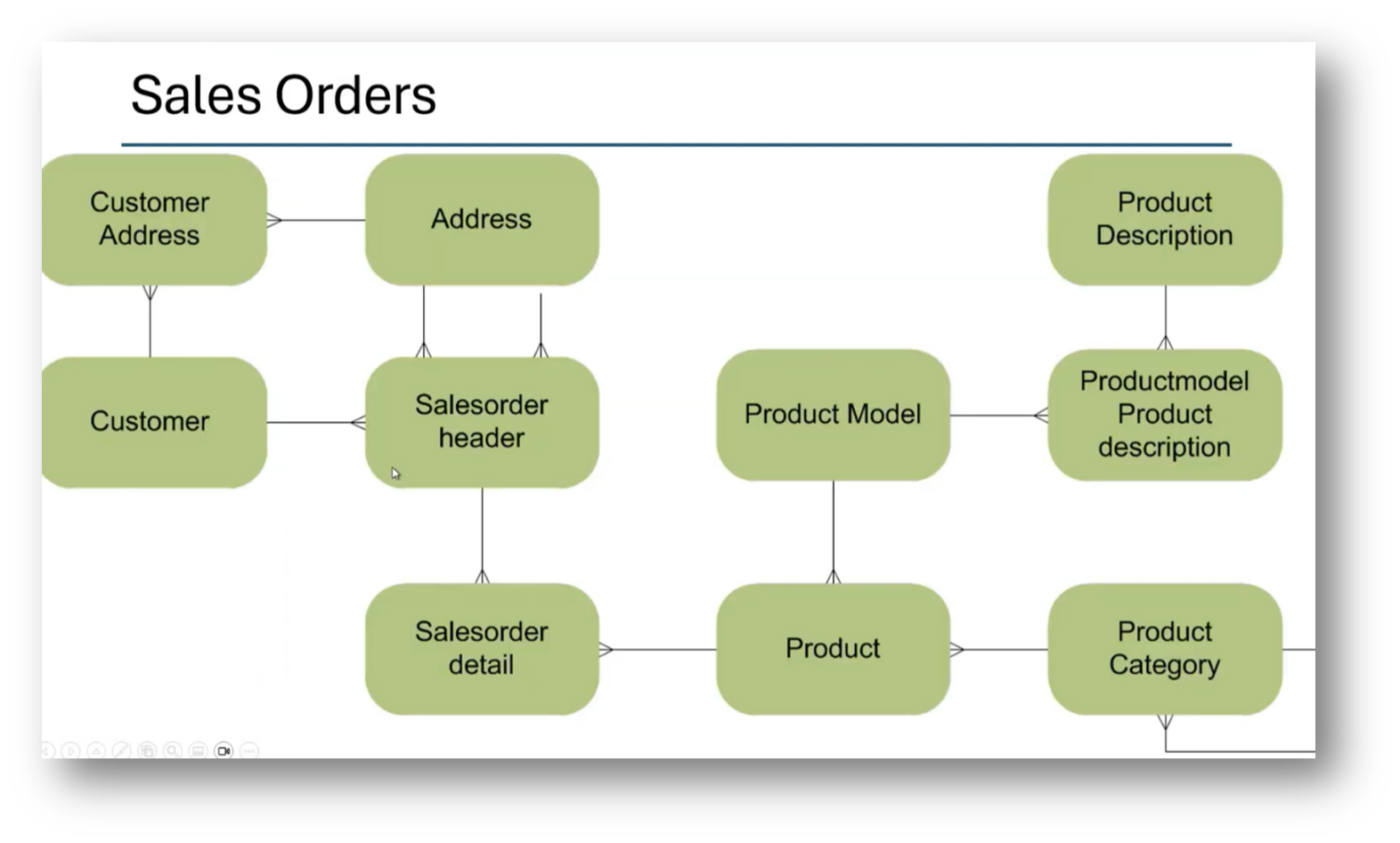
Figure 29 Sales Orders
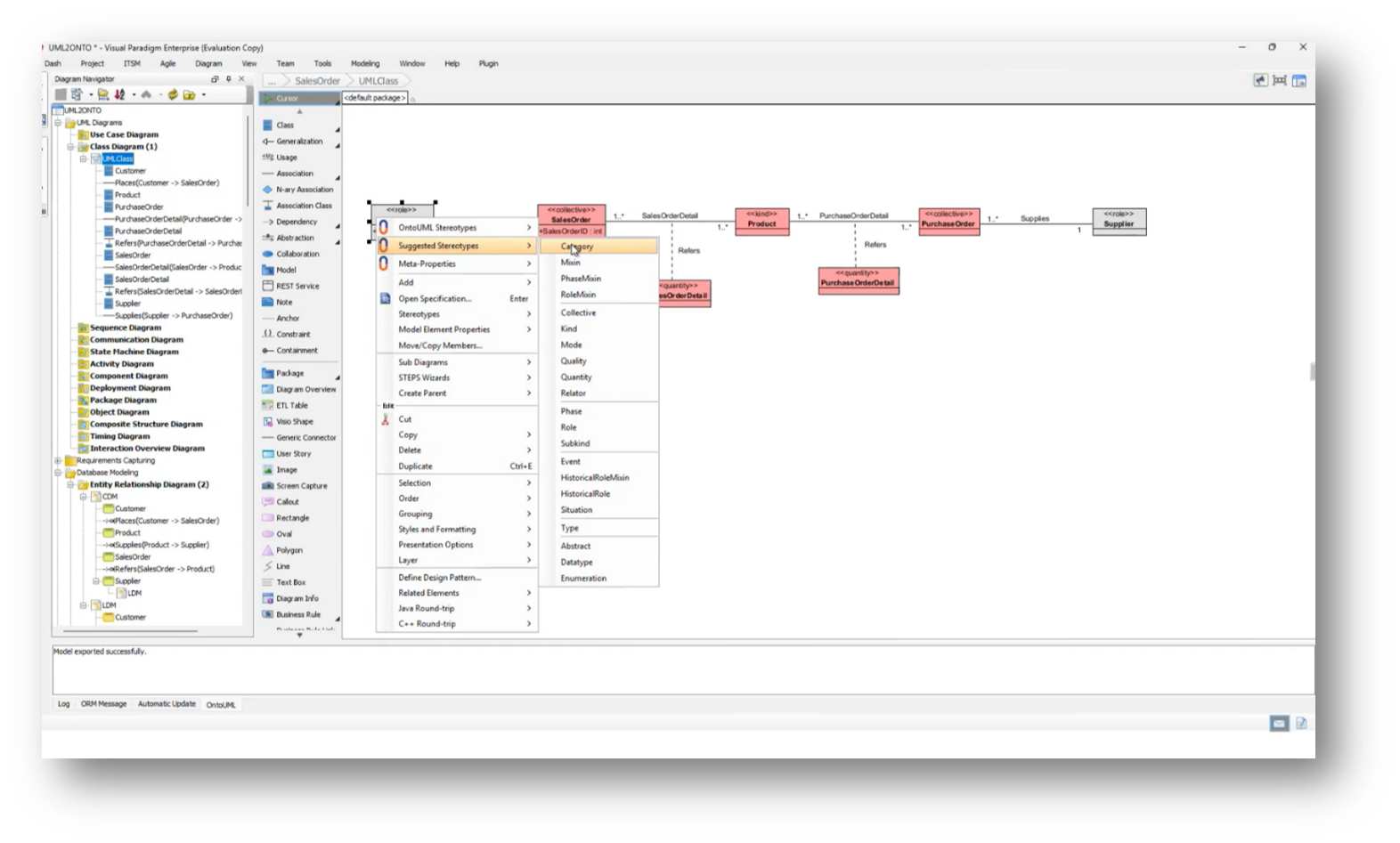
Figure 30 Stereotyping Class Diagram
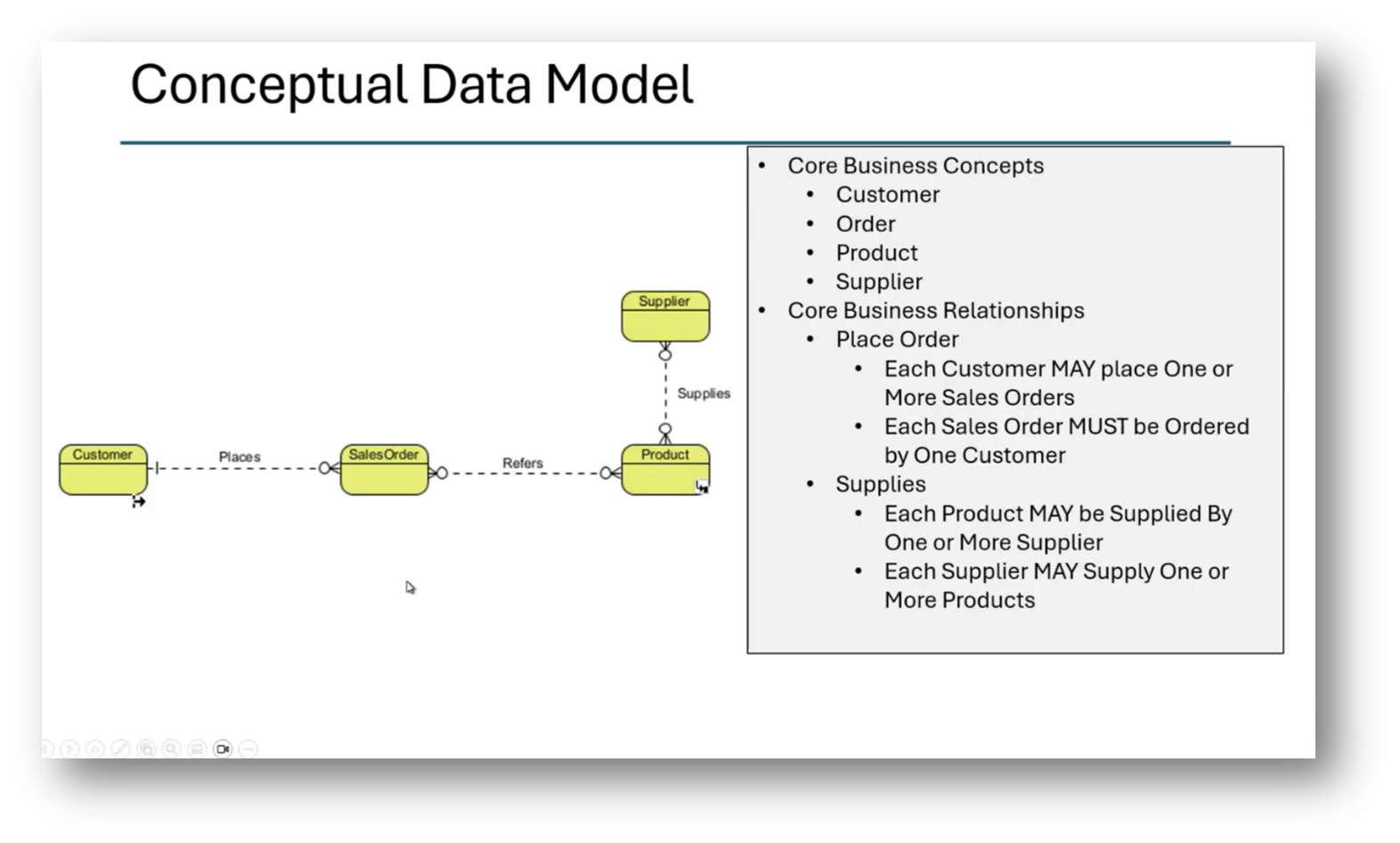
Figure 31 Conceptual Data Model
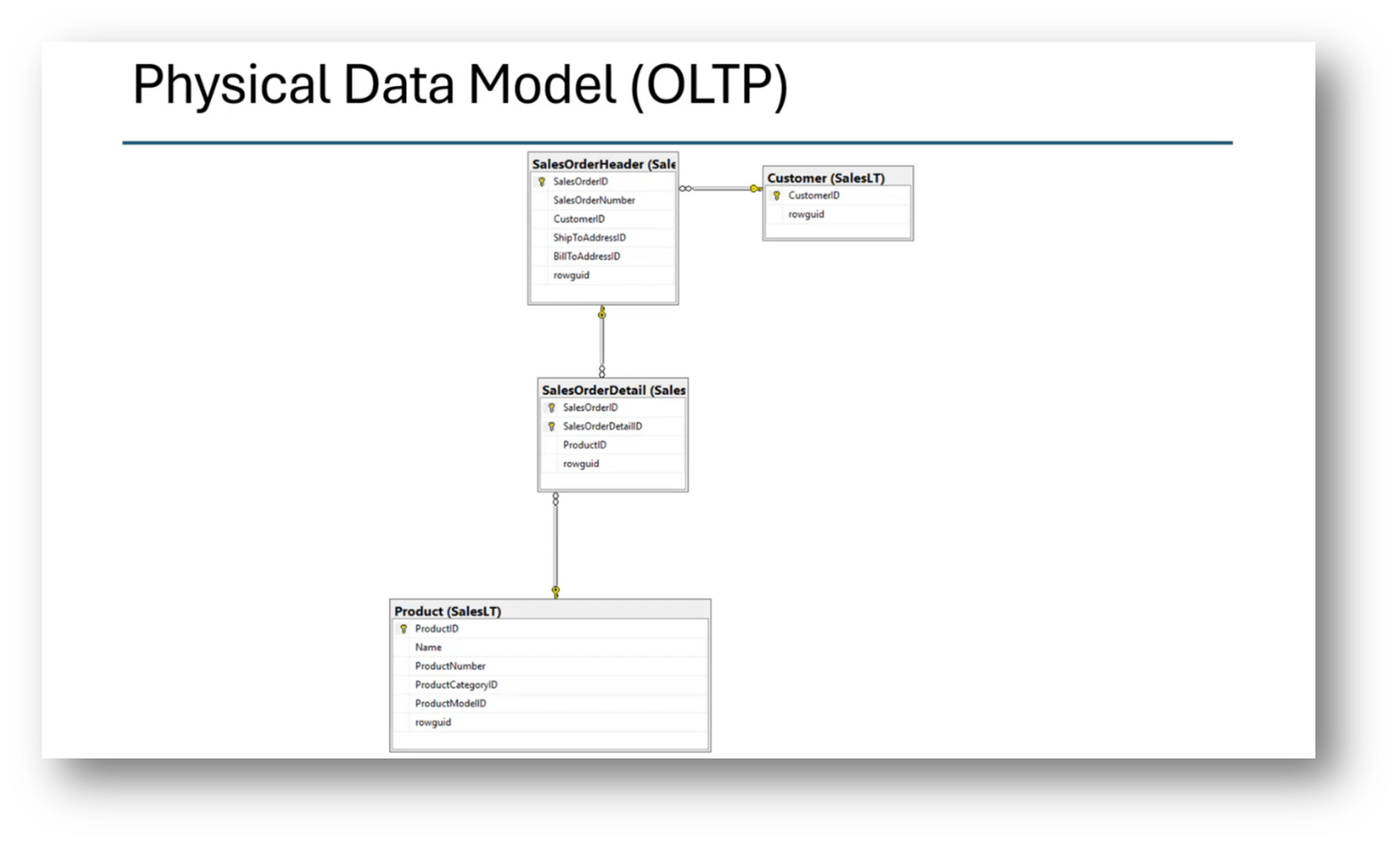
Figure 32 Physical Data Model (OLTP)
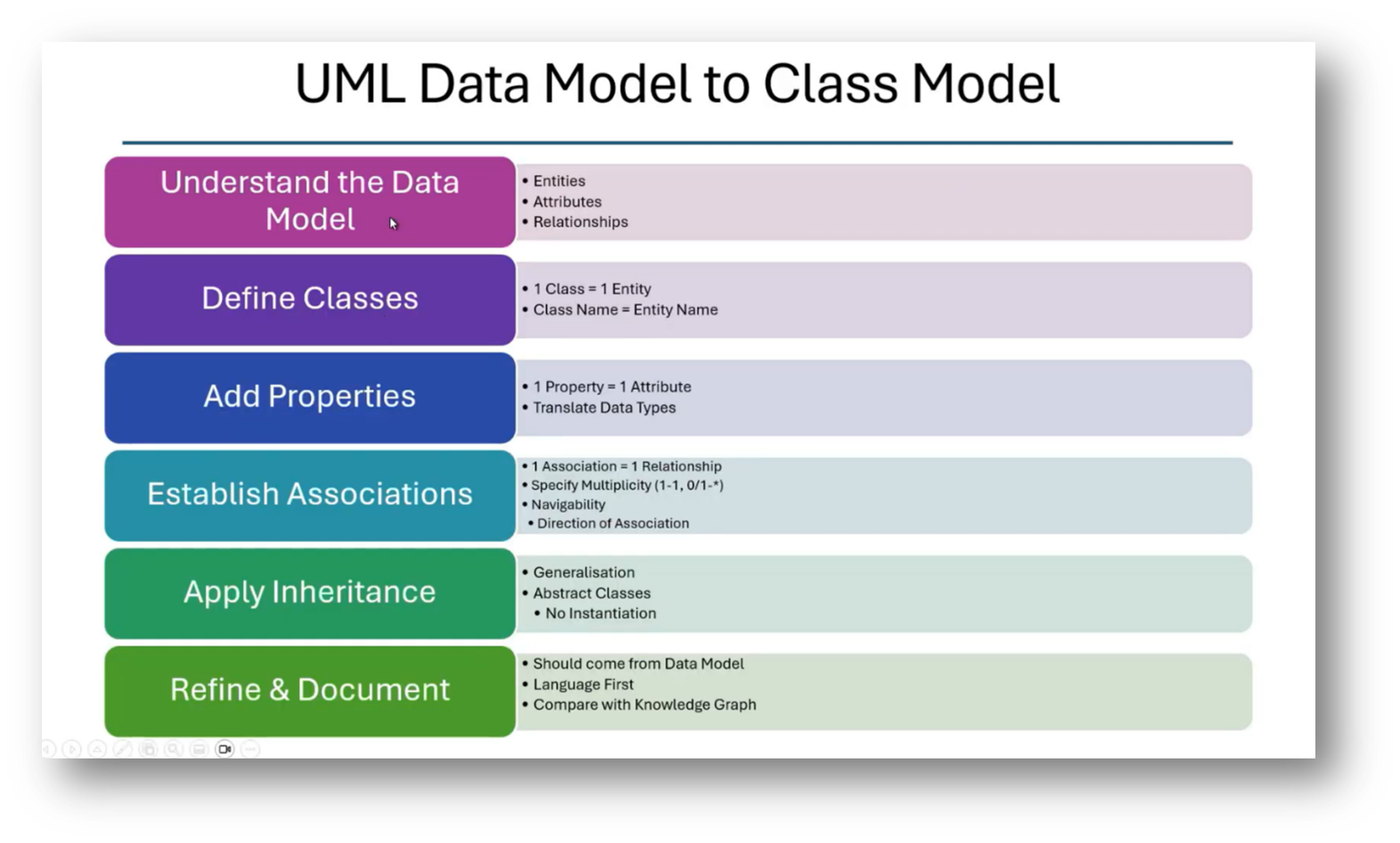
Figure 33 UML Data Model to Class Model
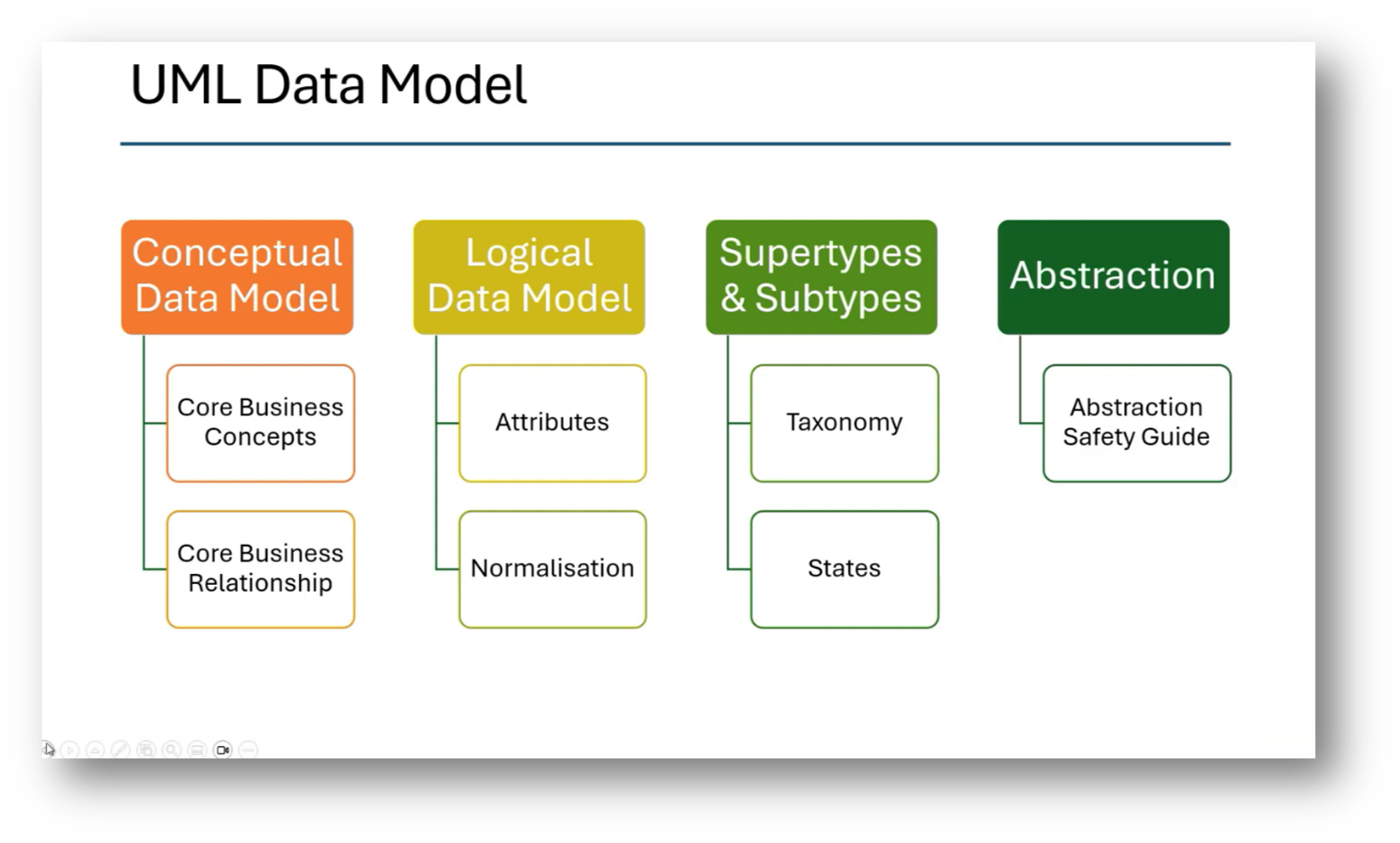
Figure 34 UML Data Model
Integration of Business Definitions and Enterprise Data Models
