
Enabling Business People to perform Data Interrogation using AI, RAG & a Chatbot with Howard Diesel

Executive Summary
This webinar outlines a comprehensive approach to building a conversational AI chatbot tailored for data interrogation and Metadata analysis, integrating CDMP Data Management principles. Howard Diesel addresses key challenges in navigating diverse business terminologies and cultures, while emphasising the importance of Data Governance and value recognition strategies. The proposed chatbot will leverage a robust technology stack, including a vector database integrated with Google Drive and AI capabilities, to enhance Data Management artefacts and streamline document management processes.
Howard explores the intricacies of configuration and execution within chatbots, exploring Data Modelling disciplines and the future of Data Governance, which is shifting towards automation and compliance in business environments. The webinar highlights the need for a cohesive business vocabulary that supports efficient access and shared network drives, while considering the constraints and potential improvements of classification protocols.
Webinar Details
Title: Enabling Business People to perform Data Interrogation using AI, RAG & a Chatbot with Howard Diesel
Date: 24/04/2025
Presenter: Howard Diesel
Meetup Group: African Data Management Community
Write-up Author: Howard Diesel
Contents
Building a Conversational AI Chatbot for Data Interrogation and Metadata Analysis
Practical Implementation of CDMP Data Management Principles
Challenges and Strategies in Navigating Business Terminology and Culture
Understanding Data Management and Challenges in Business
Concept and Implementation of Common Information Models
Data Domains, Deliverables, and Data Stewardship in Business
Understanding the Aspects and Techniques of Building Data Management Artefacts
Data Governance and Value Recognition Strategies
Developing a Chatbot for Data Governance
Developing a Comprehensive Chatbot
The Technology Stack and Techniques for Creating a Chatbot
Implementing a Vector Database with Google Drive and Open AI
Building a Chatbot: A Step-by-Step Guide
Data Models and Information Management in Document Management
Configuration and Execution of Rules in Chatbots
Data Value Recognition and Budget Analysis in Governance Programs
Data Computation and Reasoning Techniques in AI
Future of Data Governance: From Control to Automation
Data Governance and Compliance in Business Environments
Creating a Business Vocabulary for Access to Documents and Shared Network Drives
Functionality of Semantium as a Classification Software
Constraints and Potential Improvements of Classification Protocols
Data Modelling and Discipline in Engineering
Building a Conversational AI Chatbot for Data Interrogation and Metadata Analysis
Howard Diesel opens the webinar and explains that his presentation will focus on the development of a conversational AI chatbot intended for data interrogation and Metadata analysis. He highlights the challenges faced by data scientists, particularly the extensive time spent on data wrangling—often 70-80% of their efforts—leaving only a small fraction for actual analysis.
The presentation, Howard shares, will discuss the use of the Zachman framework as a foundational tool for structuring questions and answers, and adds that there is still a need for a more refined level of granularity in targeting data queries. Additionally, he will present a demonstration of the chatbot’s capabilities, which is planned to further elucidate these concepts and demonstrate the effectiveness of the work done in this area.

Figure 1 Let Me Tell You About Your Data
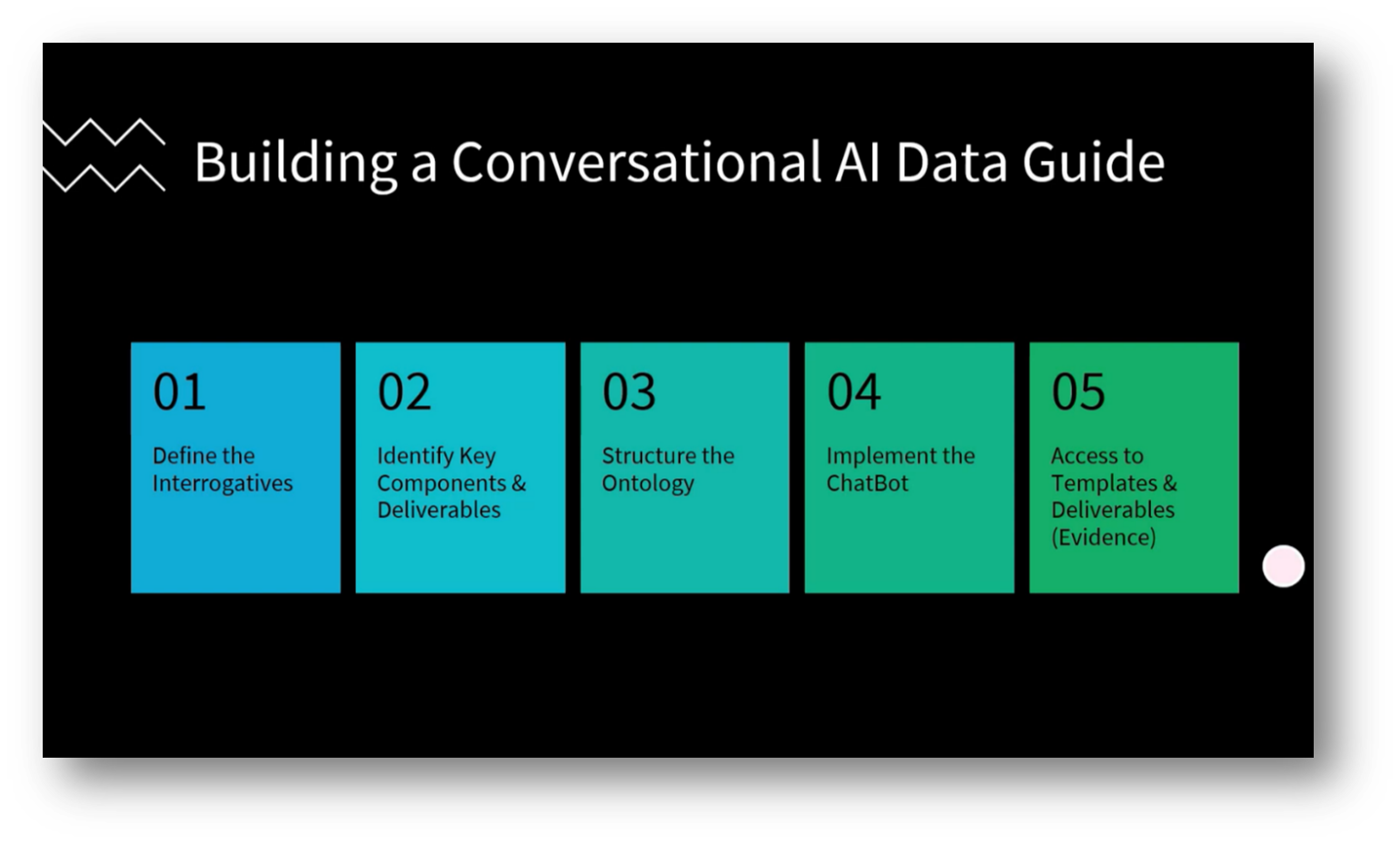
Figure 2 Building A Conversational AI Data Guide
Practical Implementation of CDMP Data Management Principles
The goal of this initiative is to create a more practical and accessible session compared to the CDMP Data Management Fundamentals, which many find too complex due to its extensive 660-page content. The intent is to guide participants at a comfortable pace, providing them with a solid understanding of essential concepts before advancing to more complex material.
Howard notes that the Chatbot project is in response to feedback about the fast-paced nature of the Fundamentals course. He adds that a special chatbot will be developed to enable business professionals to ask questions about data in a stress-free environment, helping to alleviate any embarrassment associated with asking what they perceive as "stupid" questions. The chatbot will also include visual explanations through Power BI to address the common issue of text-heavy responses.

Figure 3 'Let Me Tell You' Deck

Figure 4 Building A Chatbot for Data Management
Challenges and Strategies in Navigating Business Terminology and Culture
Howard discusses the challenges around identifying and understanding the data available within an organisation. The key focus is on how to effectively ask the right questions and use appropriate language that resonates with the business's culture and industry terminology.
Attendees share the emphasis on the importance of being able to articulate thoughts and concepts clearly before seeking confirmation from others to avoid the fear of appearing uninformed. Additionally, Howard adds that each industry, such as oil and gas, has unique rules and processes that further complicate communication within different corporate environments. This understanding aids in developing effective tools, like chatbots, to address such inquiries.

Figure 5 "What Metadata do we need to answer the Questions?"
Understanding Data Management and Challenges in Business
Identifying essential Data Management questions revolves around an organisation's data assets, categorised into various sections, including Business Definitions, Data Structure, Governance, and Data Quality. A selection of eight key questions highlights what business stakeholders and Data Stewards need to understand before selecting data for use.
Specific inquiries include the types of data available, their interrelations, definitions, physical attributes, business rules, quality standards, critical elements, and domains of data. For instance, when asked about the organisation's data, one could reference artefacts such as the common information model or delve into an enterprise Data Catalogue to provide a comprehensive overview of available data, including a data landscape and catalogue for clarity.
The need for clarity and understanding in Data Management centres on establishing a data landscape through effective artefacts, such as subject area models. Howard expresses the challenge of creating these artefacts when they don't exist, highlighting the importance of breaking down complex questions into manageable parts to find accurate solutions.
Howard emphasises the necessity for Data Stewards to have a source of truth to answer common questions. At the same time, an attendee points out that for new capabilities within their organisation, even basic concepts like a Data Catalogue may need clearer definitions, as many stewards may not recognise existing pieces of information as such.
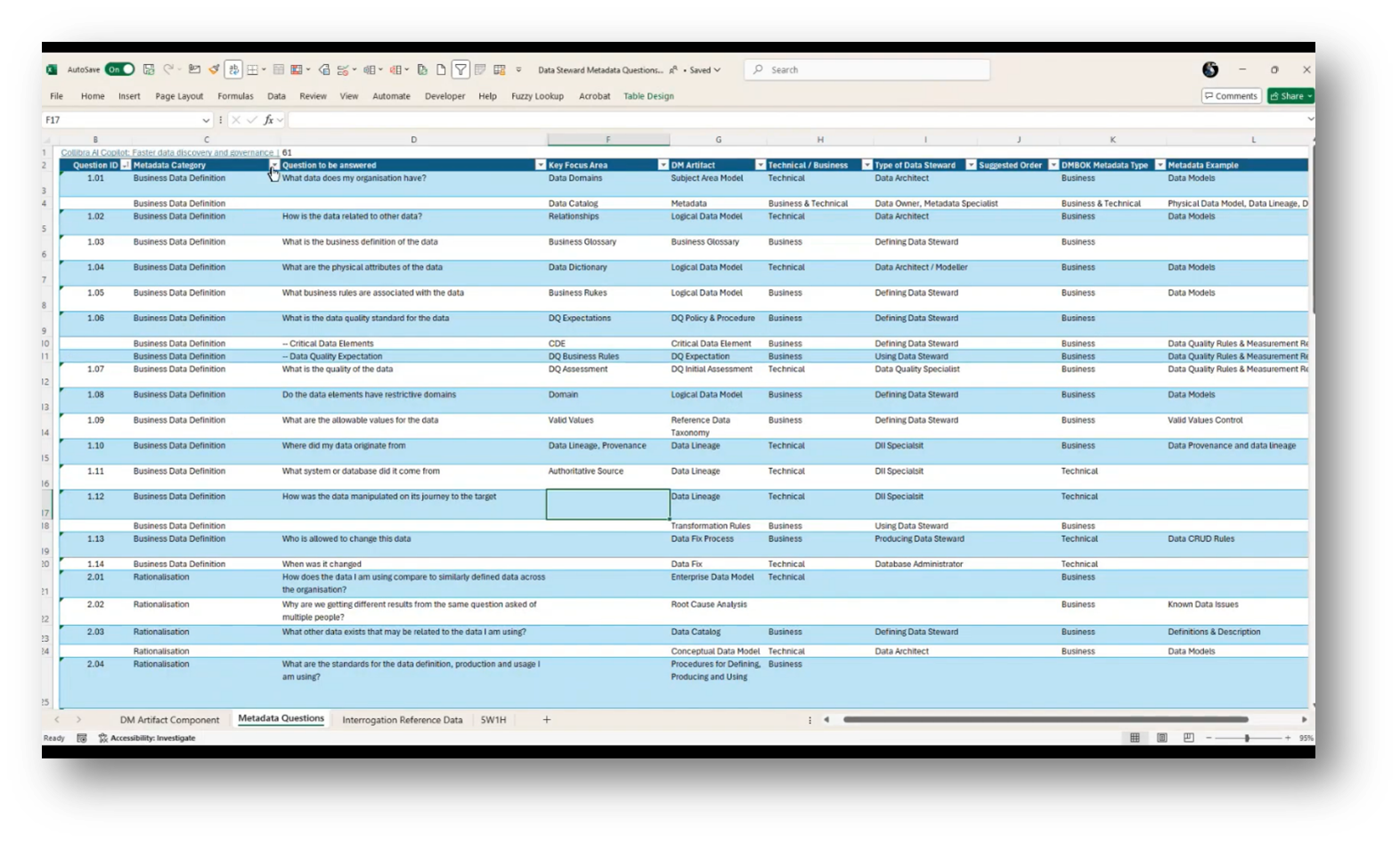
Figure 6 Data Steward Metadata Questions
Concept and Implementation of Common Information Models
Developing a common information model centres on effectively answering key business questions that are familiar to all business personnel. Emphasis is placed on understanding and distinguishing between various Data Management deliverables, such as the Enterprise Data Model and Corporate Information Factory, to ensure clarity in terminology and purpose.
Howard encourages the users of the chatbot to relate to the questions posed, consider how they would seek answers, and identify any existing artefacts that could assist in this process. The goal is to incrementally enhance the organisation's maturity by recognising gaps in artefacts and outlining steps for development. In a few days, a list of essential questions and corresponding artefacts, complete with descriptions and definitions, will be provided to facilitate further discussion and planning.
Data Domains, Deliverables, and Data Stewardship in Business
Breaking down essential concepts related to Data Management revolves around focusing on data domains and deliverables such as subject area models and Metadata stores. Howard notes that key roles include Data Owners, Data Stewards, Data Architects, and Metadata specialists, with an emphasis on the evolving nature of Data Catalogues as unified Metadata repositories that encompass assets, lineage, and Business Glossaries. Additionally, the goal is to facilitate business users' access to data by creating a chatbot that allows them to inquire about available data within their business functions and obtain definitions seamlessly, enhancing their ability to engage with data without barriers or hesitation.
