
EconData for Data Managers

Executive Summary
This webinar offers understanding and effective utilisation of economic data for professionals in various fields. The Statistical Data and Metadata Exchange (SDMX) information model has emerged as an international standard for data management and definitions in economics, offering benefits such as definitional consistency, automation in data cataloguing, and simplified access to public domain data. Data democratisation has become increasingly vital, particularly in South Africa, which presents unique challenges. EconData is a key economic data provider, centralising access to different versions of data sets and data flow and offering data as a service through the SDMX data model. Metadata and registry structure are crucial components of the SDMX data model, allowing for effective analysis and reporting. By leveraging the benefits and features of the SDMX data model, professionals can gain valuable insights and improve decision-making processes.
Webinar Detail
Title: Econ-Data for Data Managers
Date: 02 June 2022
Presenter: Daan Steenkamp and Byron Botha
Meetup Group: Data Managers
Write-up Author:Howard Diesel
Contents
The Economic Value Proposition of EconData
Importance of Understanding Economic Data
Importance of Data Management and Definitions in Economics
Features and Benefits of the SDMX Information Model
Benefits of Definitional Consistency and Automation in Data Cataloguing
Benefits of the SDMX Information Model for Reporting and Publishing
Data Democratisation and Challenges in South Africa
EconData: Centralising and Simplifying Access to Public Domain Data
Overview of Data Access and User Interaction
Analysis of Different Versions of Data Sets and Data Flow
Data Providers and Registry Structure in a High-Level Overview
Key Value Proposition of Econ Data and Its Benefits
The Benefits and Features of Data as a Service and the SDMX Data Model
Introducing Econ Data as a Data Provider for Balance Sheets
SDMX and Metadata in Data Sets
The Economic Value Proposition of EconData