An attendee expresses difficulty in understanding how business input aligns with the data models discussed, specifically referencing the Adventure Works example. They emphasise that the starting point for building a robust data model should originate from clear business definitions, rather than solely relying on data sources. Howard suggests that aligning with business terminology is essential, highlighting a lack of contextual relevance when terms like "parties" are used. He then propose a structured approach where semantic clarity is derived from business glossaries, leading to the development of an Enterprise Data Model. The goal is to compare this enterprise model with specific implementations to identify semantic differences, reinforcing the necessity of established business definitions before creating an Enterprise Data Model.
Aligning Enterprise Data Models with individual data models to ensure semantic clarity and consistency within an organisation is imperative. Howard goes on to share more about the challenges faced when attempting to automate the evaluation process, utilising concepts like the data model scorecard, which emphasises alignment with the Enterprise Data Model. The goal is to develop a technique that integrates various data models into a knowledge graph, enabling comparisons between the enterprise ontology and the individual data models. This approach aims to streamline the auditing process and enhance data governance by identifying discrepancies between different data instantiations.
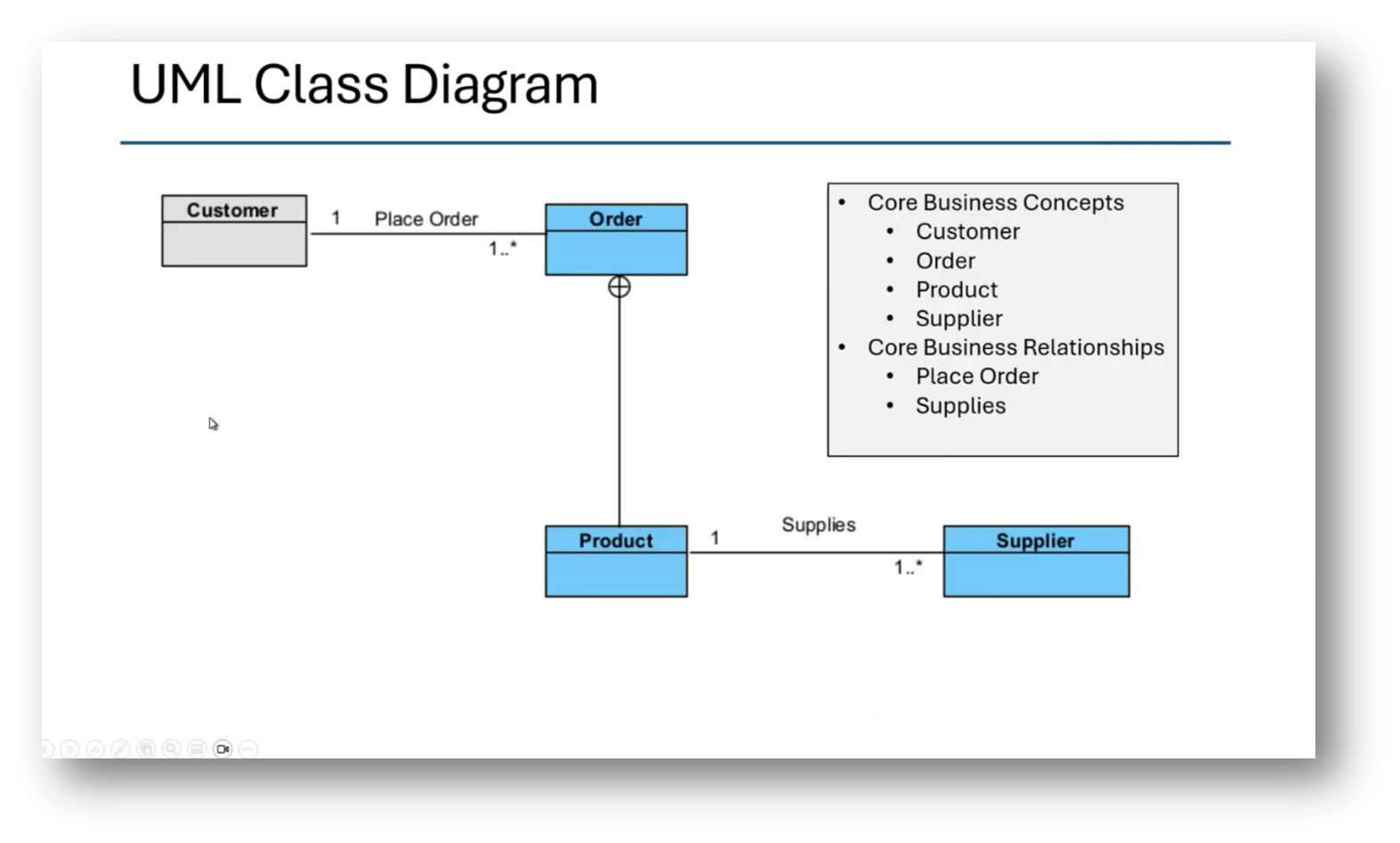
Figure 35 UML Class Diagram
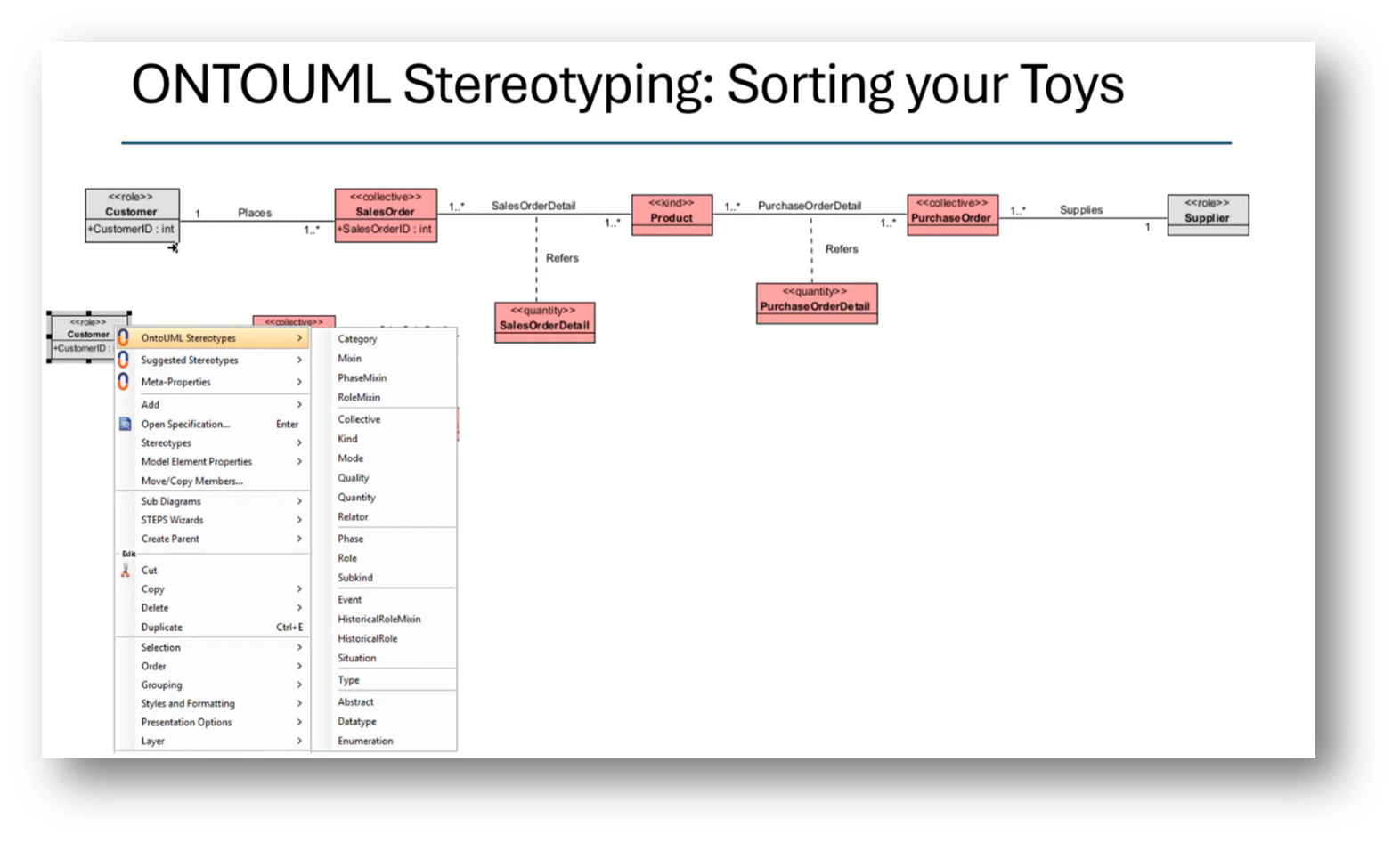
Figure 36 ONTOUML Stereotyping

Figure 37 UMLONTO JSON Exports
Process of Transforming a Conceptual Model into a Logical Data Model
The process involves transforming a conceptual model into a logical, normalised format, and then representing it as a UML class diagram. From this UML diagram, ontology stereotypes and properties are applied, augmenting the UML class model. A JSON document is generated from this model, providing a detailed representation of the data structure necessary for integration into a knowledge graph, allowing for comparisons with the existing Enterprise Data Model. This process facilitates the assessment of semantic clarity in the data model, incorporating various elements such as customer ID, sales orders, and product attributes. While there may be questions about specific steps or clarity, the overall workflow aims to create an effective alignment between the data model and the enterprise ontology.