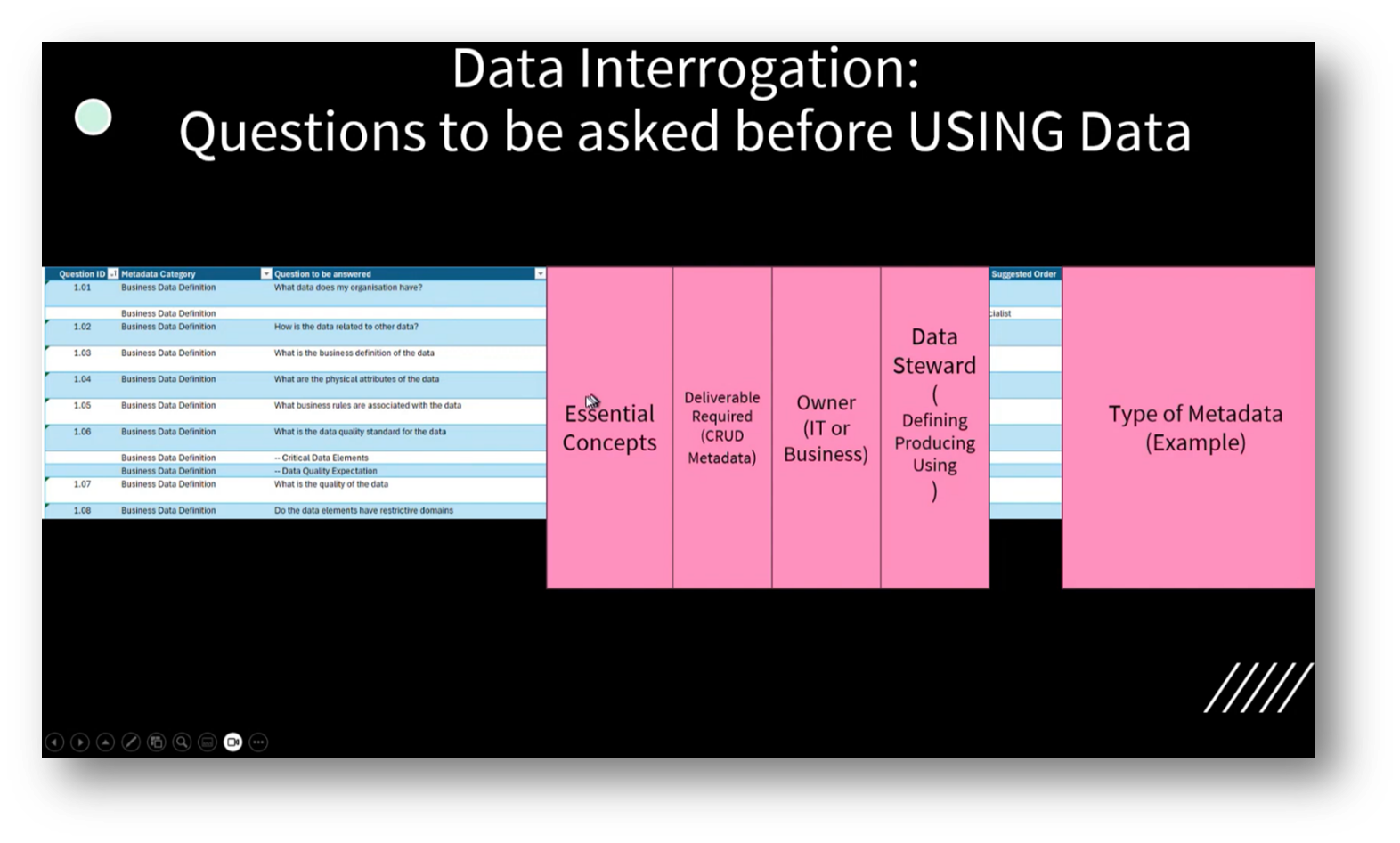
Figure 7 Data Interrogation
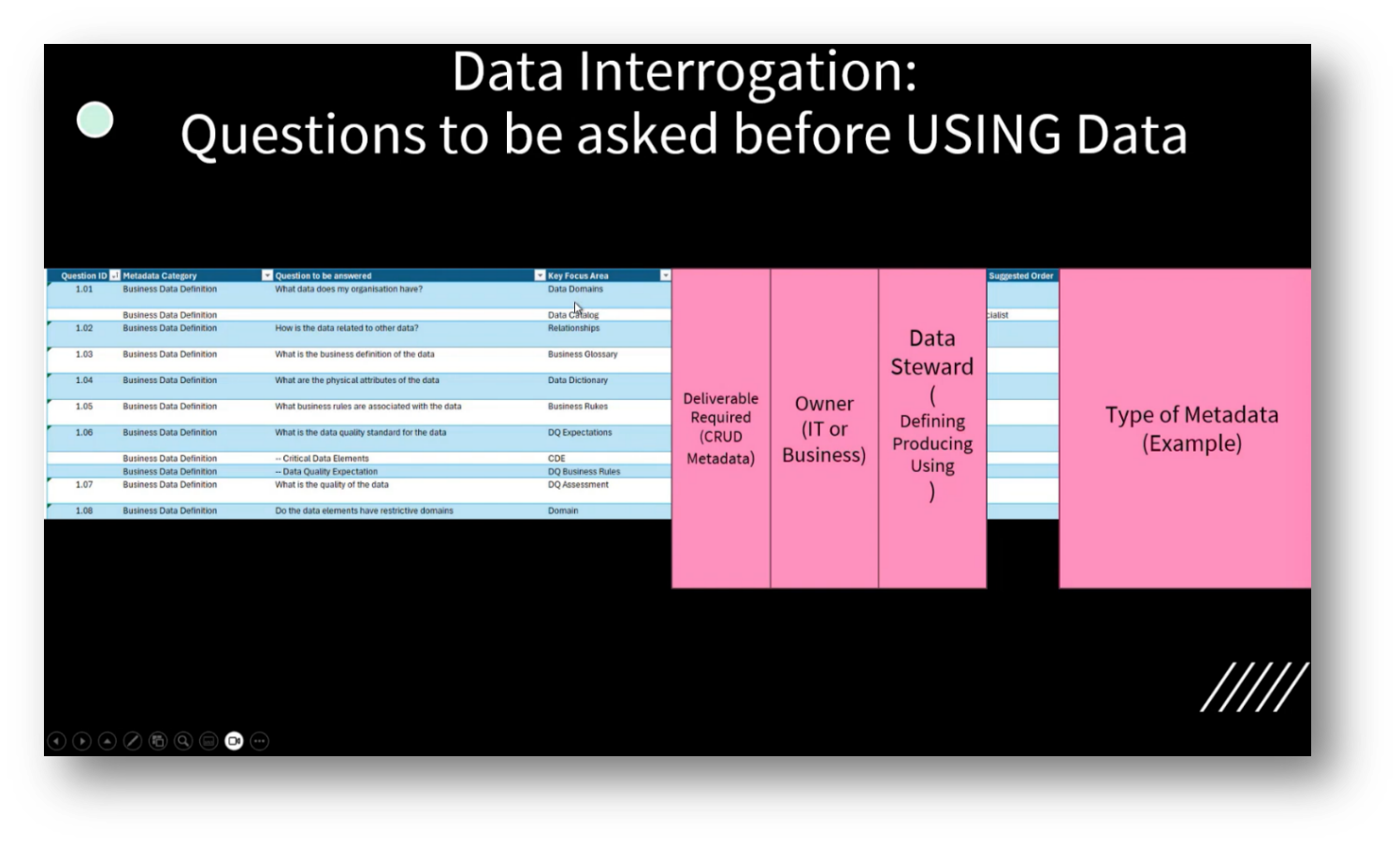
Figure 8 Data Interrogation Pt.2
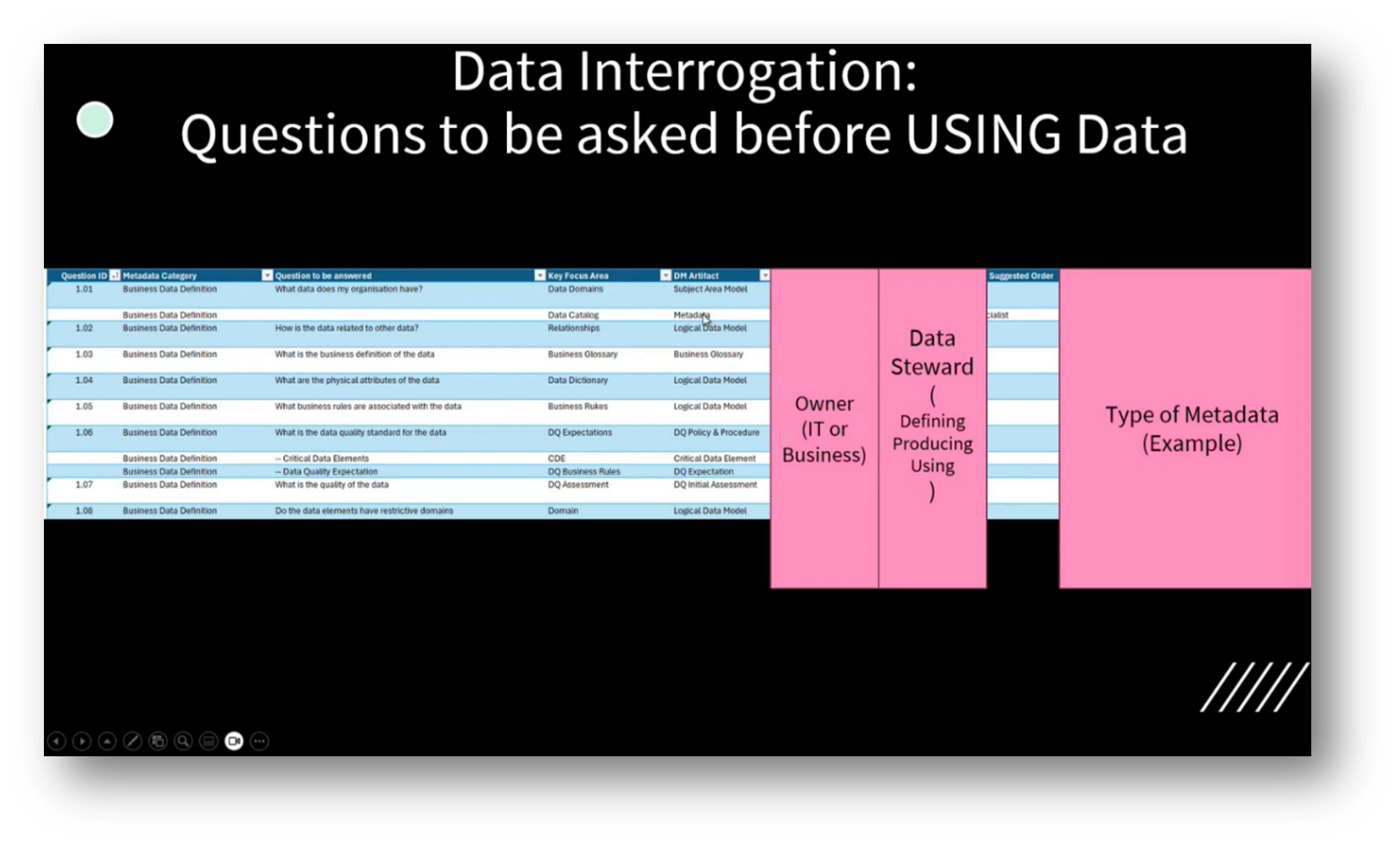
Figure 9 Data Interrogation Pt.3
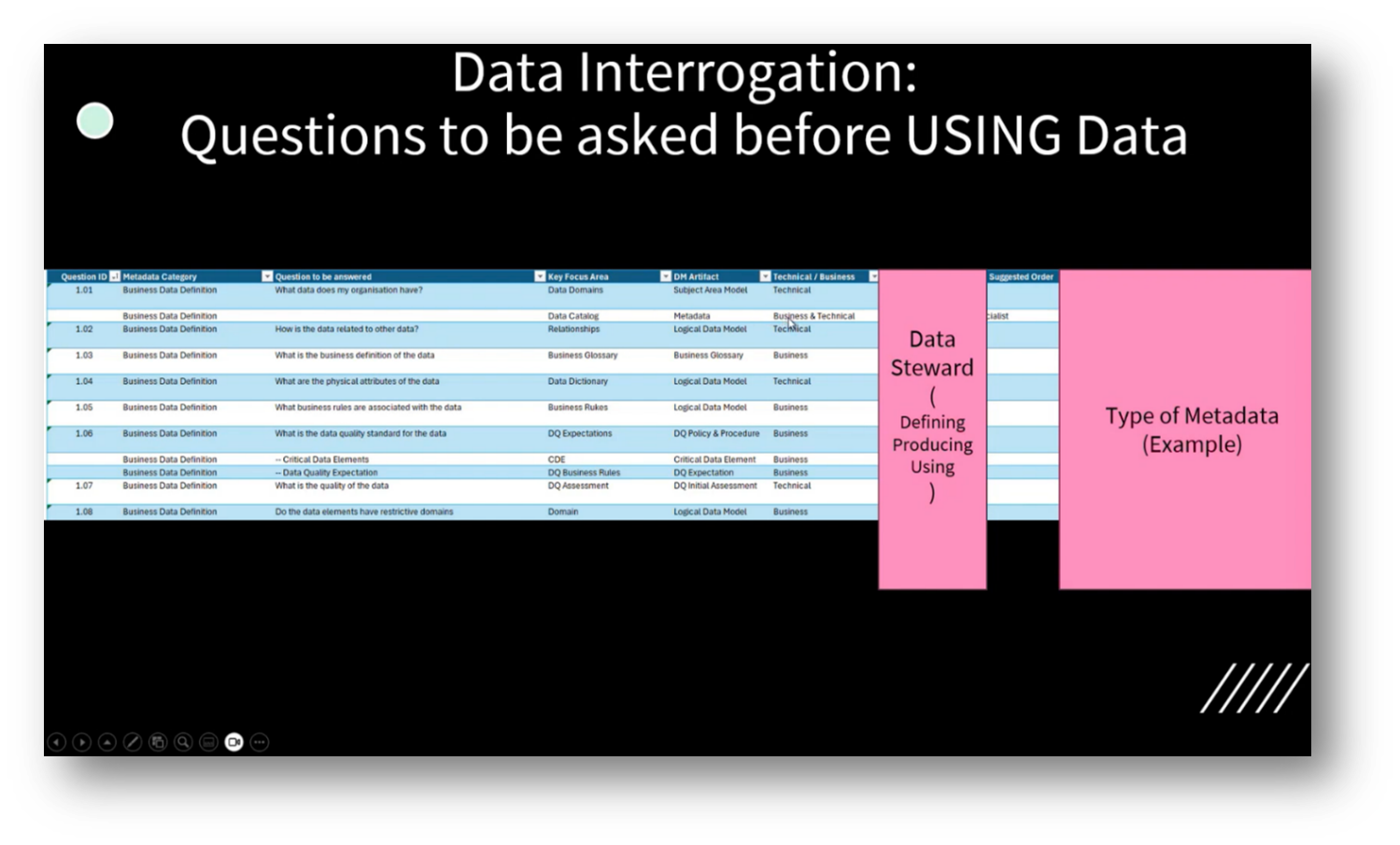
Figure 10 Data Interrogation Pt.4

Figure 11 Data Interrogation Pt.5

Figure 12 Data Interrogation Pt.6
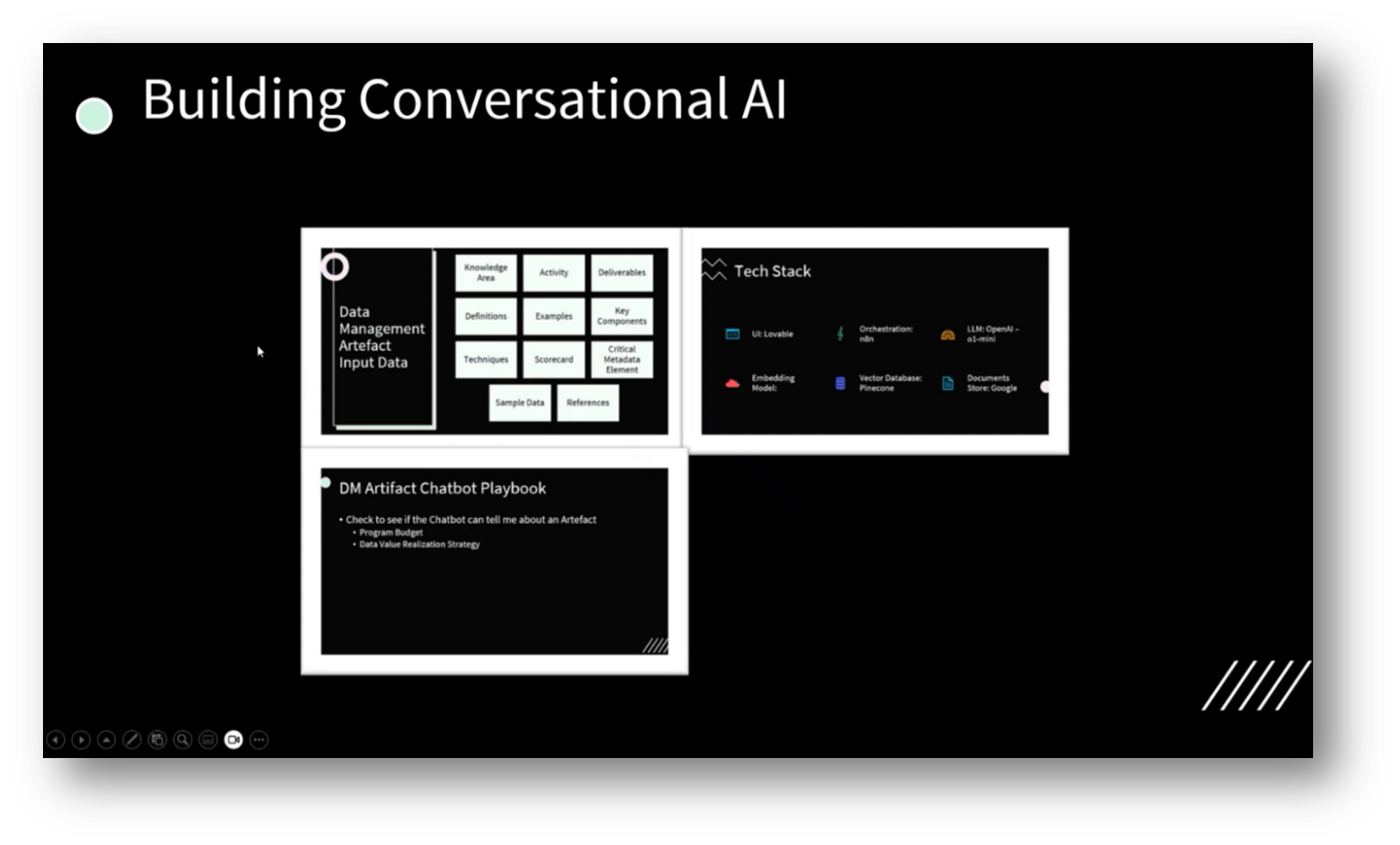
Figure 13 Building Conversational AI
Understanding the Aspects and Techniques of Building Data Management Artefacts
Howard outlines the essential aspects of building a Data Management artefact, focusing on core knowledge areas, activities for creating deliverables, and their definitions. For instance, a conceptual data model consists of key components such as entities, relationships, and constraints. Techniques for building these models and criteria for their evaluation—whether they are deemed good or bad—are also critical.
The importance of critical Metadata elements and value metrics in data value realisation is emphasised. Practical resources, including web references for further reading, are provided to enhance understanding. An example involving higher education illustrates entity types, relationships, and attributes used in the Data Modelling process, all of which can be visualised through tools like Power BI to facilitate deliverable analysis and knowledge sharing within organisations.
Howard then outlines his project, which focuses on systematically organising data for a Chatbot integration to facilitate user conversations around data strategies in higher education, particularly regarding student success metrics and scorecards. The framework comprises 23 knowledge areas, 183 activities, and 289 deliverables, along with essential Metadata elements for each deliverable, including objectives, metrics, stakeholders, asset inventory, time frames, and governance requirements. Additionally, Howard emphasises the importance of clear explanations of value realisation strategies in Data Management maturity assessments, aiming to provide tangible examples of how to enhance graduation rates and identify key stakeholders within the organisation.