EconData is a centralised platform for managing economic data from various sources. It is built on the widely adopted SDMX information model and is available as open-source software. By centralising internal and external economic data, EconData improves access to South African public domain data, making it discoverable and easy to use. The platform also provides valuable data management and governance attributes, enabling automation and updates. EconData is designed to ensure definitional consistency, adhere to SDMX standards, and promote data democratisation. Decision-making becomes more efficient and effective with easy access to the right information.
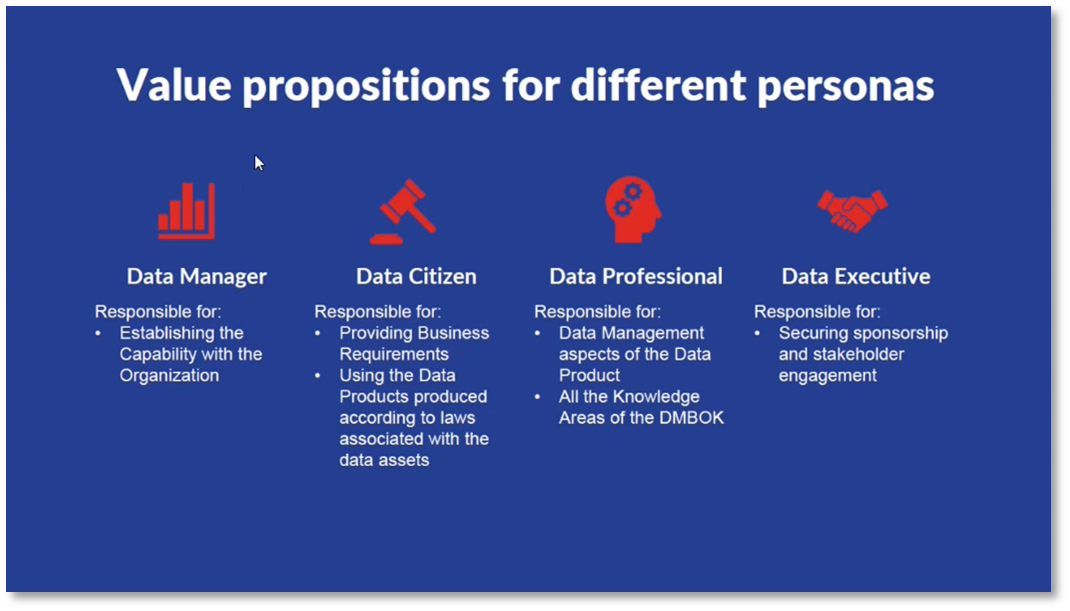
Figure 1 Value propositions for different personas

Figure 2 EconData Value Proposition
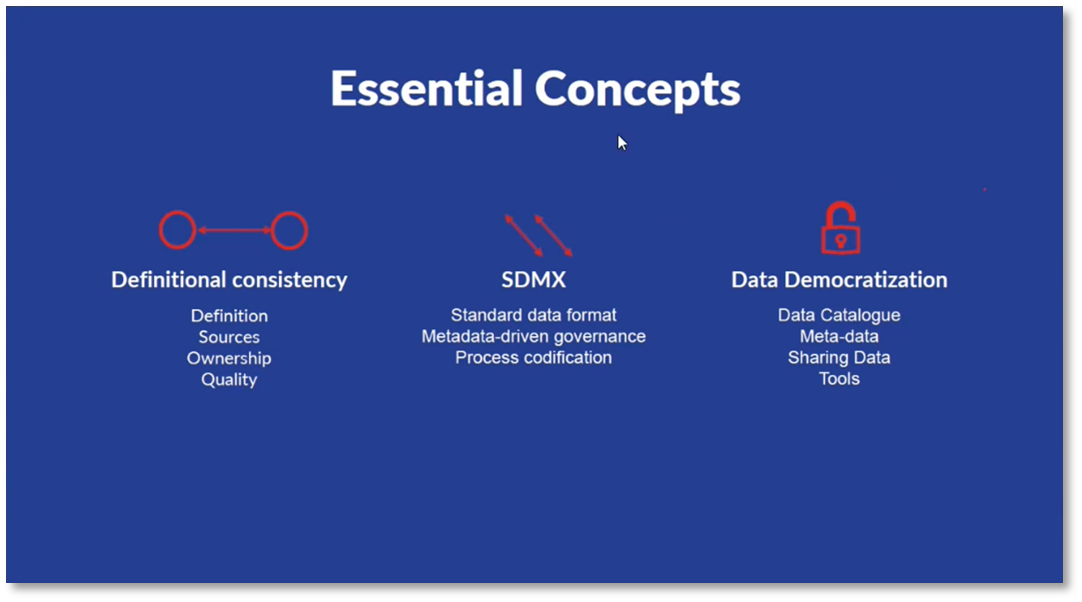
Figure 3 Essential Concepts
Importance of Understanding Economic Data
The management of high volumes of data from various sources can be challenging. In regulated firms and industries, it is crucial to identify inconsistencies between data and address them. It is also important to know where specific data is stored and how it is used. As reporting requirements for economic data increase, it becomes necessary to understand different high-level economic concepts, which may have different definitions and relationships. Although authoritative sources exist for some economic concepts, supplementary estimates from other sources may be available. Important aspects of economic data include frequency, transformations, and security classifications. Economic time series often undergo revisions, so storing different data vintages is essential. Finally, assessing the quality of economic time series is critical for data management systems.
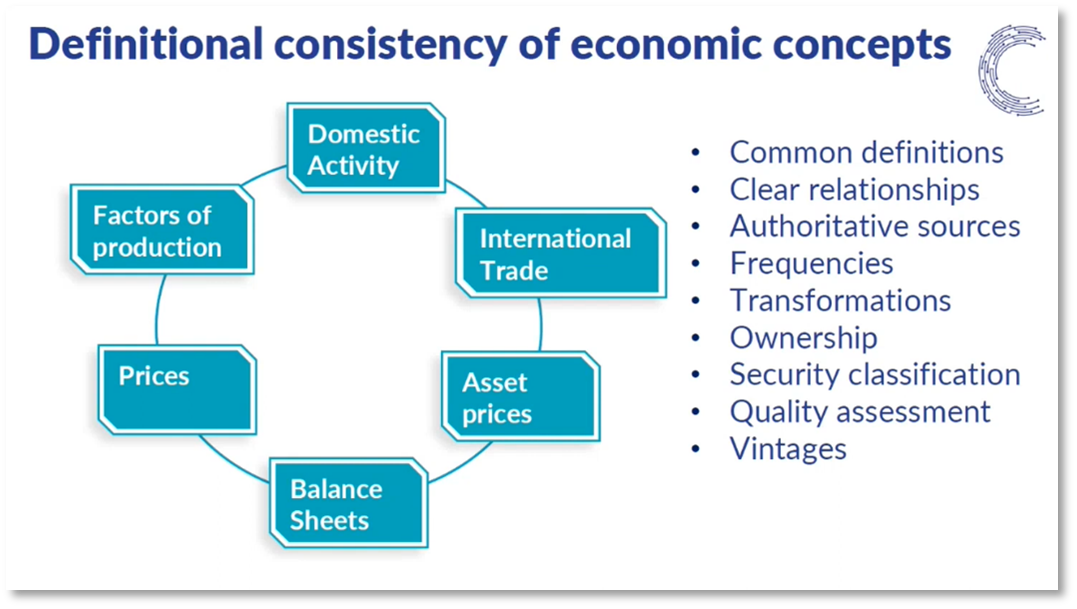
Figure 4 Definitional consistency of economic concepts
Importance of Data Management and Definitions in Economics
The different definitions of balance sheets based on periods and corresponding versions are discussed, as well as the separate concepts and measures of factors of production. Daan Steenkamp highlights the limitations of official measures of economic activity, such as GDP, and the importance of considering other data sources with higher frequency to provide a more complete picture. He also emphasises the significance of understanding the context-specific differences in data management and definitions across economies and over time for effective data management and economic analysis.