Howard outlines the challenges faced by architects in building data products, particularly in reviewing and aligning data models with Enterprise Data Models. He notes that he has been manually conducting these reviews for five years and aims to automate the process using ontologies and knowledge graphs to identify misrepresentations and new insights. While acknowledging the value in Steve Hoberman’s business-first approach and his abstract, generalised methods, the speaker expresses a preference for a more concrete perspective. Additionally, Howard mentions their development of a data modelling tool leveraging GPT technology to analyse legacy systems and extract meaningful metadata. Despite recognising a disconnect in fully understanding the integration of these concepts, they remain open to further exploration and learning, indicating a willingness to reflect on these ideas during an upcoming long flight to Australia.
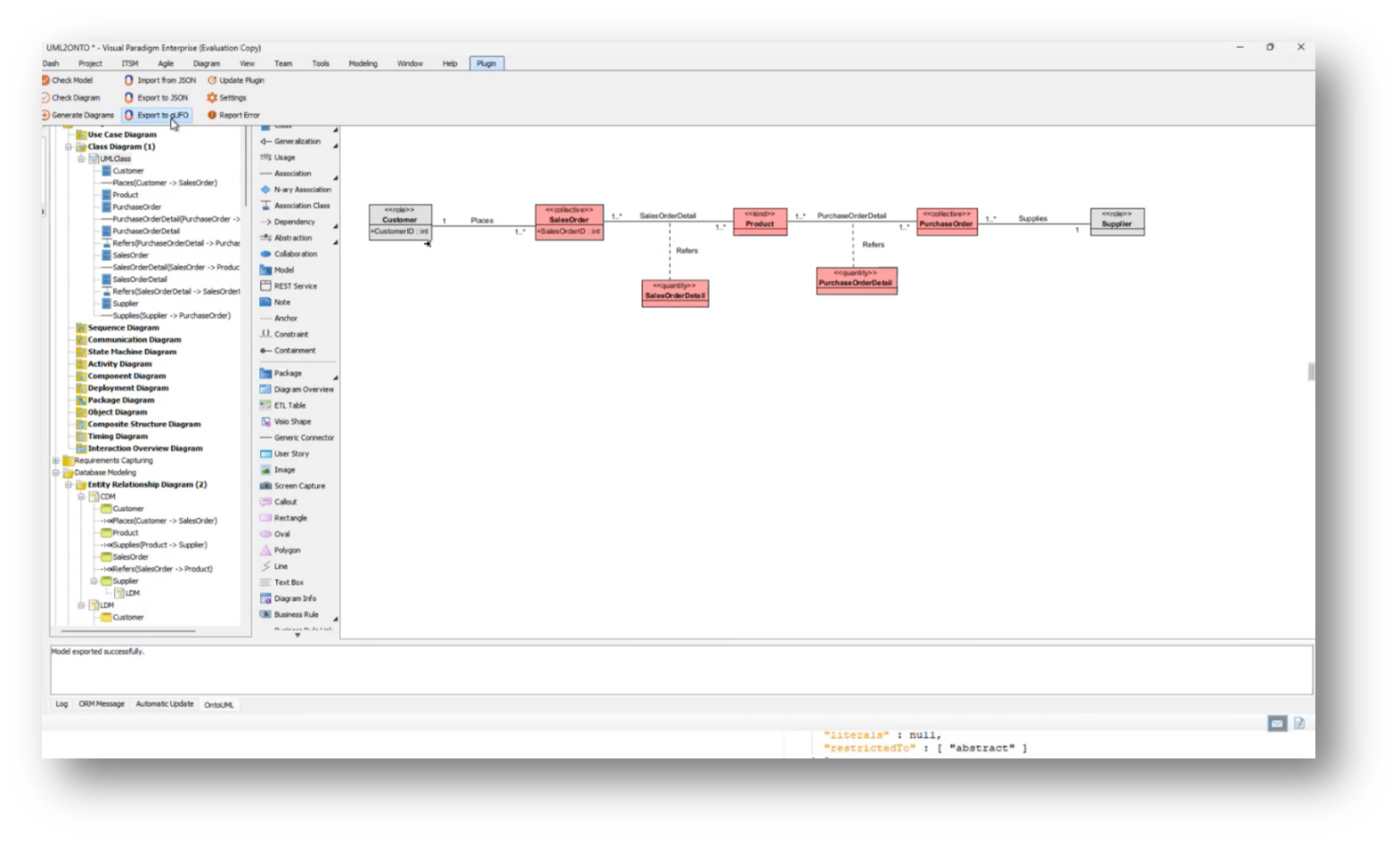
Figure 38 Class Diagram
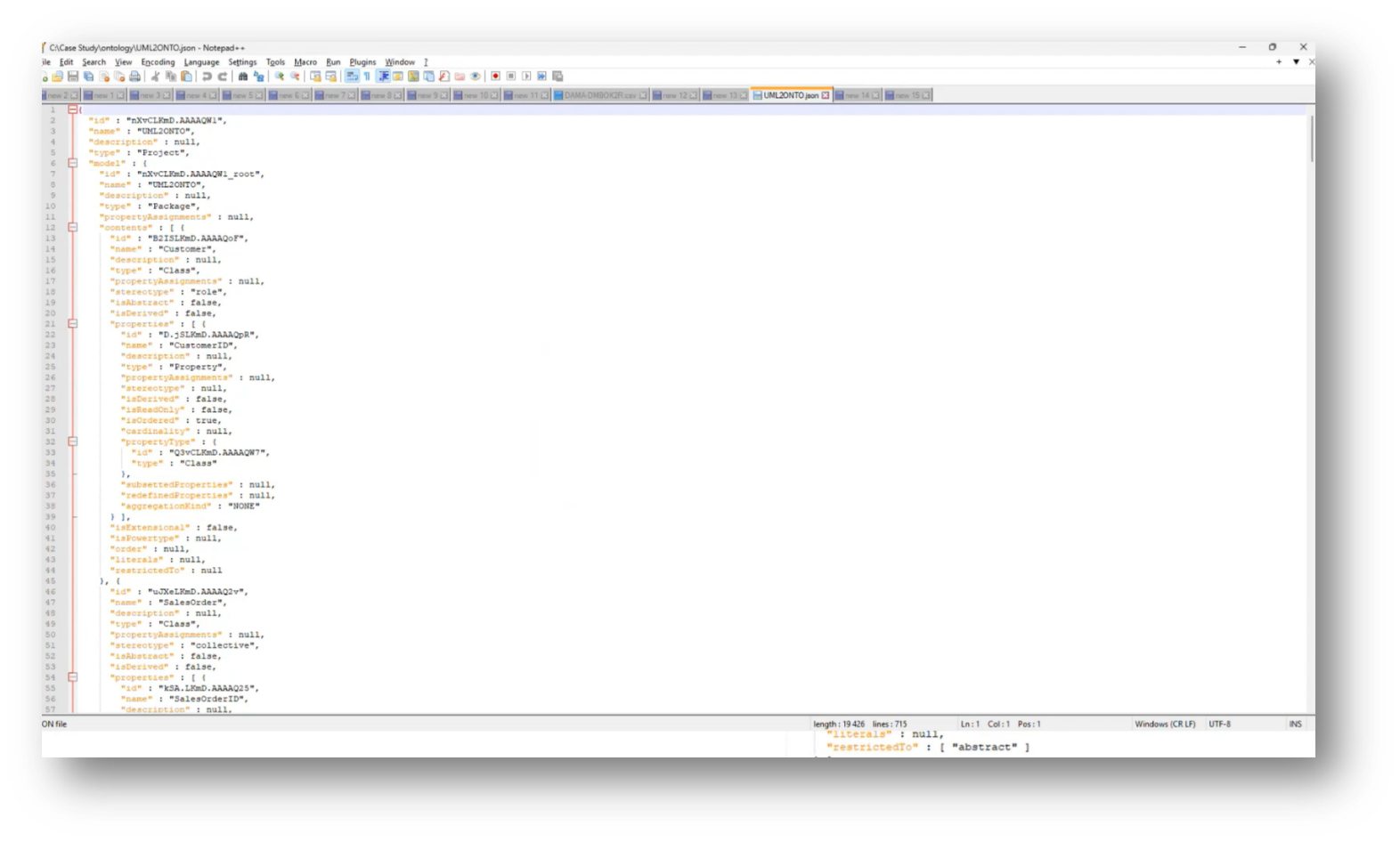
Figure 39 JSON Export
The Implications of Abstraction in Academic Discussion
Howard shares previously shared advice that one may avoid the potential pitfalls of abstraction by employing it only when necessary. As outlined in Steve Hoberman’s Abstraction Safety Guide (ASG). Despite Steve Hoberman’s warnings, his writings, particularly his latest work, still engage with abstraction, similar to the approach of John O’Gorman, who also starts from a foundational perspective before delving into more abstract levels.
When discussing taxonomies, particularly in the context of the animal kingdom, there is significant value in understanding the relationships and differentiators between broader and narrower definitions. Therefore, Howard highlights the importance of both abstraction and categorisation.
Managing Enterprise-Level Data Models
Howard moves on to discuss the complexities of managing enterprise-level data models, particularly when organisations utilise various tools and repositories, such as GitHub, for version control and model comparison. Although migrating a simple SQL Server database to Neo4j may seem straightforward, the real challenge arises with distinct data models that may not align despite proper naming conventions.