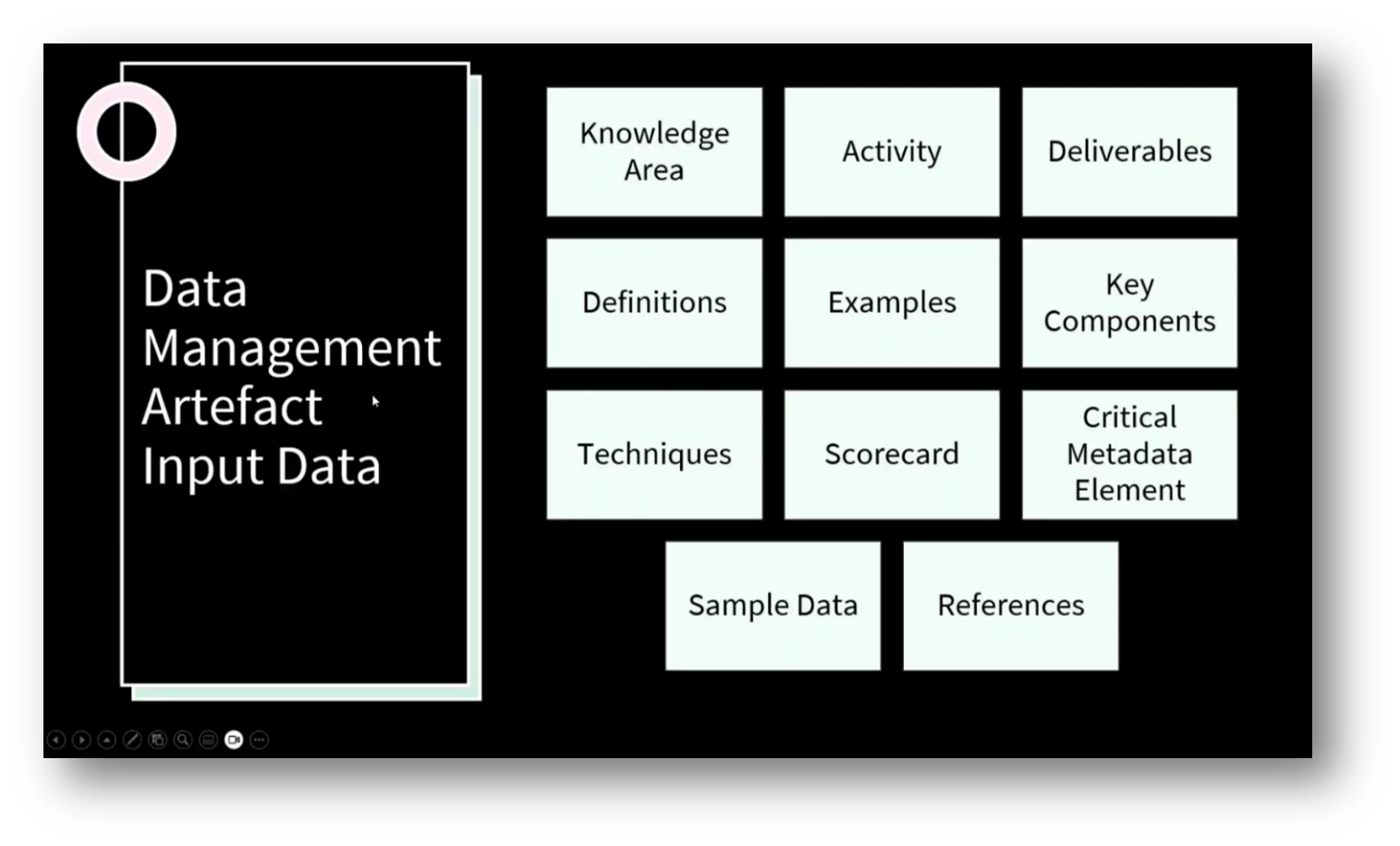
Figure 14 Data Management Artefact Input Data

Figure 15 Data Management Artefact Input Data
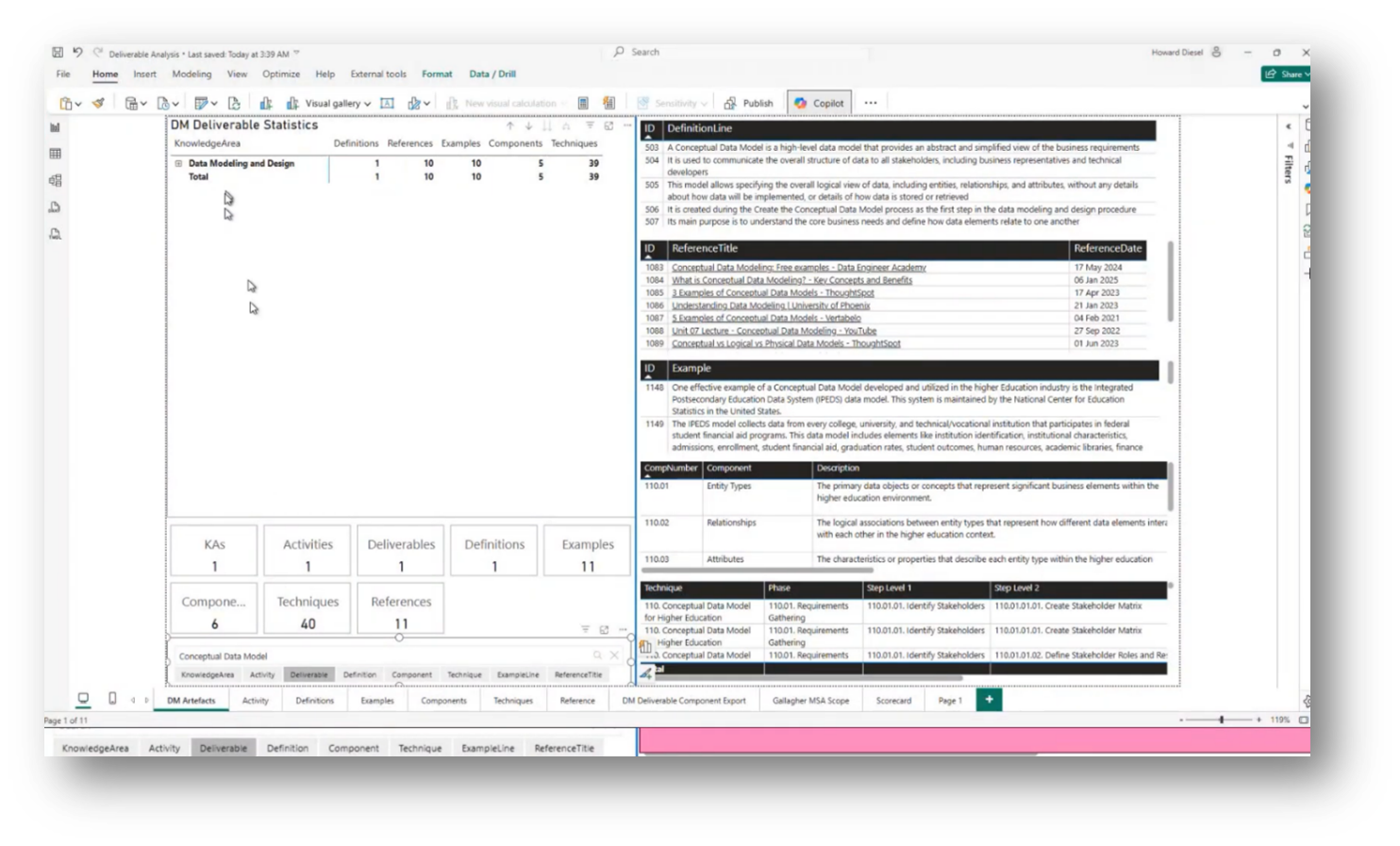
Figure 16 Deliverable Analysis
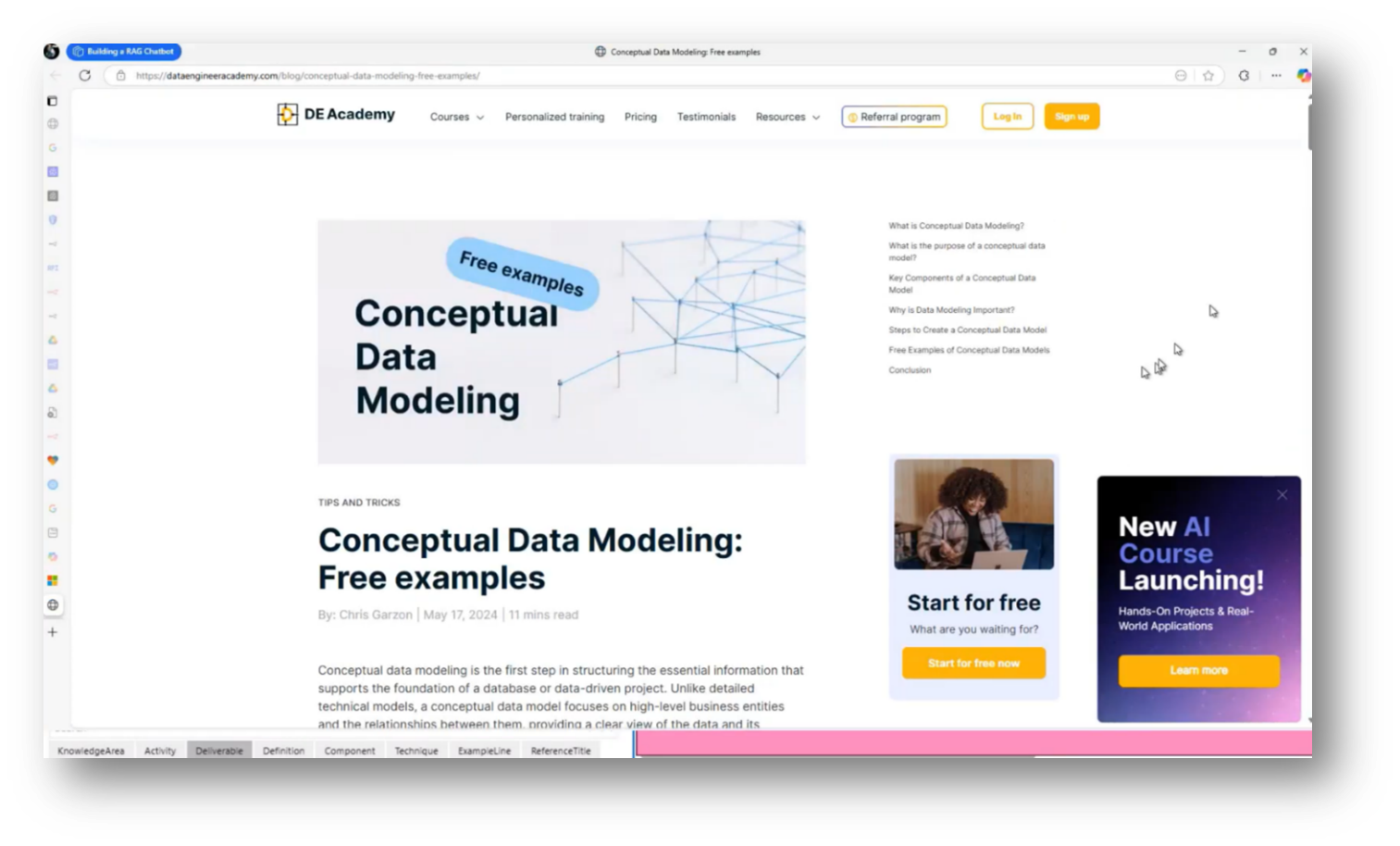
Figure 17 Resource on Conceptual Data Modelling

Figure 18 Breaking down Deliverables

Figure 19 Deliverable Analysis
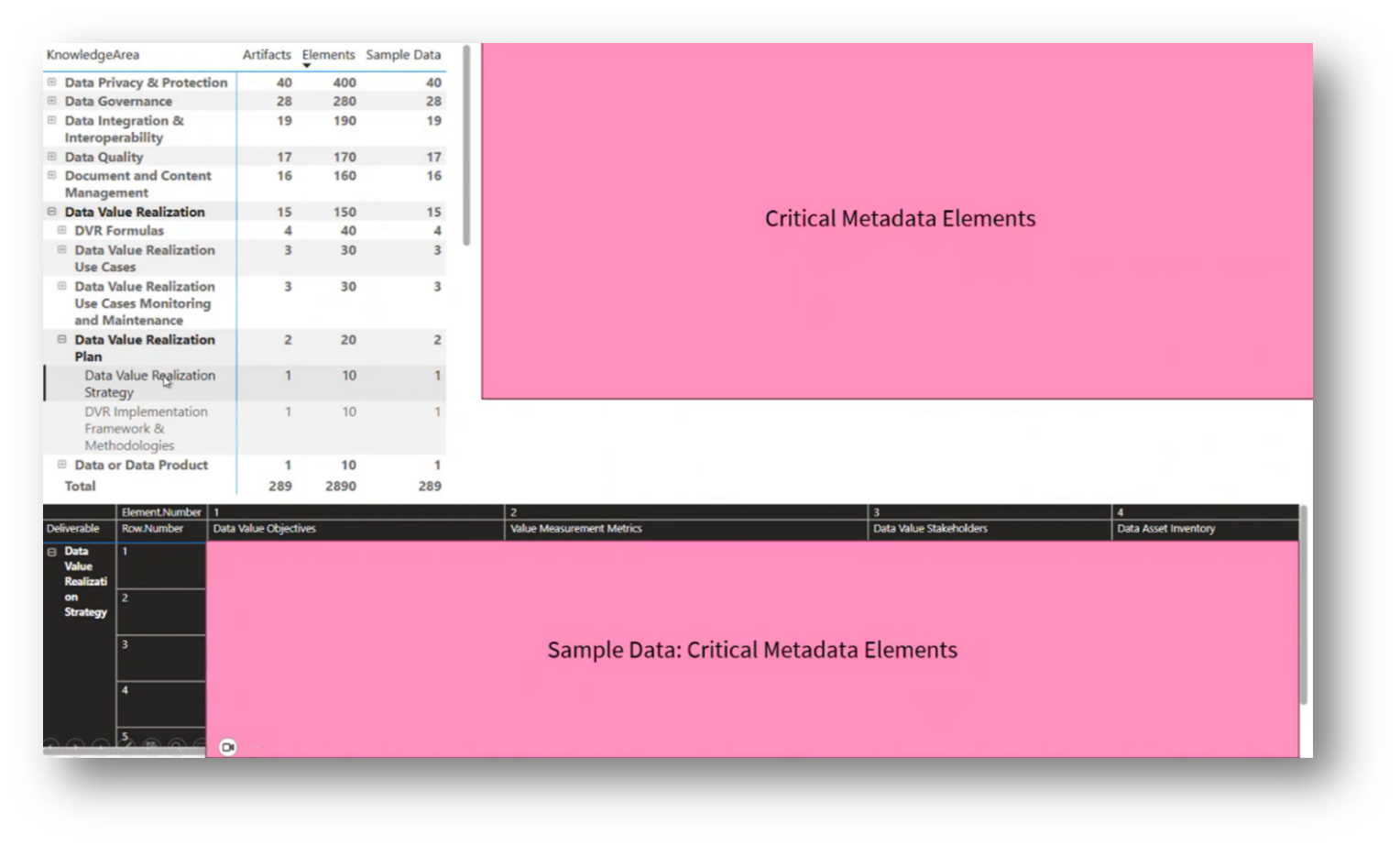
Figure 20 Knowledge Areas Breakdown
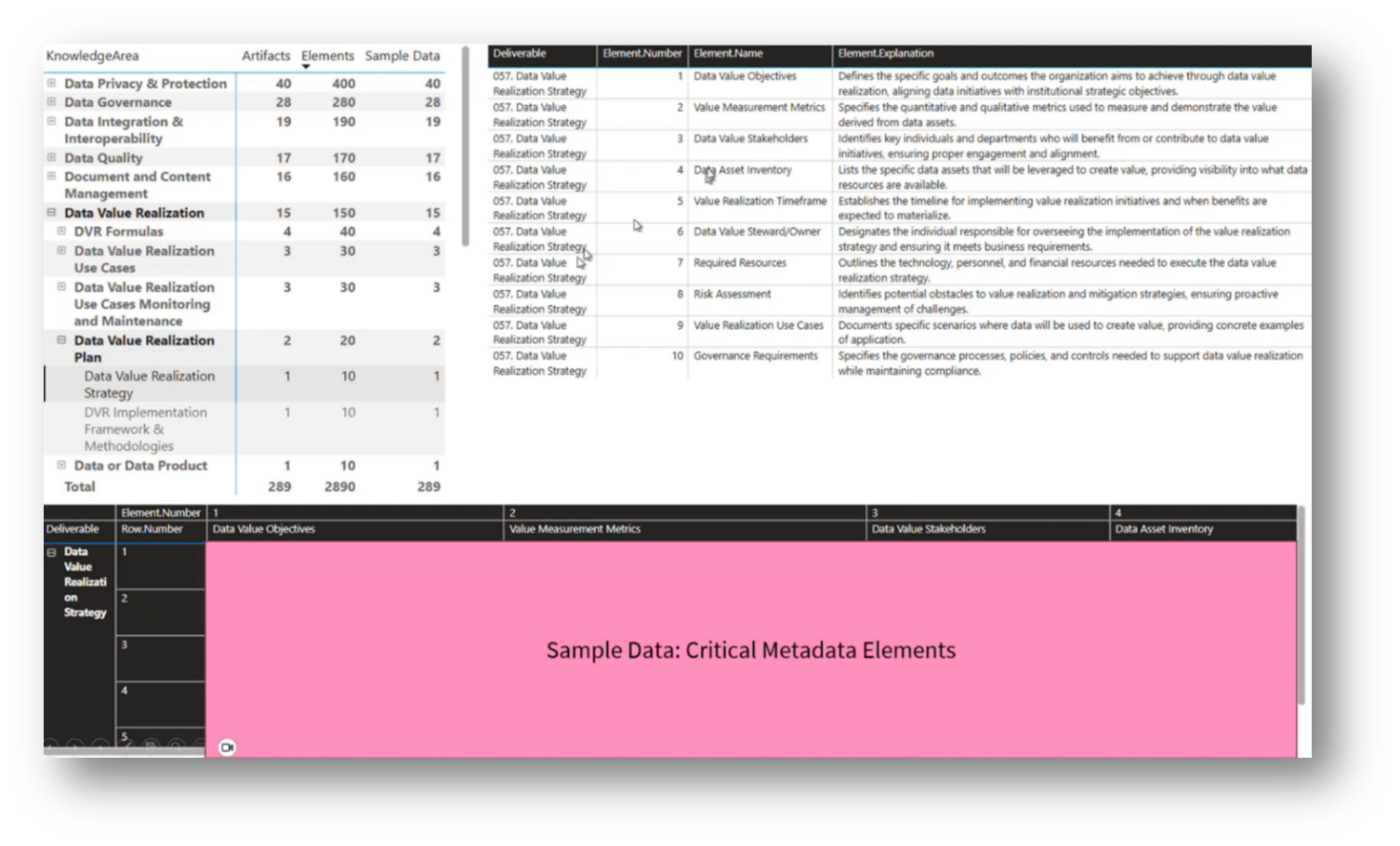
Figure 21 Knowledge Area Breakdowns Pt.2

Figure 22 Knowledge Area Breakdowns Pt.3
Data Governance and Value Recognition Strategies
Developing a Unified Meta Model for Data Governance revolves around focusing on the importance of tailoring information collection and procedural creation to different organisational roles, such as Data Owners and Stewards. Howard emphasises the need for detail; he highlights the necessity of asking targeted questions about existing data to ensure it meets the requirements for decision-making.