Features and Benefits of the SDMX Information Model
Statistical agencies, institutions, and data providers like Eurostat, central banks, multilateral institutions, and the World Bank widely use the SDMX information model. It provides a standardised structure for data and metadata, making it easier for machines to read and update databases. The SDMX model allows the combination of information from different data sets within and across organisations, simplifying data integration. It also enables transparency and governance by documenting data construction and management processes. The SDMX data registry provides an efficient way to store metadata artefacts, allowing for easy mapping and querying of data from different sources. Additionally, detailed metadata can be attached to data, including information on content, methodology, and data quality. The metadata structure definition helps manage and present concepts, dimensions, and code lists, providing valuable information for data users. Finally, the SDMX information model enables the classification of data for reporting and publication purposes and the construction of taxonomies for different groups of data flows and metadata.

Figure 5 Why SDMX (Statistical Data and Metadata Exchange)?
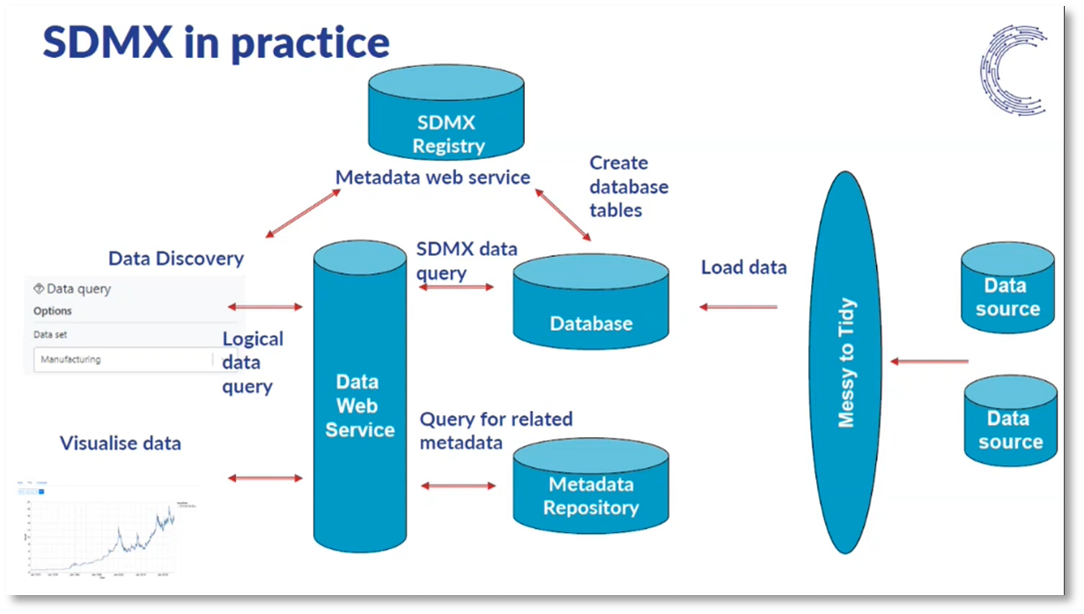
Figure 6 SDMX in practice
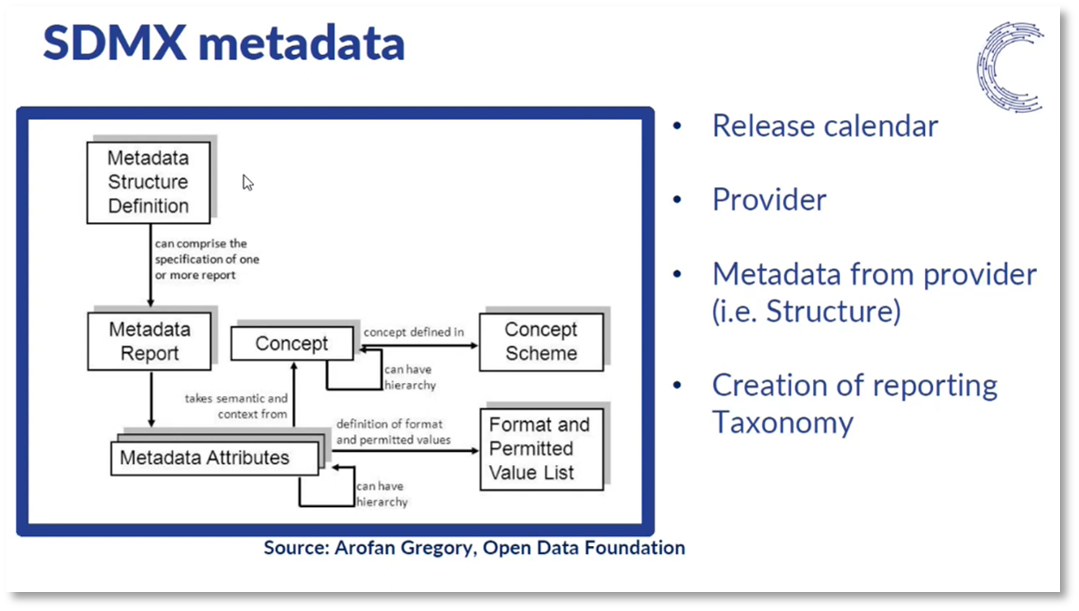
Figure 7 SDMX metadata
Benefits of Definitional Consistency and Automation in Data Cataloguing
The benefits of automating data cataloguing through definitional consistency and mapping to concept schemes are discussed. This process helps to eliminate the need for manual intervention and ensures that data entries are consistent and accurate. By defining concepts and metadata structures, users can streamline the retrieval and analysis of data. Sharing metadata structures between organisations promotes collaboration and enhances global consistency. The upcoming version, SDMX.3, extends mapping capabilities and introduces features for new data types, like geolocation data and data transformations. Additionally, integrating SDMX namespace references in value taxonomies allows for labelling the value of time series.