Organisations often wrestle with multiple versions of models that represent current and ideal states, compounded by diverse metadata sources like application servers and SAP, which, while adhering to naming standards, fail to integrate cohesively. A structured approach is essential to managing a large and diverse model landscape, as understanding the differences between models can uncover semantic discrepancies and enhance analytical insights. Additionally, the accessibility of graph database tools like Neo4j remains a concern for architects handling such issues, underscoring the necessity of converting relational databases into graph formats for better visualisation and comparison of data relationships.
Managing Definition Management and Semantic Inconsistencies in the Business
Effective definition management in addressing semantic inconsistencies encountered in various perspectives is important. Howard highlights the need for clarity in definitions, as an attendee notes instances where the same terms held different meanings within different contexts, such as 'bed' in a hospital referring to a room versus a physical object.
The Attendee suggests that achieving consensus on definitions, possibly by using specific prefixes to delineate unique meanings, can streamline the implementation of technology and facilitate clearer communication. Another attendee notes that while questions like "how many customers do I have?" are common, the context behind the definitions is crucial to avoid misleading information in data reporting.
The Importance of Definitions in Data Modelling
Howard moves to close off the webinar by highlighting the importance of having a unified definition of key terms, particularly "customer," within an organisation to address significant inconsistencies encountered among stakeholders. Notably, he mentions a study by Steve Hoberman revealed that different individuals can interpret the same term in various ways, emphasising the need for clarity and standardisation in data modelling.
Data modelling is often perceived as an automated tool rather than an art form, which can lead to misunderstandings at the enterprise level. Establishing a robust term and definition management system is crucial for effective knowledge mining and ensuring that new facts align with existing corporate definitions, thereby improving consistency and understanding among business executives. Ultimately, addressing these inconsistencies is vital for the organisation's success, especially before implementing advanced technologies like graphs and large language models.
If you would like to join the discussion, please visit our community platform, the Data Professional Expedition.
Additionally, if you would like to be a guest speaker on a future webinar, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!