The term "data interrogation" is introduced, suggesting that users should vet datasets to confirm their suitability before utilisation. A Subject Area Model is recommended to define the organisational data landscape clearly, limiting the domains to around 20 for effective management and clarity.
Howard also highlights the importance of narrowing the scope of questions by focusing on specific domains and subject areas, as suggested by participants. Personal experiences were shared, including the development of a Data Catalogue with a top management consulting firm at a central bank. This effort revealed that many employees were unaware of the existing data, leading to feelings of wasted effort and confusion about unmet data needs. This raised questions with the attendees about the necessity of certain data and the strategies required to fulfil those needs effectively.

Figure 23 Breaking the Question Down
Developing a Chatbot for Data Governance
The complexities of Data Management within organisations can be solved by focusing on understanding the available data and effectively communicating in a manner that aligns with industry terminology and culture. Howard shares more on key areas of exploration, including essential questions that stakeholders must address regarding data assets, such as definitions, structure, governance, and quality standards.
The development of common information models and necessary artefacts, like Data Catalogues and Subject Area Models, is highlighted as crucial for fostering clarity and facilitating effective Data Stewardship. Howard acknowledges the need for foundational knowledge in Data Governance and the creation of accessible tools, such as Chatbots, to assist business users in navigating data inquiries seamlessly.
Howard highlights a no-code solution for building a Chatbot, emphasising the ease of creating user-friendly interfaces without programming skills. The focus is on providing ontology, structure, and examples to help users collect and understand relevant information efficiently. The Chatbot is designed to simplify access to Data Governance terminology and related concepts, enabling users to quickly retrieve definitions and examples, such as a "data value realisation strategy." By integrating various artefacts and documents, the chatbot enhances the user experience, making information more accessible than traditional methods, such as SharePoint sites. Overall, the goal is to streamline information retrieval and improve understanding of complex data-related strategies.
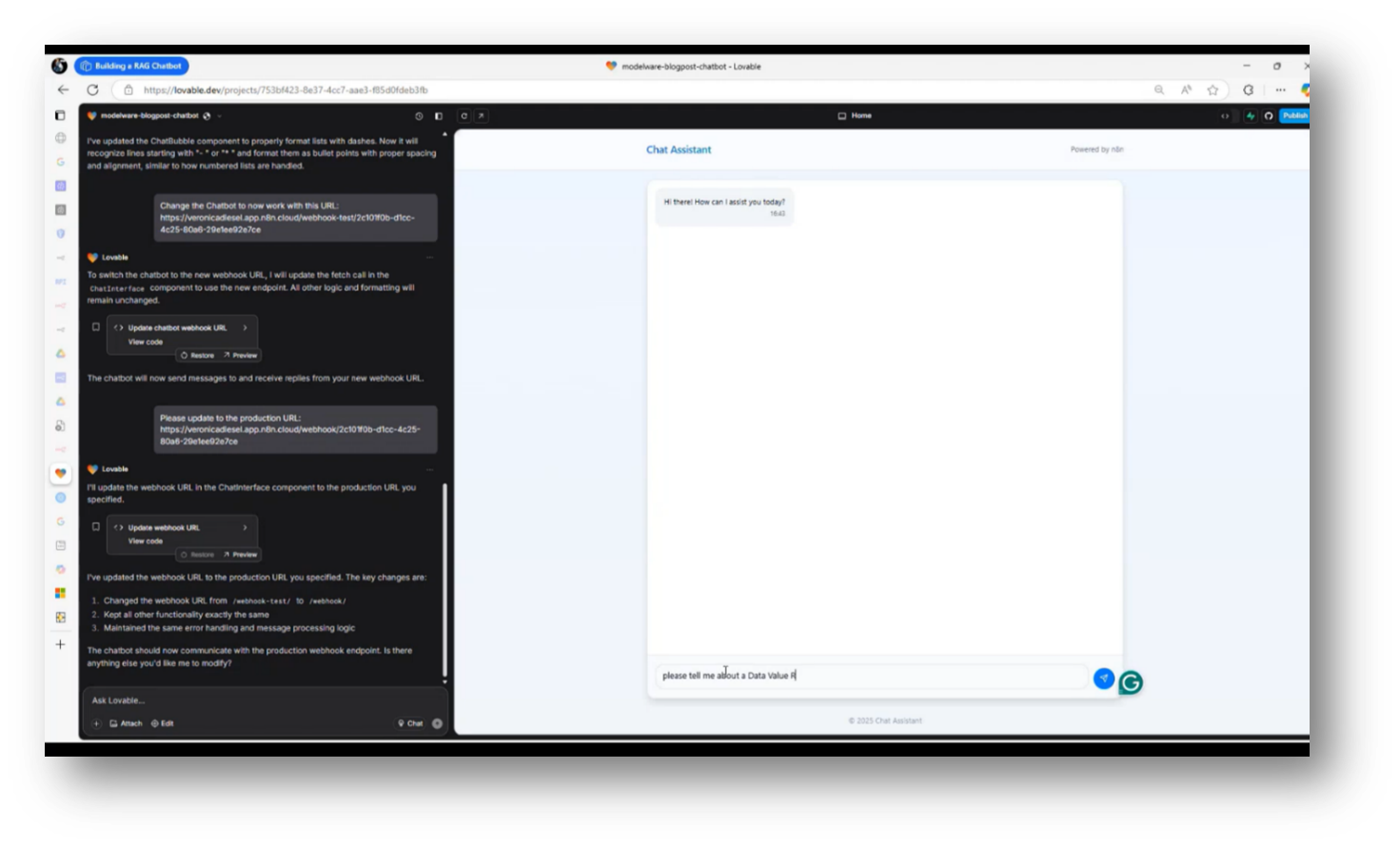
Figure 24 Chat Assistant
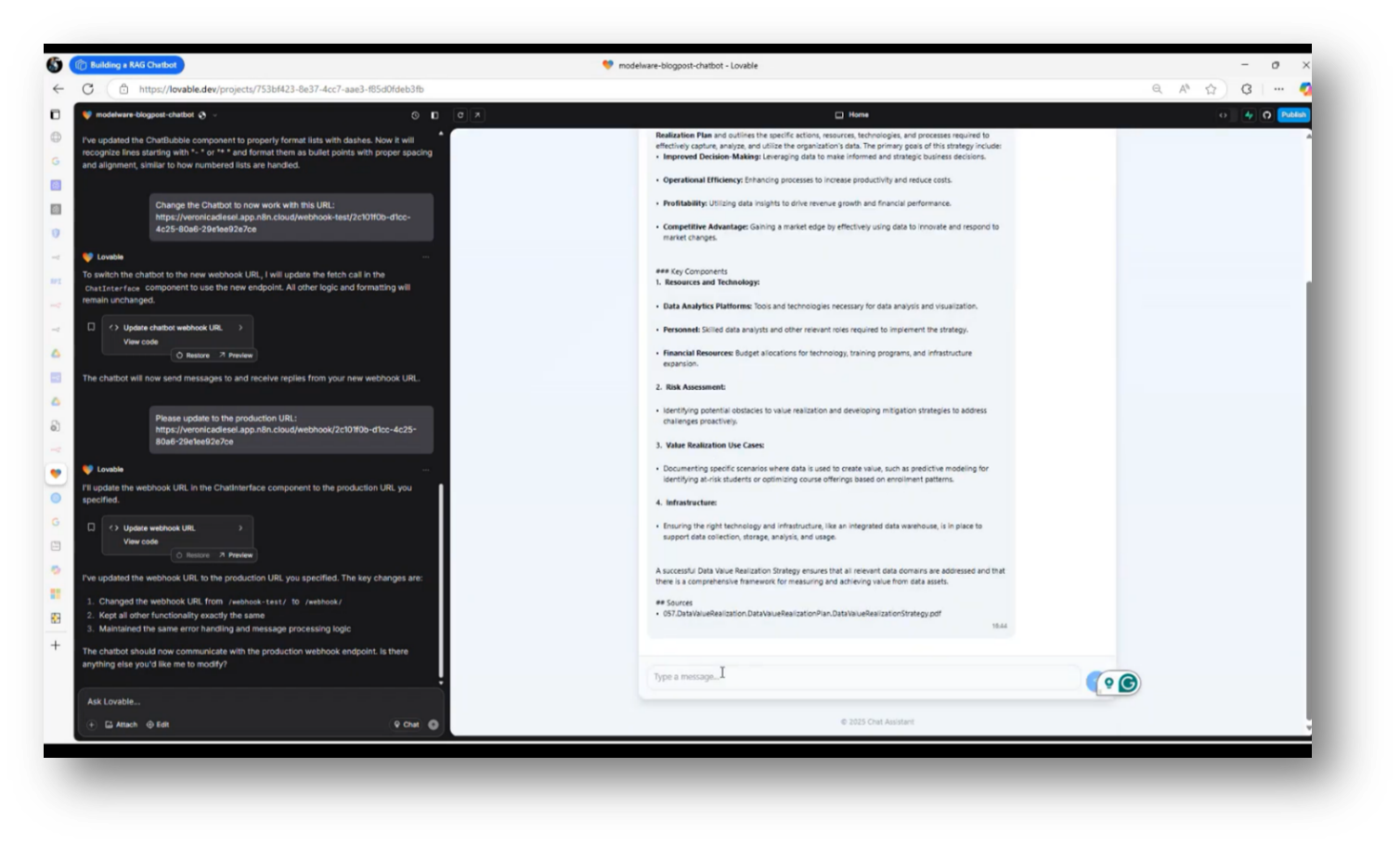
Figure 25 Chat Assistant Pt.2
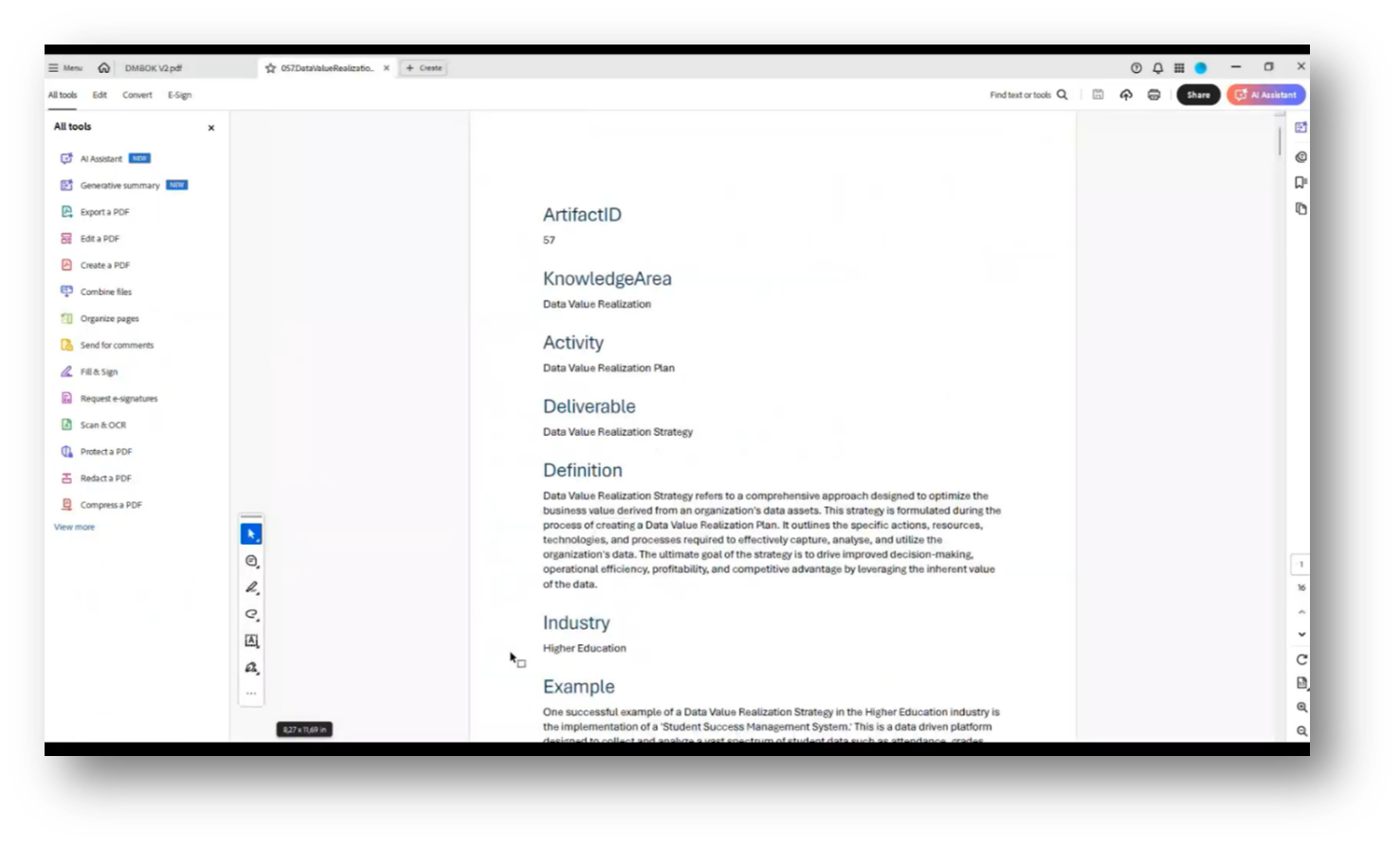
Figure 26 Sourced Document to Train Chat Assistant
Developing a Comprehensive Chatbot
Howard shares his experiences of developing an operational chatbot that can query data, present policies, and provide information by simply stating their needs, demonstrating the tool's capabilities. He reflects on the necessity of differentiating responses based on the audience, such as executives or Data Owners, by organising information into categories and subject areas.
Key questions about the creation of data, such as Who, What, Where, When, and Why, highlight the complexity of information management. The speaker acknowledges the challenge of synthesising vast amounts of information for comprehensive responses and seeks assistance to refine their inquiry process, aiming for clarity in addressing specific elements.