Benefits of the SDMX Information Model for Reporting and Publishing
The SDMX information model is a powerful tool for controlling reporting and publishing. It defines what data is allowable and enables user allowances for specific subsets of the data. Additionally, it identifies who is responsible for providing the data and allows for linking to specific data provision agreements. This is important for the governance process around data management and enables responsible data sharing.
The SDMX model also constrains the scope of data or metadata that can be supplied to specific users while enabling organization-wide access. In contrast, legacy data management approaches struggle to achieve such controlled and responsible data sharing.
A central bank's experience highlights the challenge of controlling access to data before it is sent to external parties. However, with the SDMX model, different data flows can be constrained in different ways and published at different times to allow for differentiated access. The SDMX information model is a powerful and flexible solution for effective data management and sharing.

Figure 8 Data flows for controlling reporting & publishing
Data Democratization and Challenges in South Africa
Data democratisation is a global movement that seeks to make data more accessible to people outside of specialised fields. One important tool in achieving this goal is SDMX (Statistical Data and Metadata Exchange), which provides a standardised format for data and metadata and allows users to interact directly with the data, automate processes, and avoid tool lock-in. However, in the South African context, different providers often provide public domain data in varying forms, making it challenging to automate the availability of statistics. To make matters worse, loading data from individual spreadsheets with specific concepts can be slow and inconsistent due to its complex hierarchy.