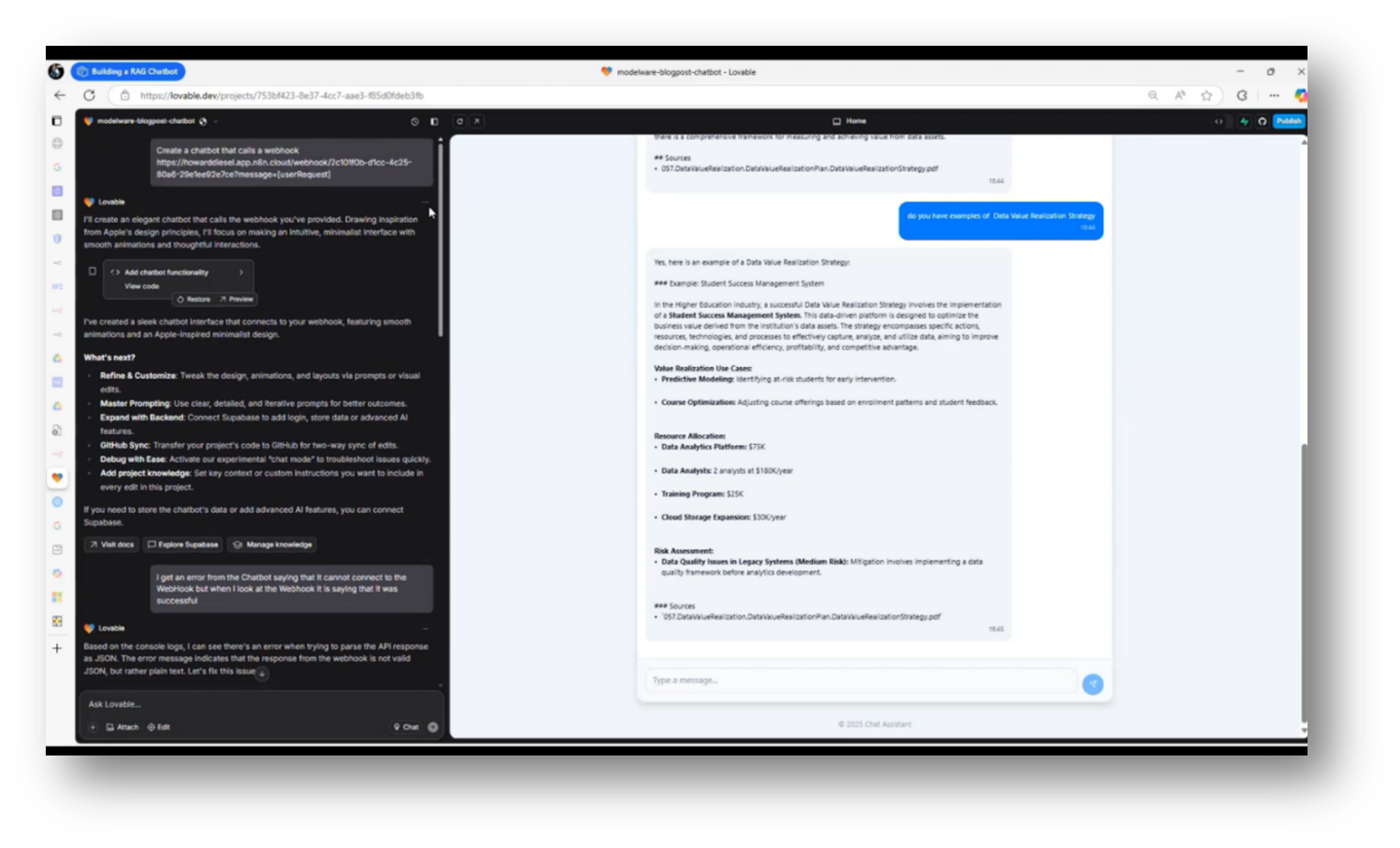
Figure 27 Chat Assistant Pt.3
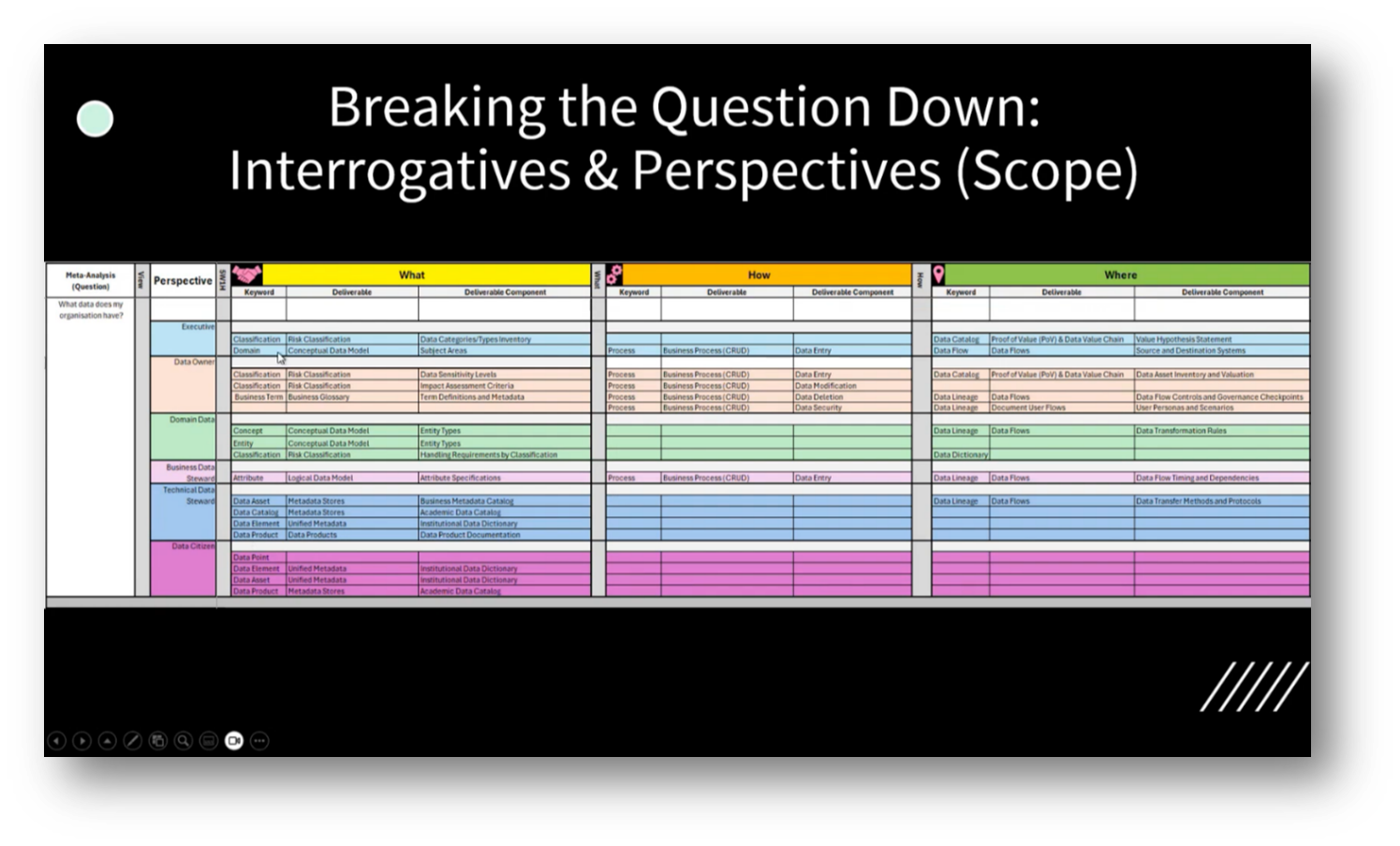
Figure 28 Breaking the Question Down Pt.2
The Technology Stack and Techniques for Creating a Chatbot
The Chatbot was created using a technology stack that includes Lovable, a platform where users can create their own domains and build websites. While the website-building experience was underwhelming, the chatbot proved to be highly effective. An orchestration engine called n8n facilitates data integration and interoperability, allowing for seamless data movement between the user interface and a vector database.
The system employs OpenAI's large language model along with an embedding model to convert PDFs into embeddings and vectors, which are stored in a vector database. This database organises data into tokens and analyses their proximity for relevant querying. When a question is asked, the vector database returns possible answers with similarity scores, indicating how closely related they are to the query.
The use of a vector database enables enhanced querying of artefacts, allowing users to derive insights by breaking down large documents into word relationships. Proximity searches can identify specific references based on the closeness of terms, such as distinguishing between a "data value realisation strategy" and a broader "Data Strategy."
Advanced Large Language Models (LLMs) are now incorporating reasoning capabilities, which facilitate iterative narrowing of answers and support inferences beyond straightforward queries. While knowledge graphs are preferred for their clarity, these systems also document their reasoning processes, providing a log of how conclusions are reached. This feature enhances auditability, addressing key concerns related to risk management by offering transparency on the reasoning path taken.

Figure 29 Tech Stack
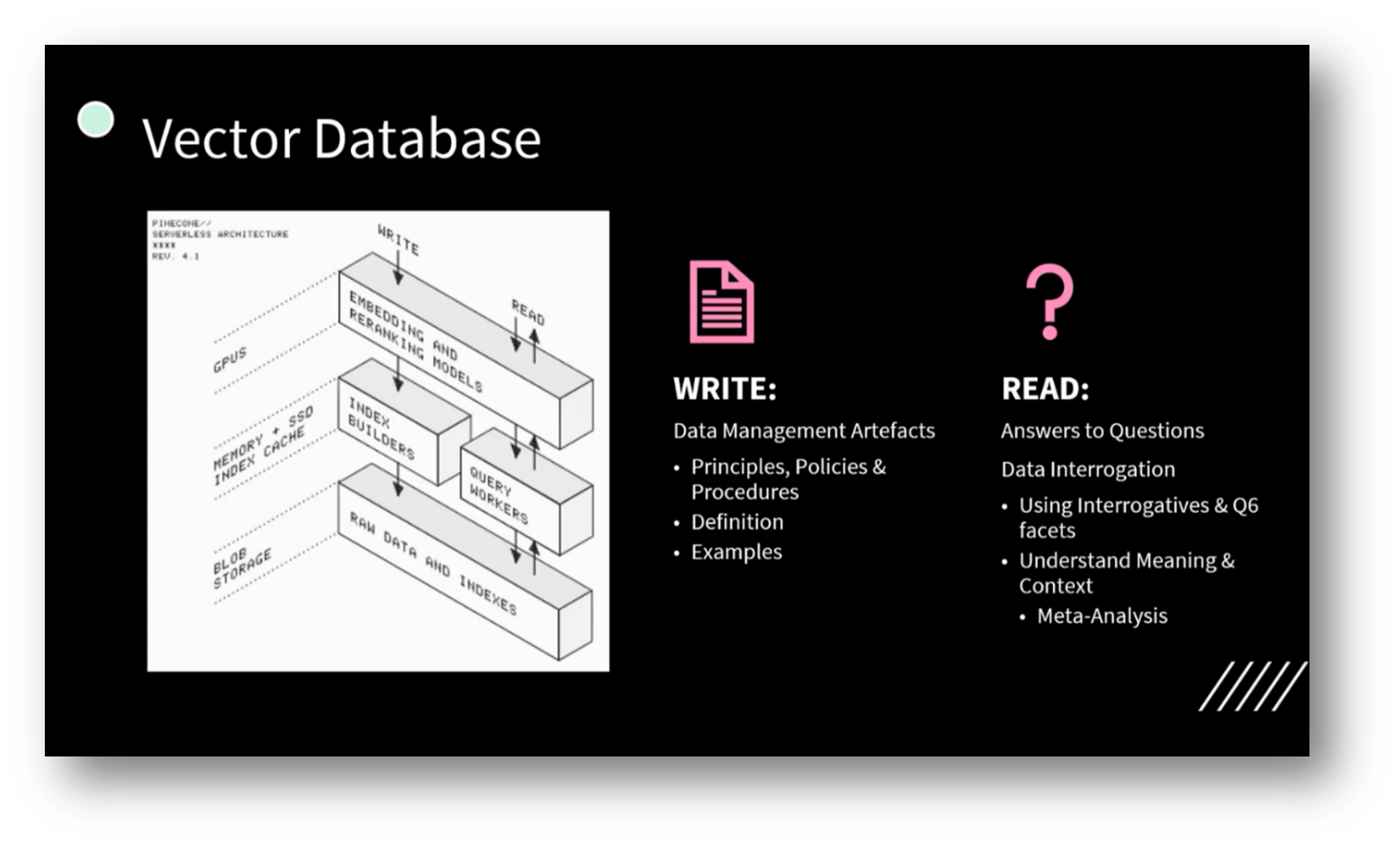
Figure 30 Vector Database
Implementing a Vector Database with Google Drive and Open AI
The project focuses on building a vector database that facilitates interactive conversations using data stored in Google Drive. A trigger is set up to activate when a new document is added, allowing a chatbot to engage with the content almost immediately. The process involves extracting the document, downloading it, and converting it into embeddings using OpenAI's tools before storing it in the vector database.
Howard shares that while implementing this system required navigating various API setups for Google Drive, OpenAI, and the vector database, it remained cost-effective, with initial expenses starting at $5 and decreasing to $3 after data loading. This demonstrates a successful integration of technology for effective data interaction.

Figure 31 n8n Orchestrations
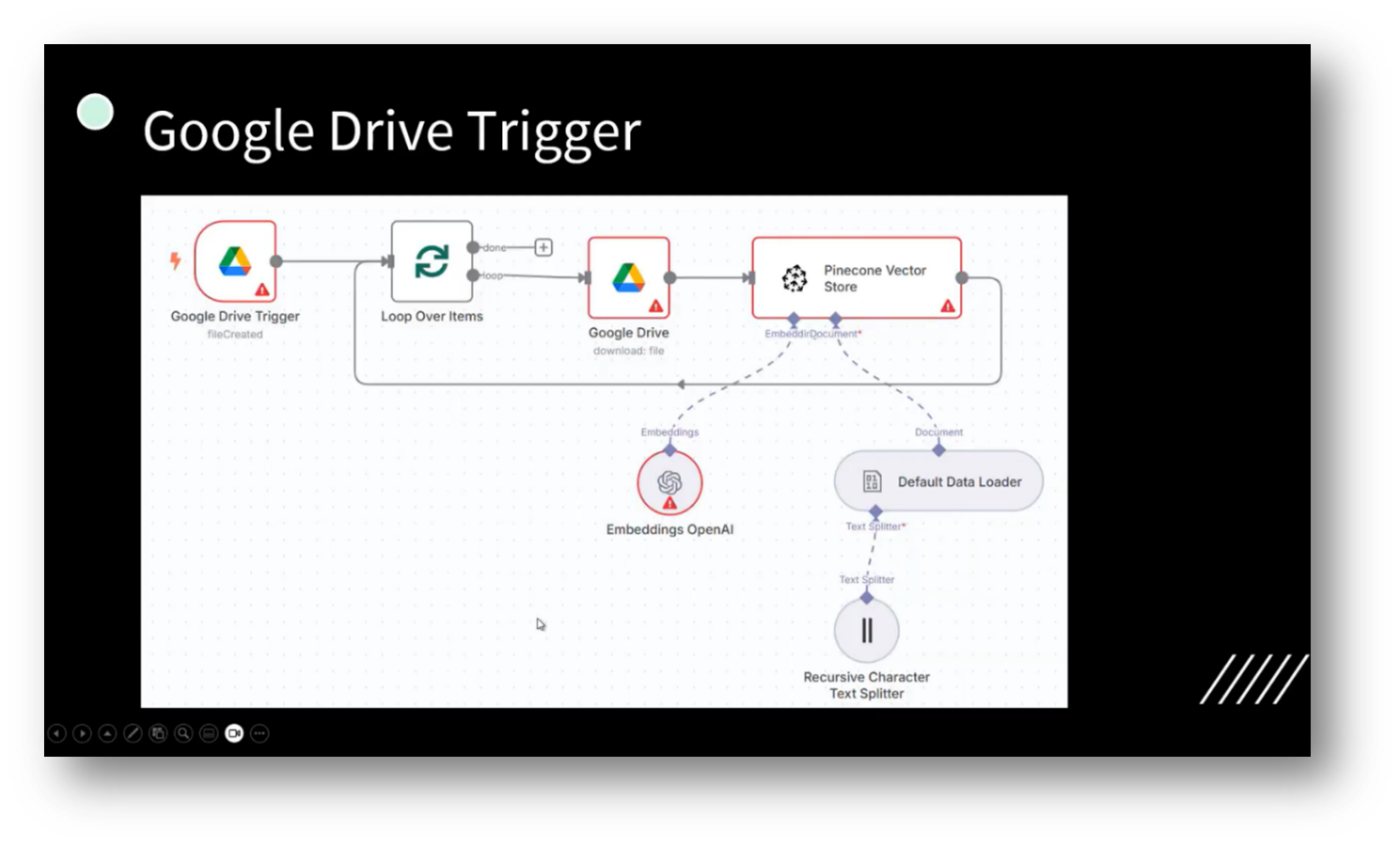
Figure 32 Google Drive Trigger
Figure 33 Inserting Artefacts
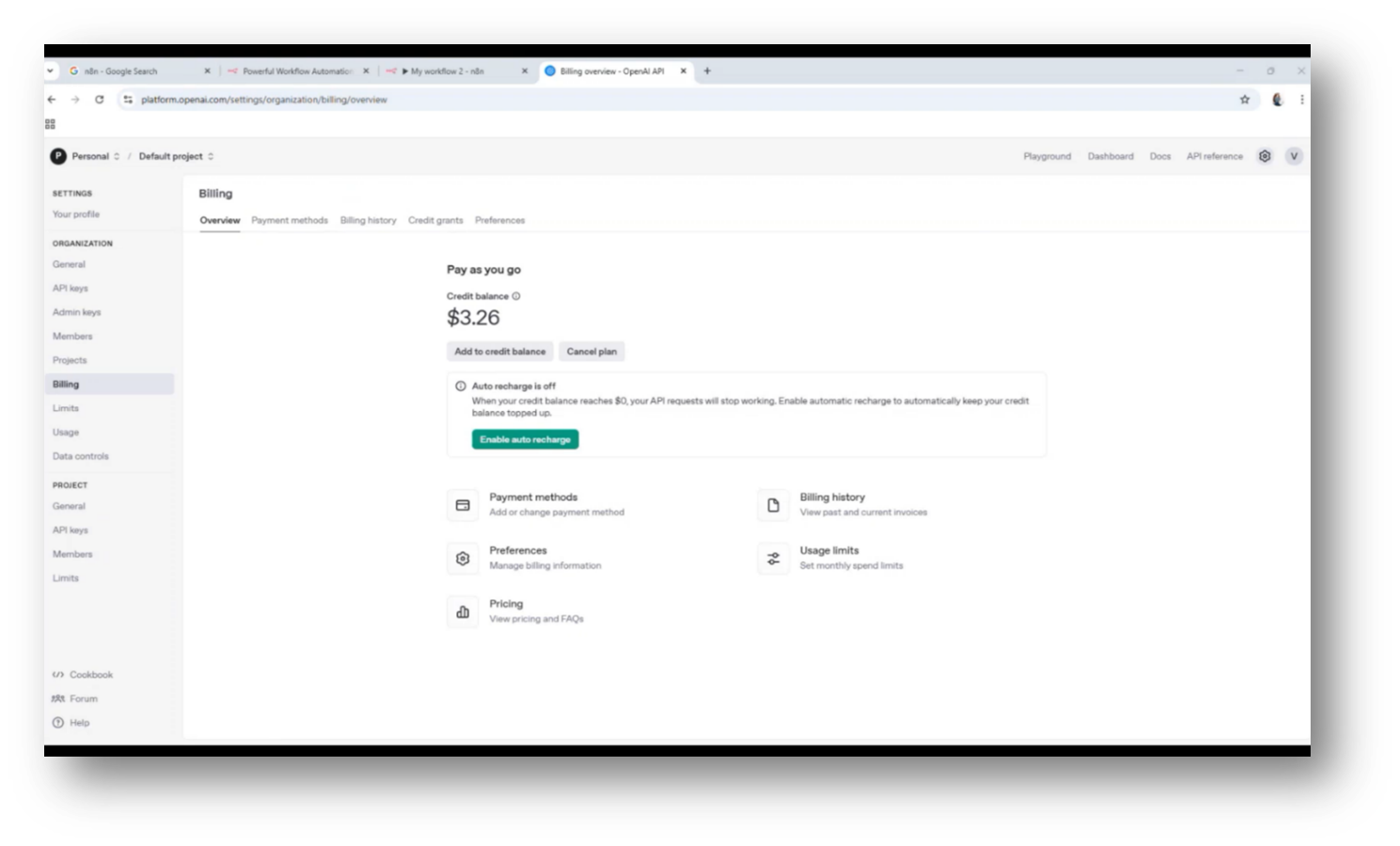
Figure 34 Billing for Open AI
Building a Chatbot: A Step-by-Step Guide
The process of building a chatbot involved simply asking it to create the code, which it successfully provided, followed by debugging assistance when issues arose. Howard specifically instructed the Chatbot to format responses with numbered items and in bold, enhancing clarity and usability. He also integrated the webinars into a searchable database, where users can ask questions about topics such as data careers and receive direct responses.
Howard set up a Retrieval-Augmented Generation (RAG) system to ensure that if the chatbot cannot find an answer, it will clearly state its inability rather than fabricate information, thus avoiding confusion and embarrassment. This approach has allowed the system to provide accurate responses while handling inquiries effectively.
In his demonstration of the Chat Assistant, Howard navigated to his Google Drive to locate a document related to a conceptual data model. After finding the document, he moved it to an ingestion platform for processing. Howard then initiated an ingestion routine, which involves downloading the file, creating necessary embeddings, and relocating the file to a designated directory to prevent duplicate processing.
This workflow efficiently manages document ingestion while ensuring the integrity of the files in Google Drive. The process concludes with the user expecting the document to soon be removed from the Drive after successful ingestion.
Figure 35 Working with Lovable
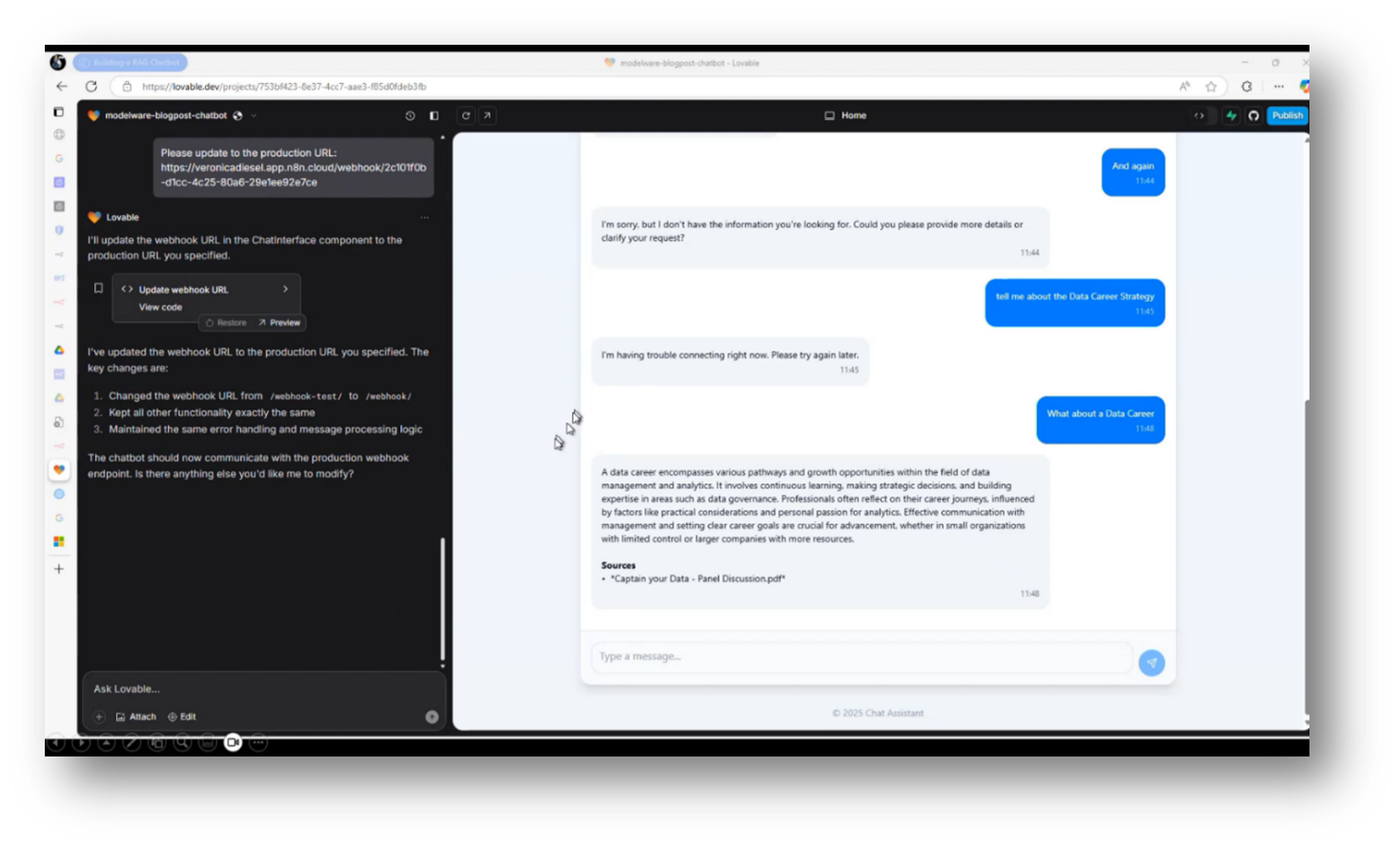
Figure 36 Chat Assistant Pt.4
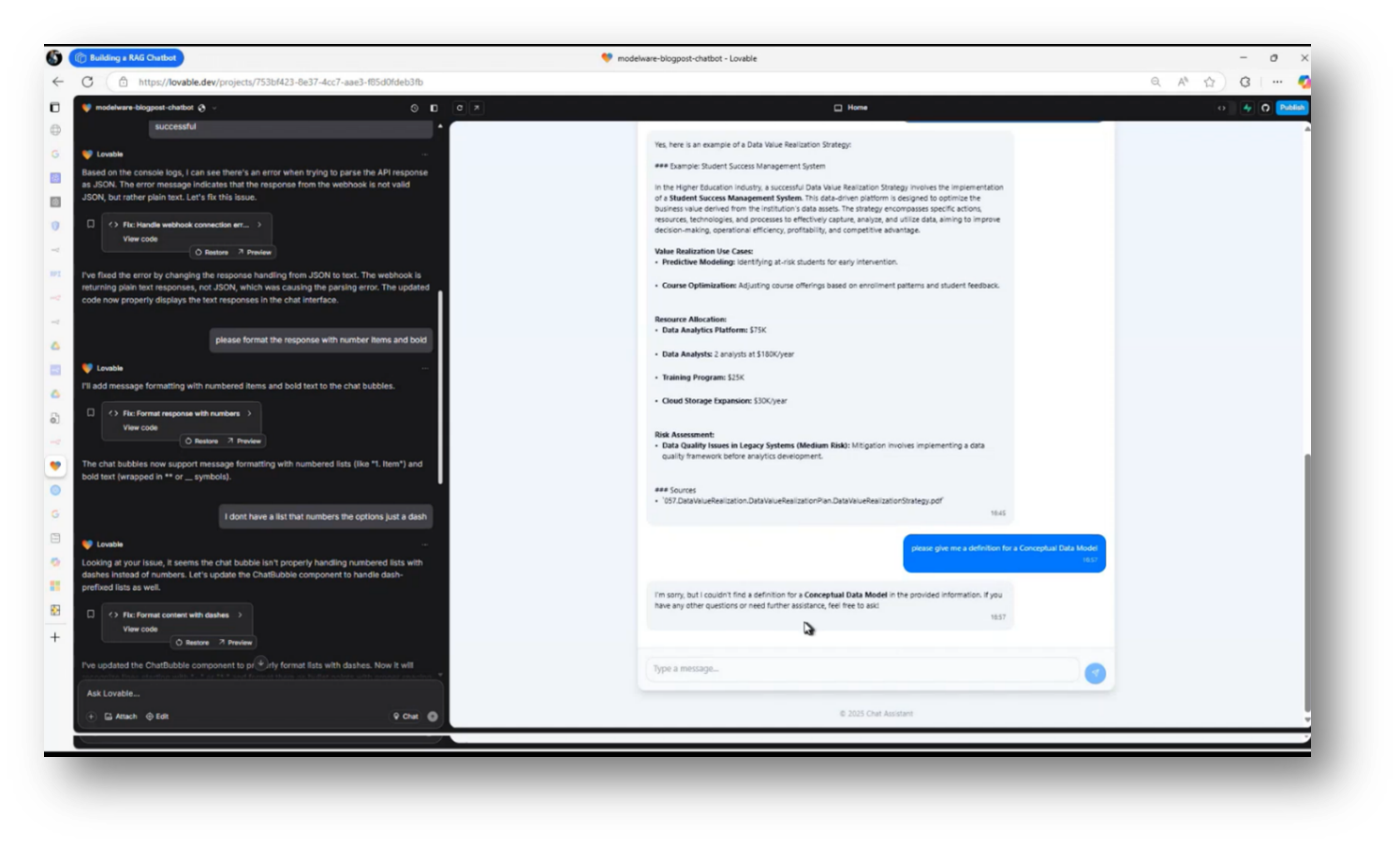
Figure 37 Chat Assistant Pt.4
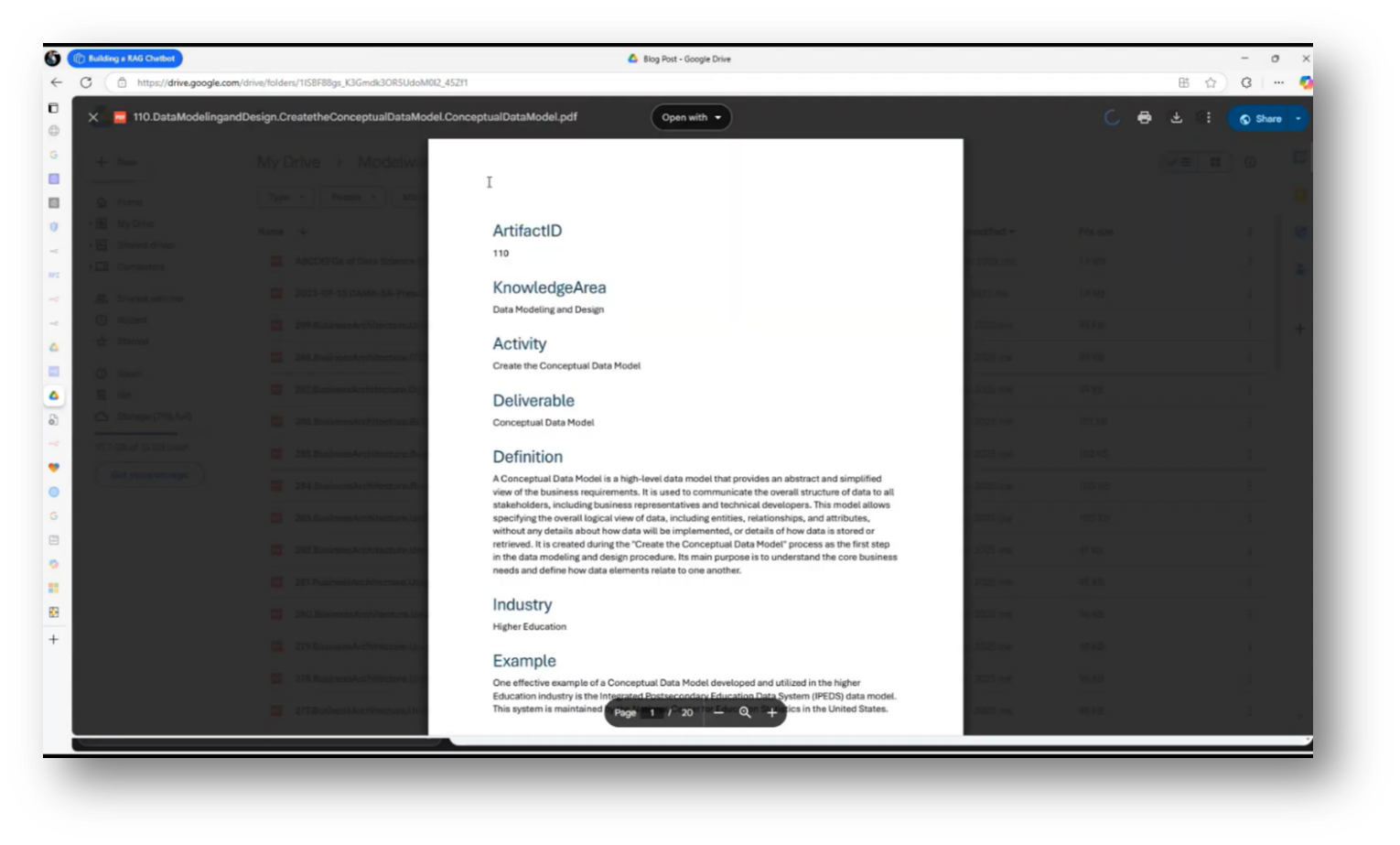
Figure 38 Referring Artefacts
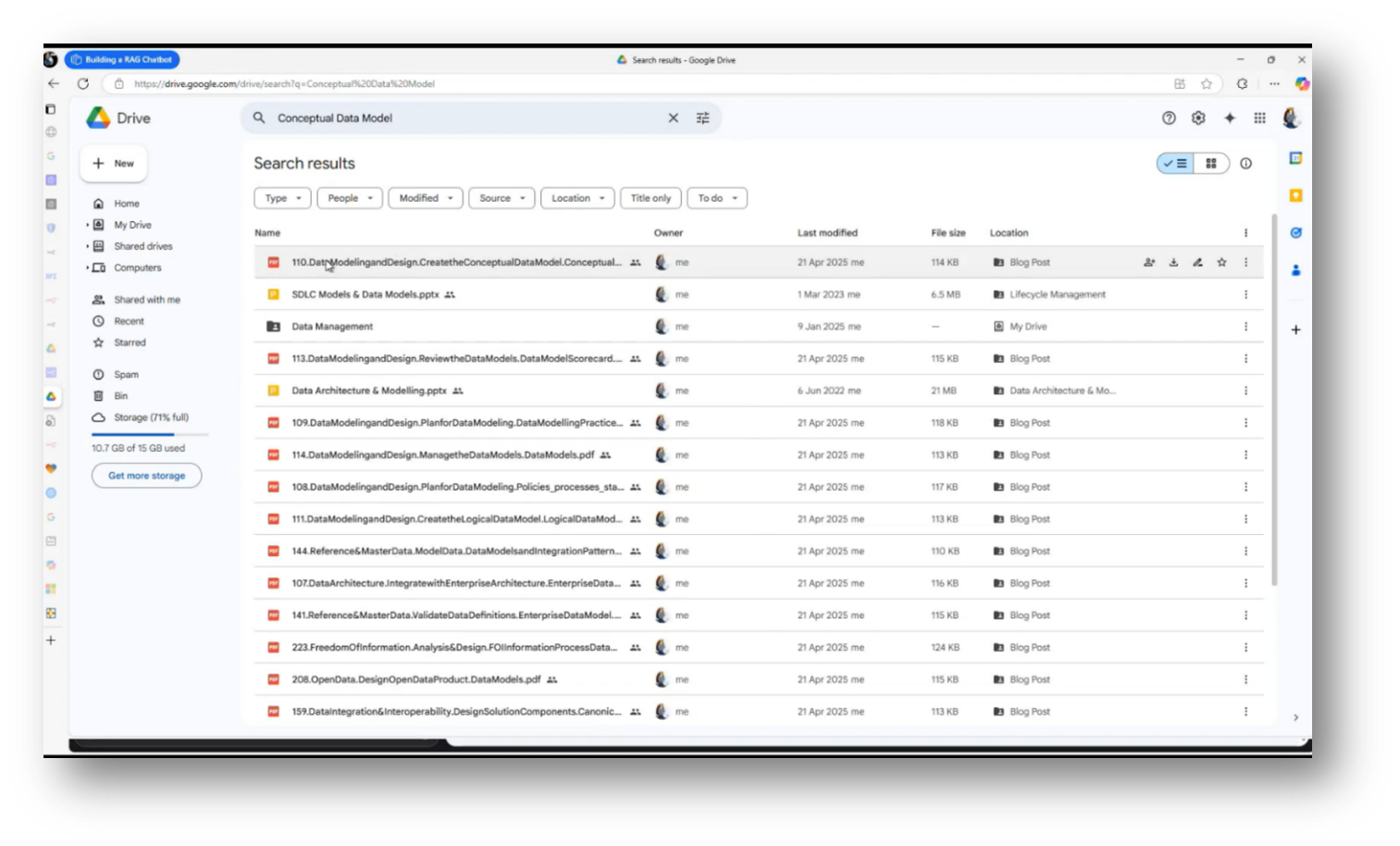
Figure 39 Google Drive Housing Artefacts
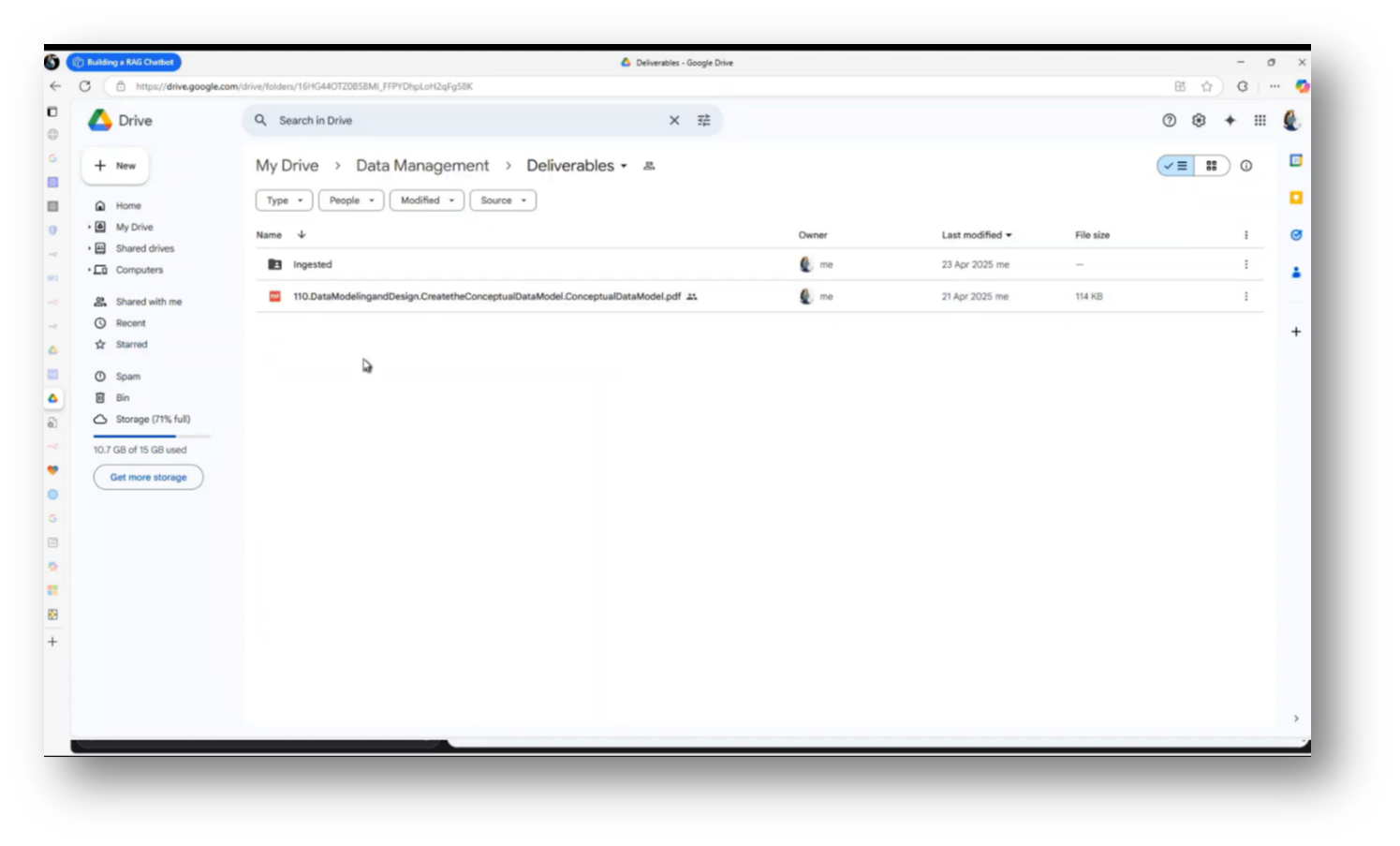
Figure 40 Moving over Artefact to the Chat Assistant
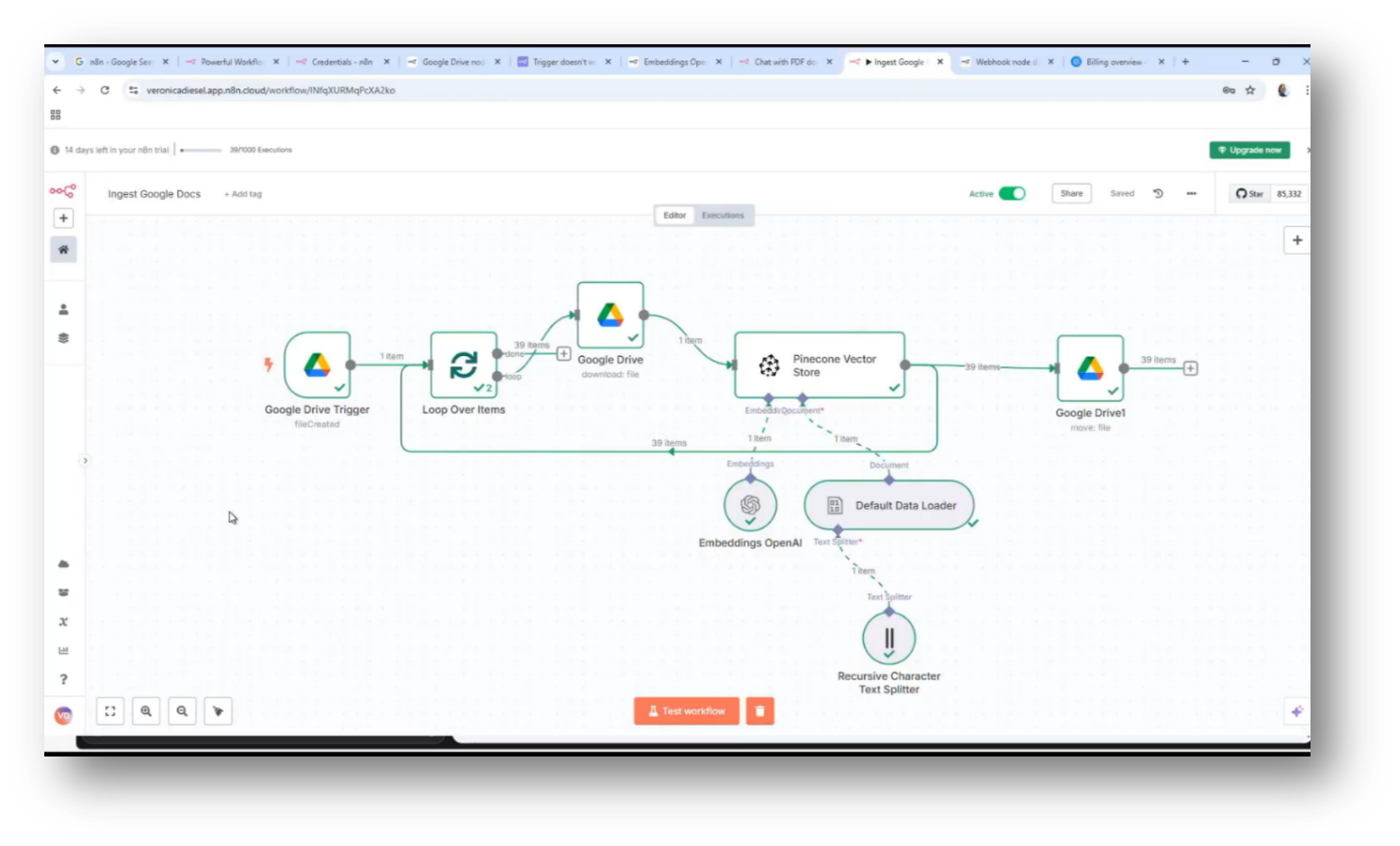
Figure 41 Chat Assistant working with Google Drive
Data Models and Information Management in Document Management
Howard focuses on the development and management of a Conceptual Data Model, emphasising the importance of visual representation through graphs to enhance understanding and accessibility of information within documents. An attendee highlights the potential for chunking documents into nodes for easier retrieval of relevant data and emphasises the need for effective Records Management to address issues such as information decay.