Figure 9 Data Democratization

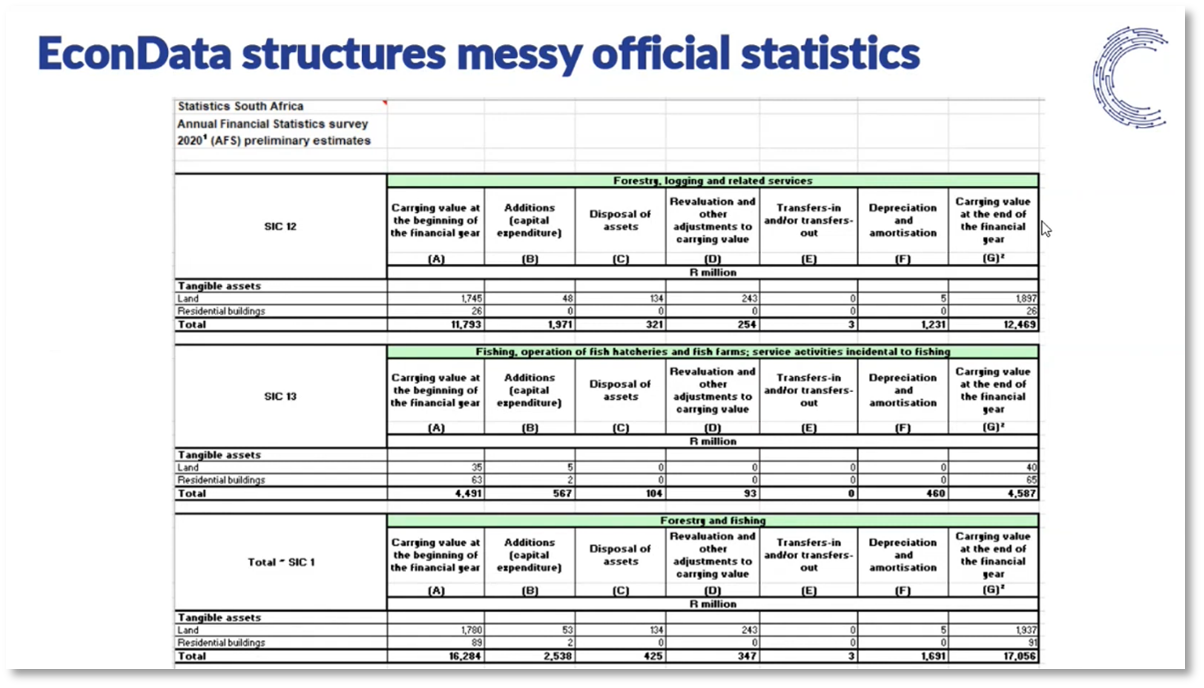
Figure 10 EconData structures messy official statistics
EconData: Centralizing and Simplifying Access to Public Domain Data
EconData is a reliable source of public domain data in South Africa, providing easy access to time series of individual concepts at the industry level. Its centralised data definitions ensure definitional consistency and enable concept comparison. The data registry includes detailed metadata for each time series, making it easy to download the underlying data in the right format. Additionally, Econ Data applies quality checks to loaded data to ensure its validity. The SDMX structure used by Econ Data provides a codified process for data management. Overall, EconData simplifies accessing and downloading time series data, which would otherwise appear static and difficult to use.
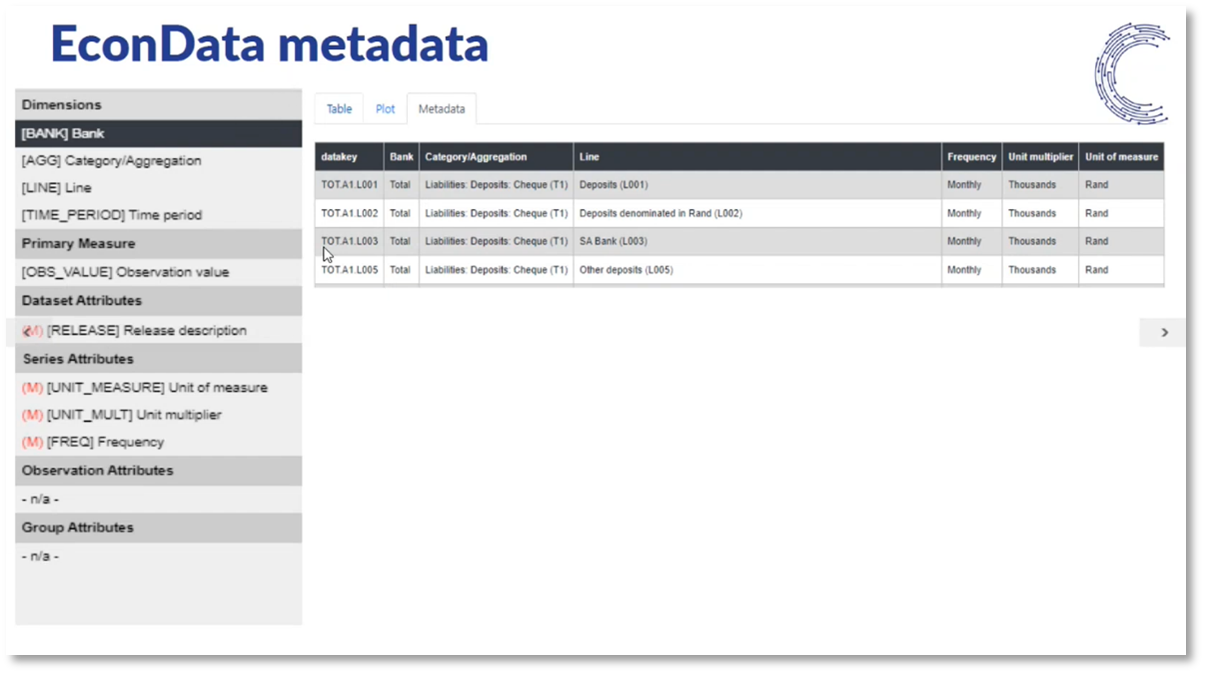
Figure 11 EconData metadata
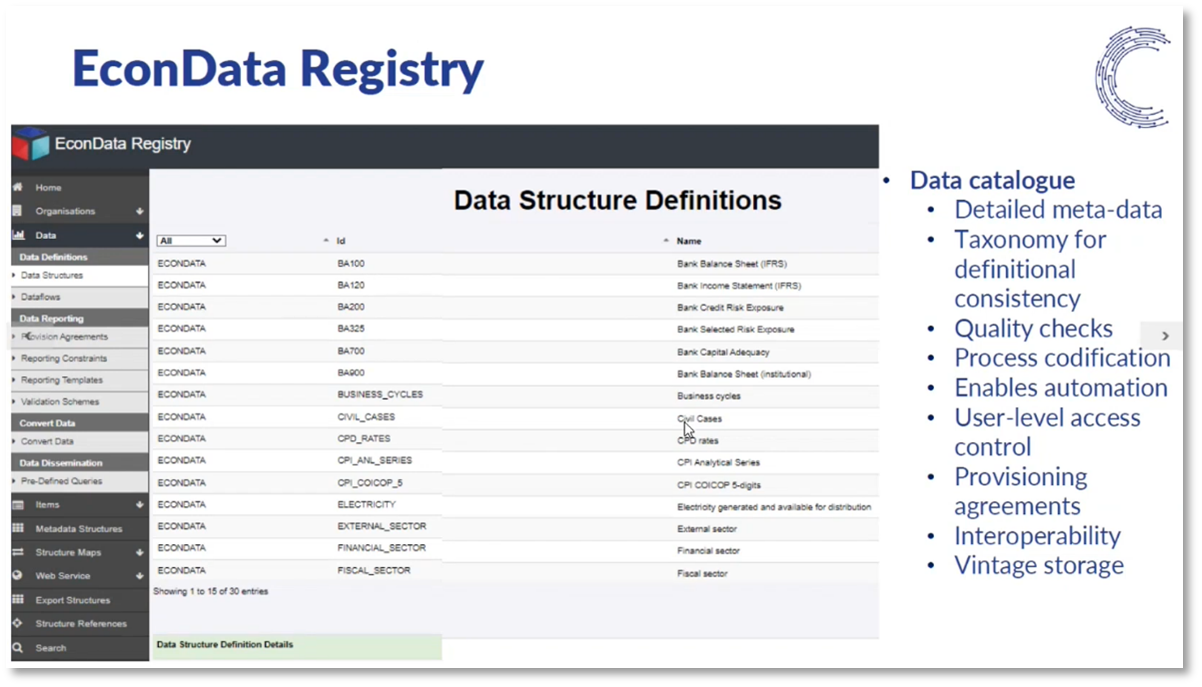
Figure 12 EconData Registry
Overview of Data Access and User Interaction
The significance of data as a service lies in its ability to offer various tools for users to access data seamlessly, making it adaptable to various South African economic processes. Econ Data is a platform that provides users with an API to retrieve data and update existing processes programmatically. Users can interact with the data using different tools compatible with SDMX-based data. While searching for time series with similar economic concepts is not currently available in Econ Data, the registry allows users to explore category schemes and statistical subject matter domains by clicking on them. The demonstration provides concrete examples of user interaction and data discovery using the registry. The Basel Regulatory Reporting category scheme, which primarily applies to banking regulations, is described in detail, and different categories within the scheme, such as the BA series, can be viewed. Their linked structures are machine-readable and discoverable programmatically.