The challenges of model augmentation and managing vector databases are addressed. This enables the replacement and retirement of outdated documents, ultimately providing greater control over the data environment compared to existing solutions, such as ChatGPT.
Howard highlights the importance of understanding the temporal aspects of data, particularly in relation to when a document was created and any associated latency. He raises the question of whether answers to inquiries remain valid if the original document is deleted from the vector database, emphasising that while the definition of a conceptual data model remains unchanged, the direct linkage to a document may be lost. Additionally, an attendee mentions a strategy in the Chatbot design to avoid sourcing answers from the internet unless explicitly provided, reinforcing the need for a strong internal knowledge base, including Data Governance, and the potential for extending chatbot functionality to include web-sourced examples when necessary.
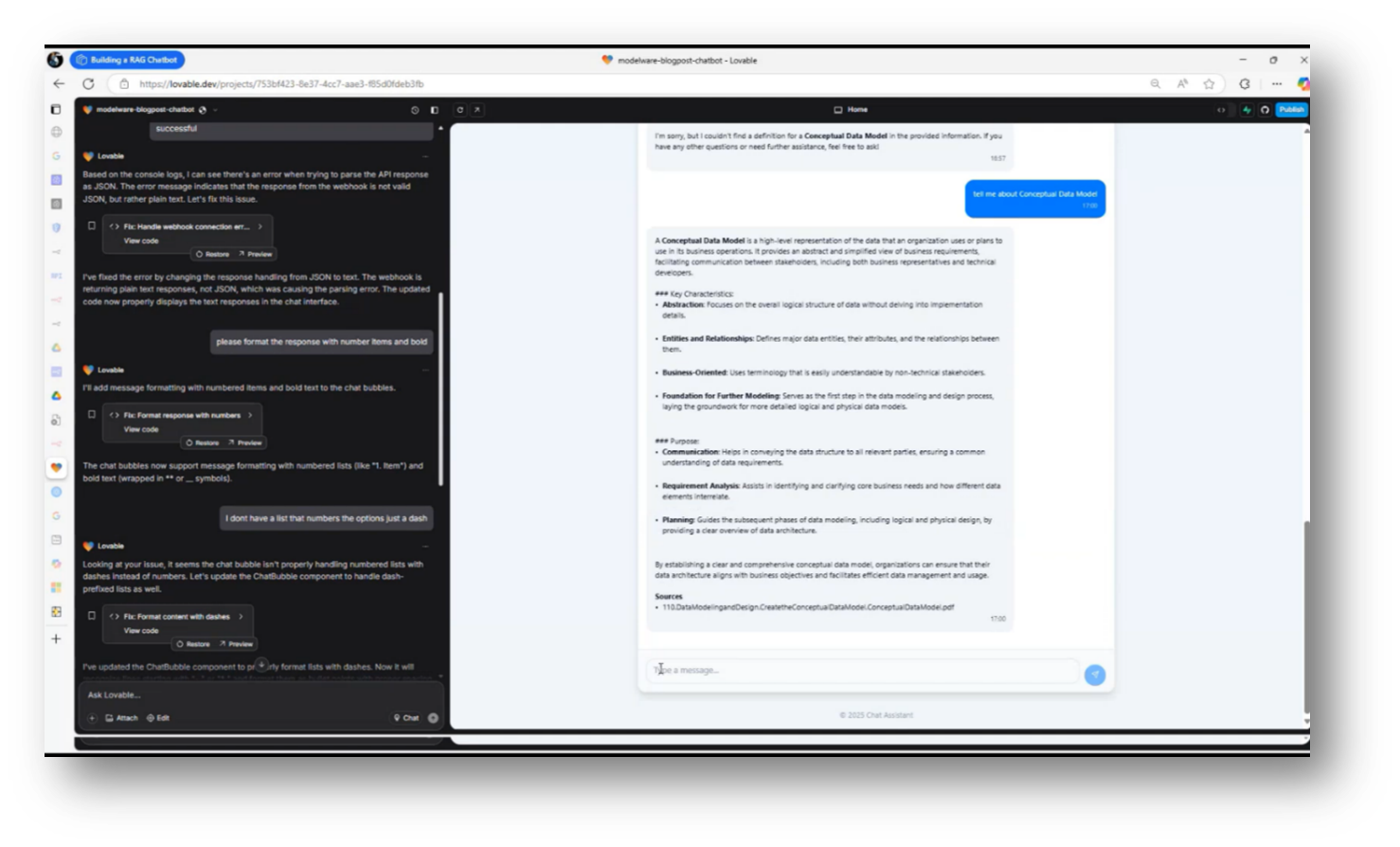
Figure 42 Chat Assistant Pt.5
Configuration and Execution of Rules in Chatbots
Configuring personality rules and external parameters for a chatbot primarily involves managing issues such as internet access and hallucinations that may arise during interactions. The user has been independently building and integrating these rules into the chatbot, utilising XLS for data handling.
Key elements include the webhook for response aggregation, managing unanswered queries with a simple acknowledgement, and controlling hallucination levels through configurable parameters. The process involves analysing execution nodes for prompts and responses, ultimately allowing for dynamic rule adjustments within orchestration to enhance chatbot functionality, including data transformation and flow control.