Figure 13 Users can use variety of tools to access data
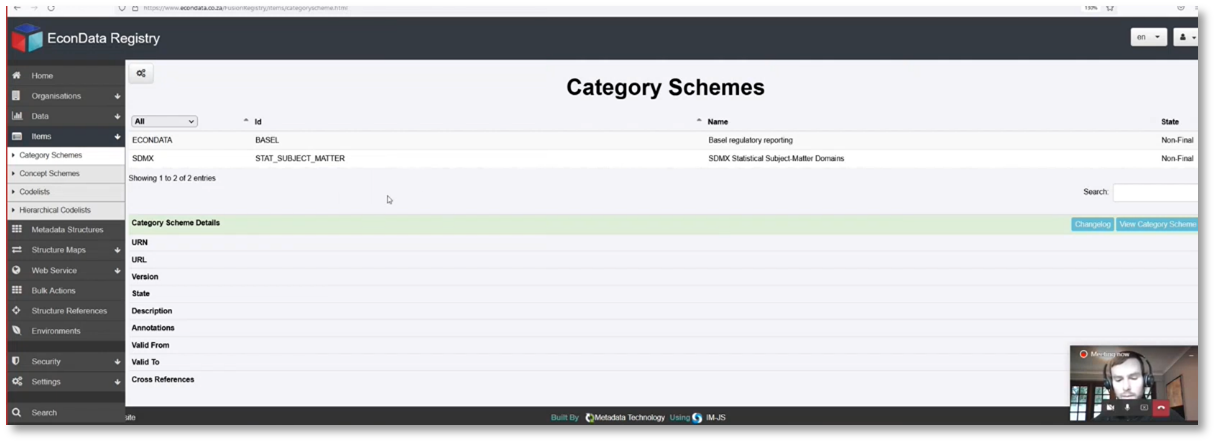
Figure 14 EconData Registry Category Schemes
Analysis of Different Versions of Data Sets and Data Flow
Byron Botha highlights the different versions of data sets available, focusing on the BA 100 version 1.2. The data flow provides various information, with different concepts related to it on the left-hand side. Dimensions of the data make up a time series with bank aggregation, line, and time period attributes, along with additional attributes and enumerated possible values known as code lists. The South African Reserve Bank provides the data set, with code list restrictions varying depending on the concept. The BA 100 only includes the total aggregation without individual institutions, and the correct version, BA 100 version 1, has restrictions applied to it. Reporting constraints are set up to enforce restrictions, and the restriction cross-references the data flow. It's important to note that the analysis may be confusing if the data is unavailable.

Figure 15 Analysis of Different Versions of Data Sets and Data Flow
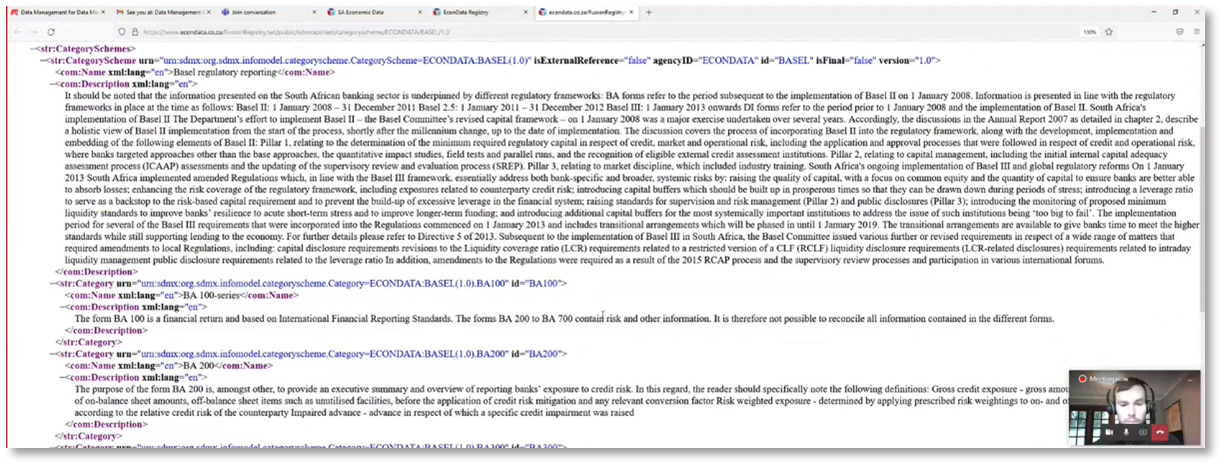
Figure 16 Analysis of Different Versions of Data Sets and Data Flow continued

Figure 17 Analysis of Different Versions of Data Sets and Data Flow continued
Data Providers and Registry Structure in a High-Level Overview
A high-level overview of a system's data flow and provider scheme is provided, ensuring the data's accuracy and integrity. The scheme includes predefined and cross-referenced allowable data providers, validating all data against the schema and registry. The system can restrict views and apply various data restrictions, with a category screen offering an organised view of data flows different data providers, and underlying data structure definitions. The information model and standard used in the system offer flexibility and may potentially align with FIBO (Financial Industry Business Ontology), while the registry includes additional complexities and features. Overall, the system's data flow and provider scheme make it a reliable source of information.

Figure 18 Data Providers and Registry Structure in a High-Level Overview
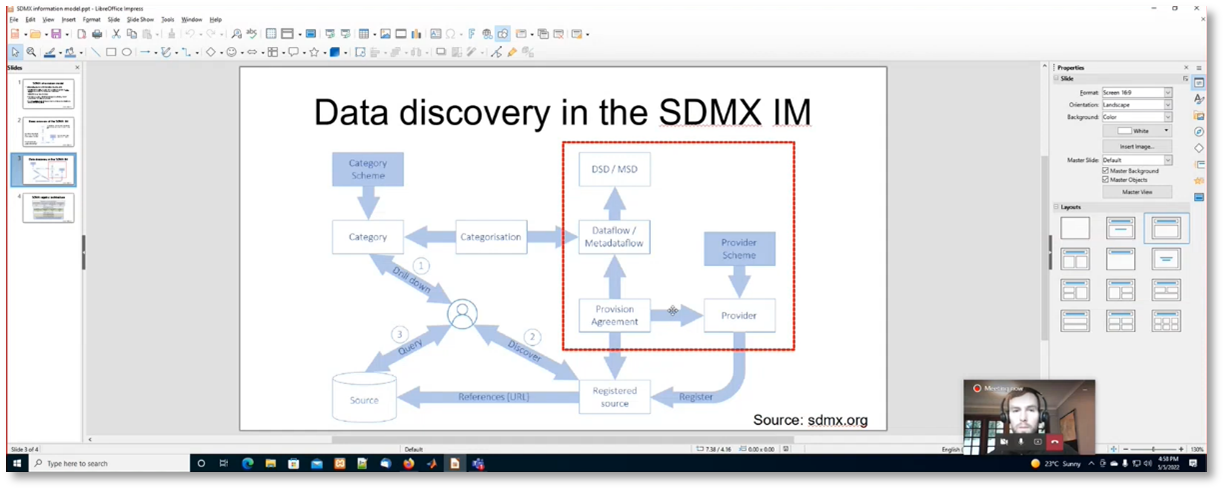
Figure 19 Data discovery in the SDMX IM
Key Value Proposition of Econ Data and Its Benefits
The EconData management system offers centralised economic data with consistent definitions, accessible both on-premise and online. Users can view available data through the registry and interact with it using various tools. By adopting an SDMX work approach, users can enjoy data management, governance benefits, and user-level controls for specific data sets. The system also boasts interoperability benefits and data availability in different formats. Centralising economic data ensures a single source of truth, making it easier to trace processes and ensure governance. The system's availability from anywhere, especially in today's post-COVID world, addresses the challenges faced by large institutions.

Figure 20 EconData use case for Statistical Data Manager
The Benefits and Features of Data as a Service and the SDMX Data Model
Daan highlights the benefits of accessing advanced technologies and collaborating between institutions to deal with difficult challenges. Responsible data use, and a glossary of metadata and concepts enable seamless collaboration and governance. Decision-making becomes easier with the ability to ensure the latest data from specific sources. The platform allows for scheduled updating based on data suppliers' publication schedules, ensuring the latest data is available. Secure data handling is possible through role-based access governance and data management authority. Data creators can push data and perform quality checks, while specific provision agreements benefit governance. The SDMX data model includes managed governance and process management features. The platform offers usage statistics at an individual level and enables analytics to demonstrate the value of specific series and the overall system. The standard provides implicit and enabled quality checks for data accuracy.
Introducing Econ Data as a Data Provider for Balance Sheets
During the presentation, Howard expresses gratitude for the insights provided and offered the possibility of EconData becoming a data provider for the user's environment. EconData can provide valuable insights by comparing customer data to balance sheets within the industry. Daan emphasises the importance of trustable public data, such as banking partner data, which can serve as a baseline for comparison. Collaborative opportunities were mentioned, and the speaker plans to reach out for further discussion. South Africa has extensive bank balance sheet information available through the BA 900 regulatory form, which Econ Data compiles and makes easily accessible. Daan highlights the convenience of having this extensive data at one's fingertips, saving significant time and effort. Lastly, Tobias mentioned the important use case of using Econ Data to enrich internal data with metadata, which the buyer confirmed as feasible.
SDMX and Metadata in Data Sets
SDMX ISO is a flexible information model and registry that enhances structured statistical data with metadata capabilities. This feature allows for the application of the model and registry to various data implementations. SDMX also allows for data transformation with metadata and process, making it a powerful tool in the open metadata data catalogue environments market. Although there are competing standards, SDMX's features make it stand out as a valuable resource for managing and enriching data.
If you would like to join the discussion, please visit our community platform, the Data Professional Expedition.
Additionally, if you would like to be a guest speaker on a future webinar, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!