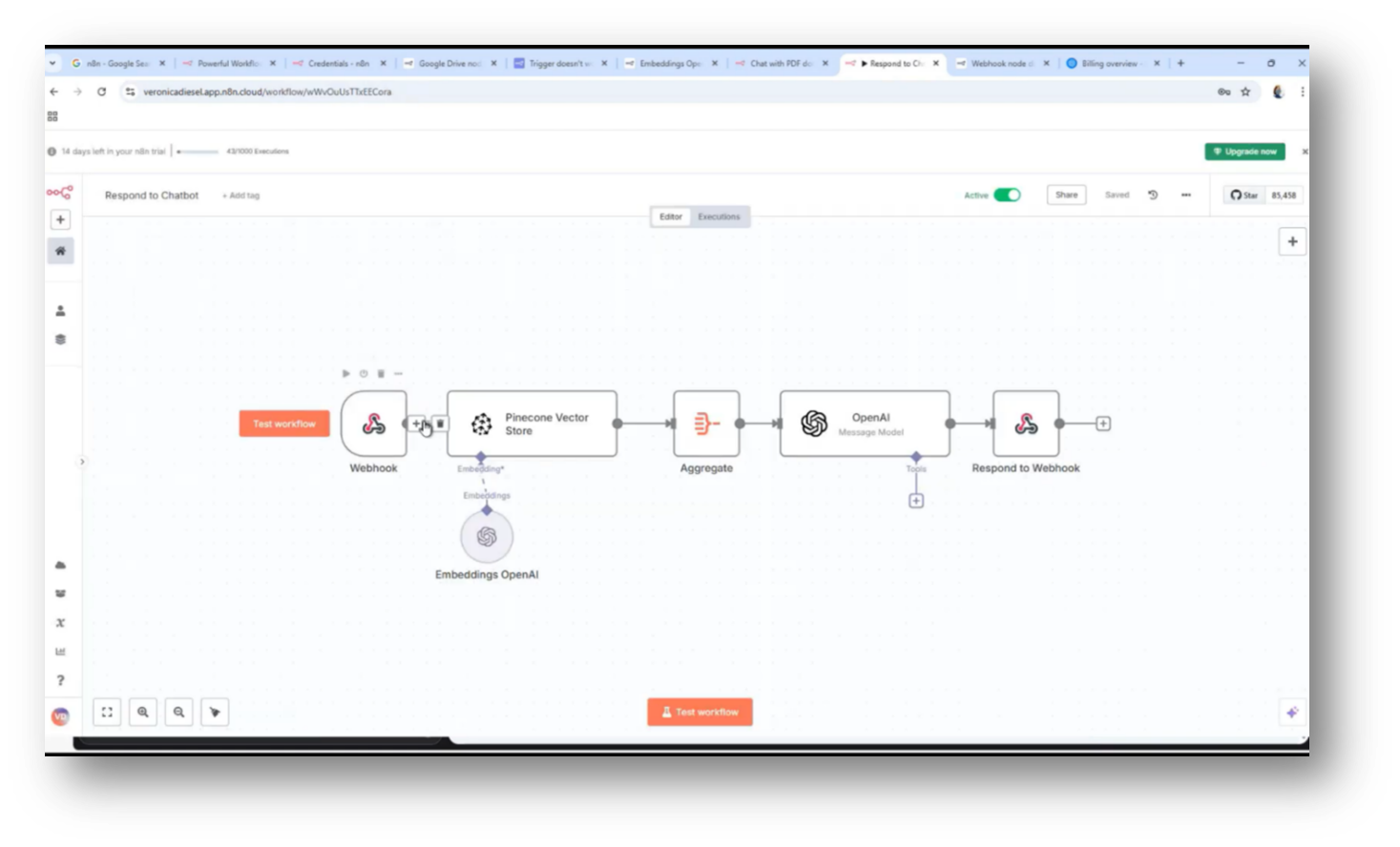
Figure 43 Respond to Chatbot
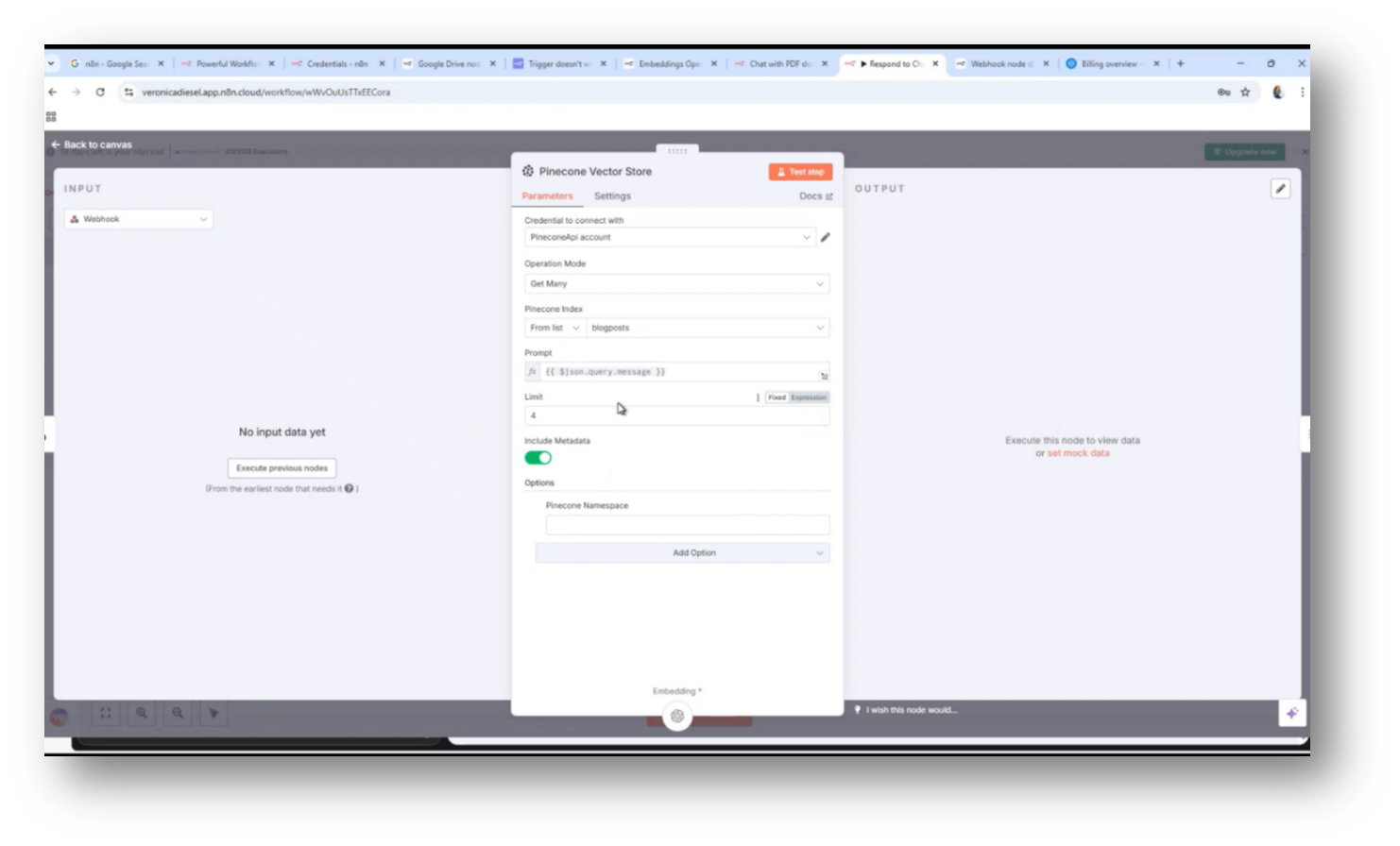
Figure 44 Workflow
Figure 45 Workflow Pt.2
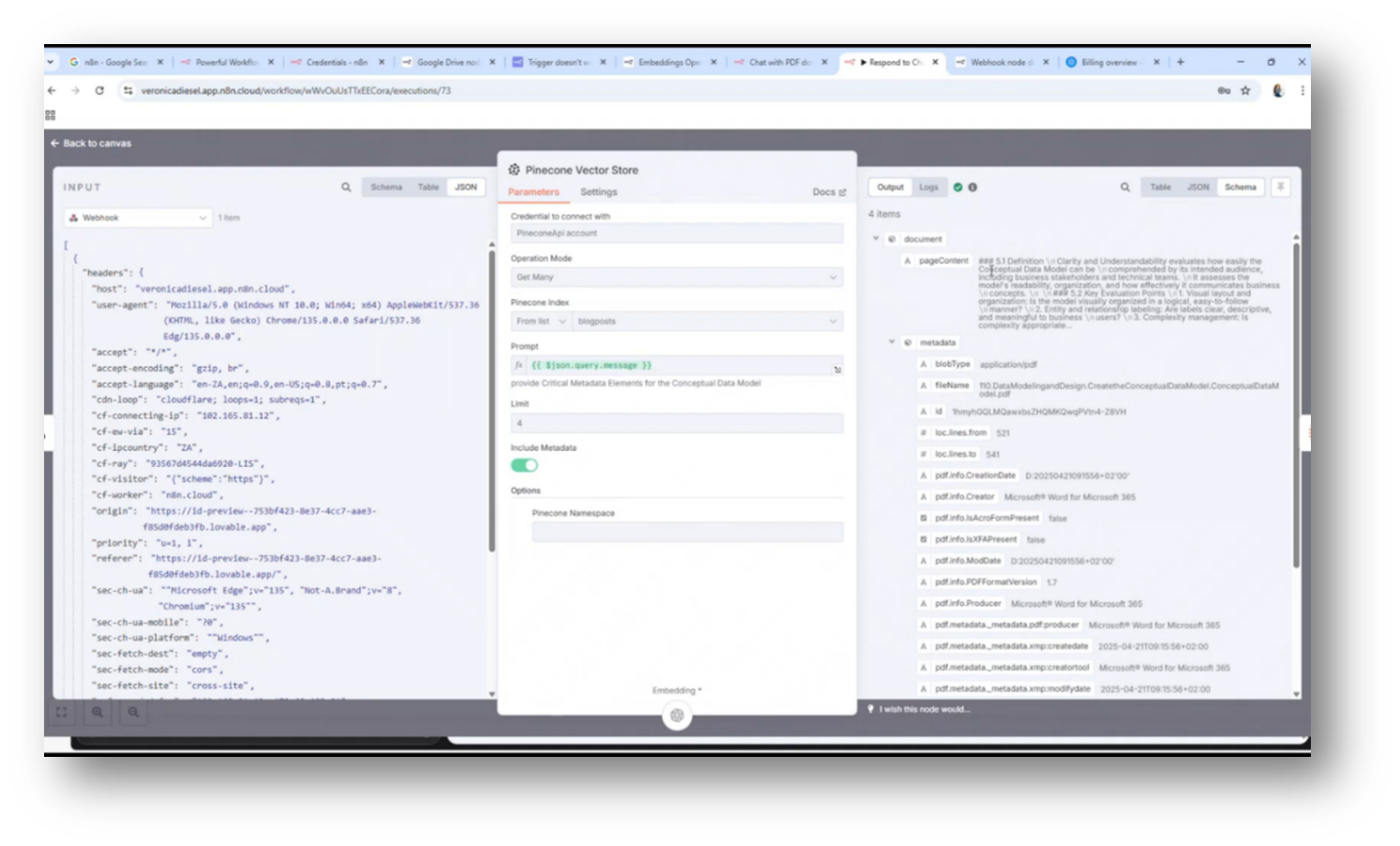
Figure 46 Workflow Pt.3
Data Value Recognition and Budget Analysis in Governance Programs
Managing a governance program budget revolves around the related processes for data value realisation. Howard then highlights their experience in checking deliverables and confirming the existence of a program budget, noting the absence of a value realisation artefact. He utilises a Chatbot to gather information on data value realisation strategies, with insights linked to Power BI, which effectively displays metrics such as improved graduation rates and student retention.
Howard emphasises the importance of Data Quality and the ability to observe relevant information in a centralised manner, enhancing visibility and reducing the risk of inaccuracies, particularly regarding document decay dates. Additionally, he is working on leveraging Power BI to better query and index their vector database for effective Data Management.
The process involves cutting up a PDF to extract various pieces of information, including the creation date, the person who generated it, and the document's author, all of which are stored in a vector database. While the specific embeddings cannot be directly interrogated, it is possible to examine the indexes and content to understand the source and associated timestamps of the information. However, there is an ongoing challenge in accessing the Pinecone database, which complicates the retrieval process.
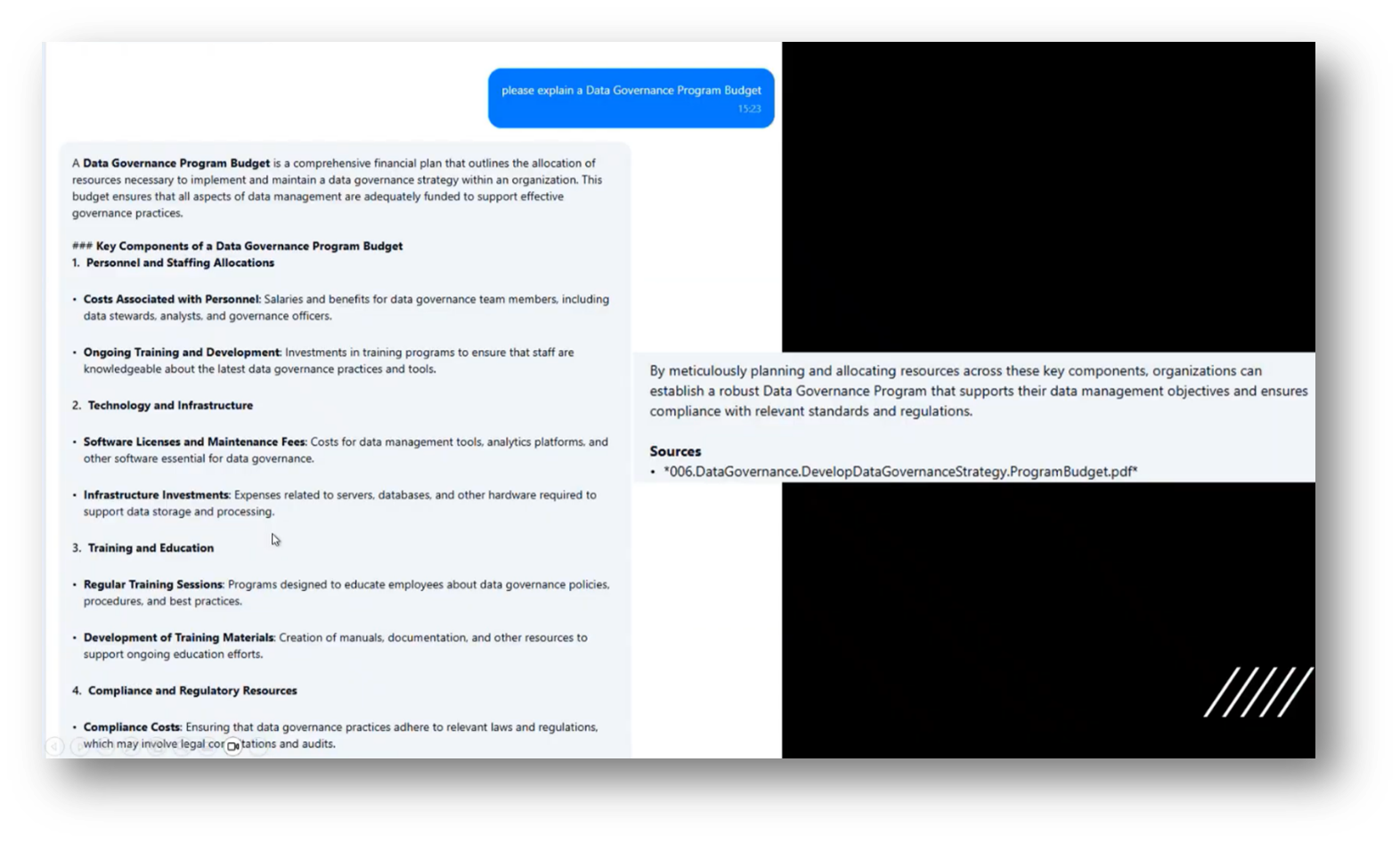
Figure 47 Chat Assistant Responding to Questions
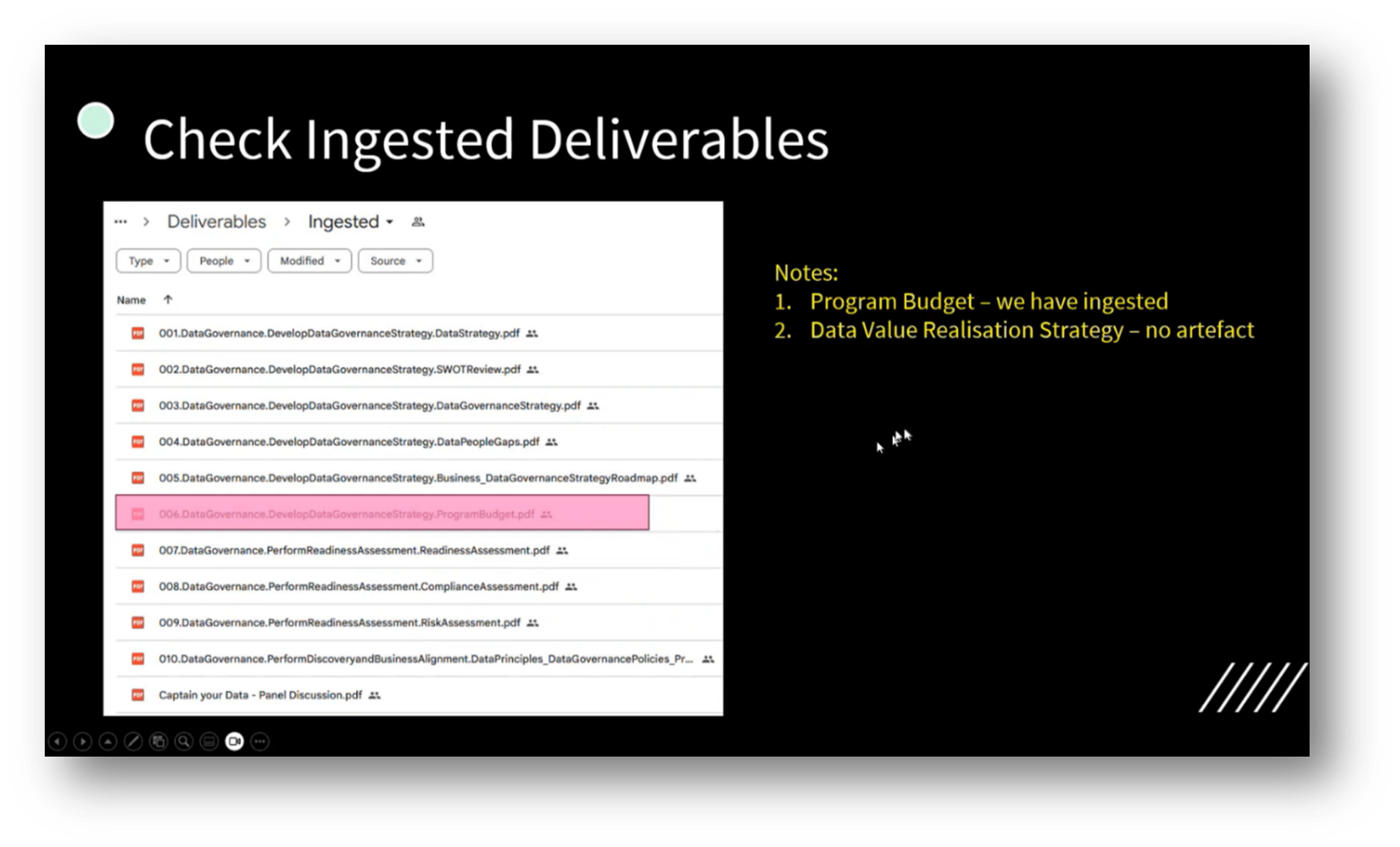
Figure 48 Check Ingested Deliverables
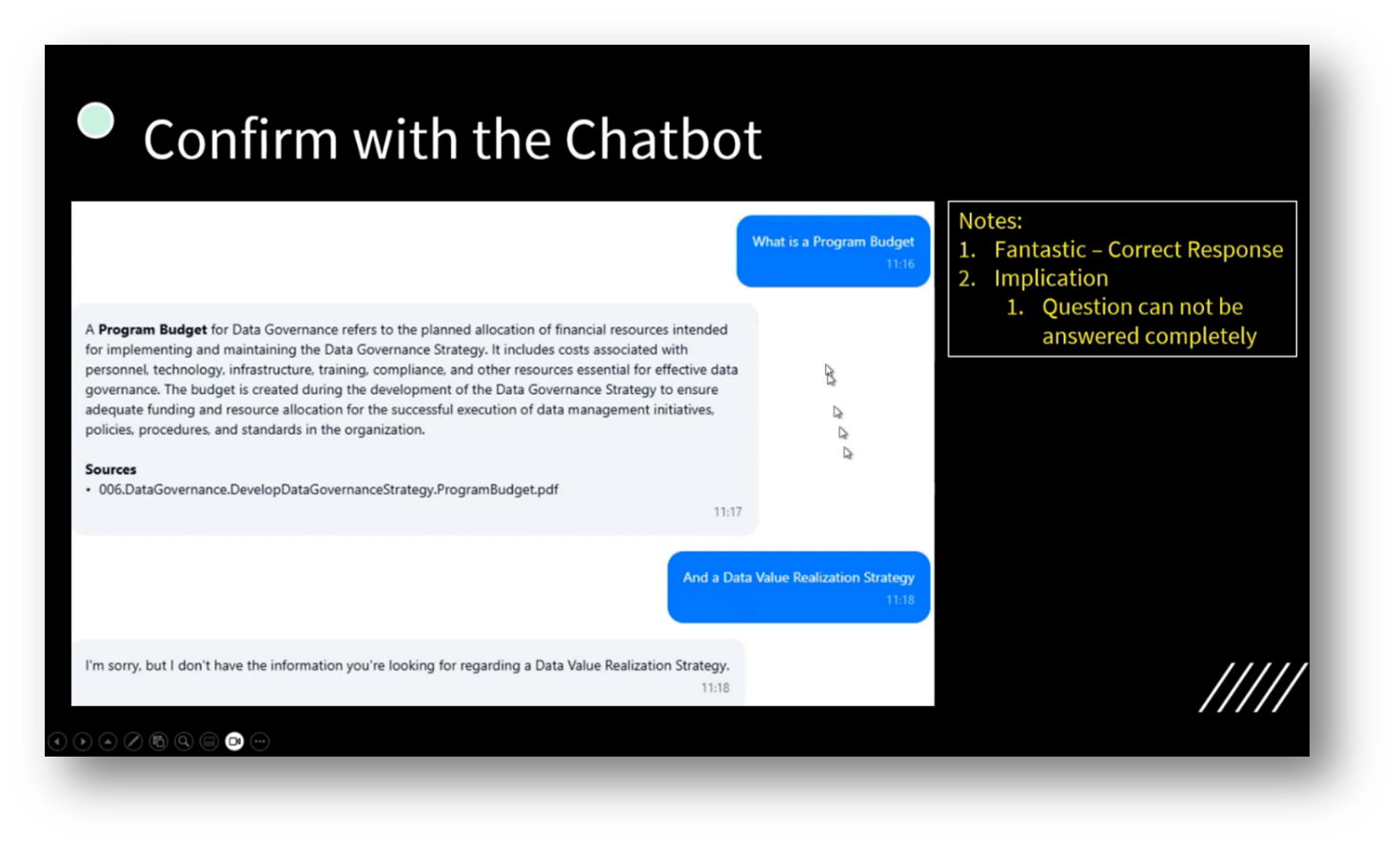
Figure 49 Confirm with the Chatbot
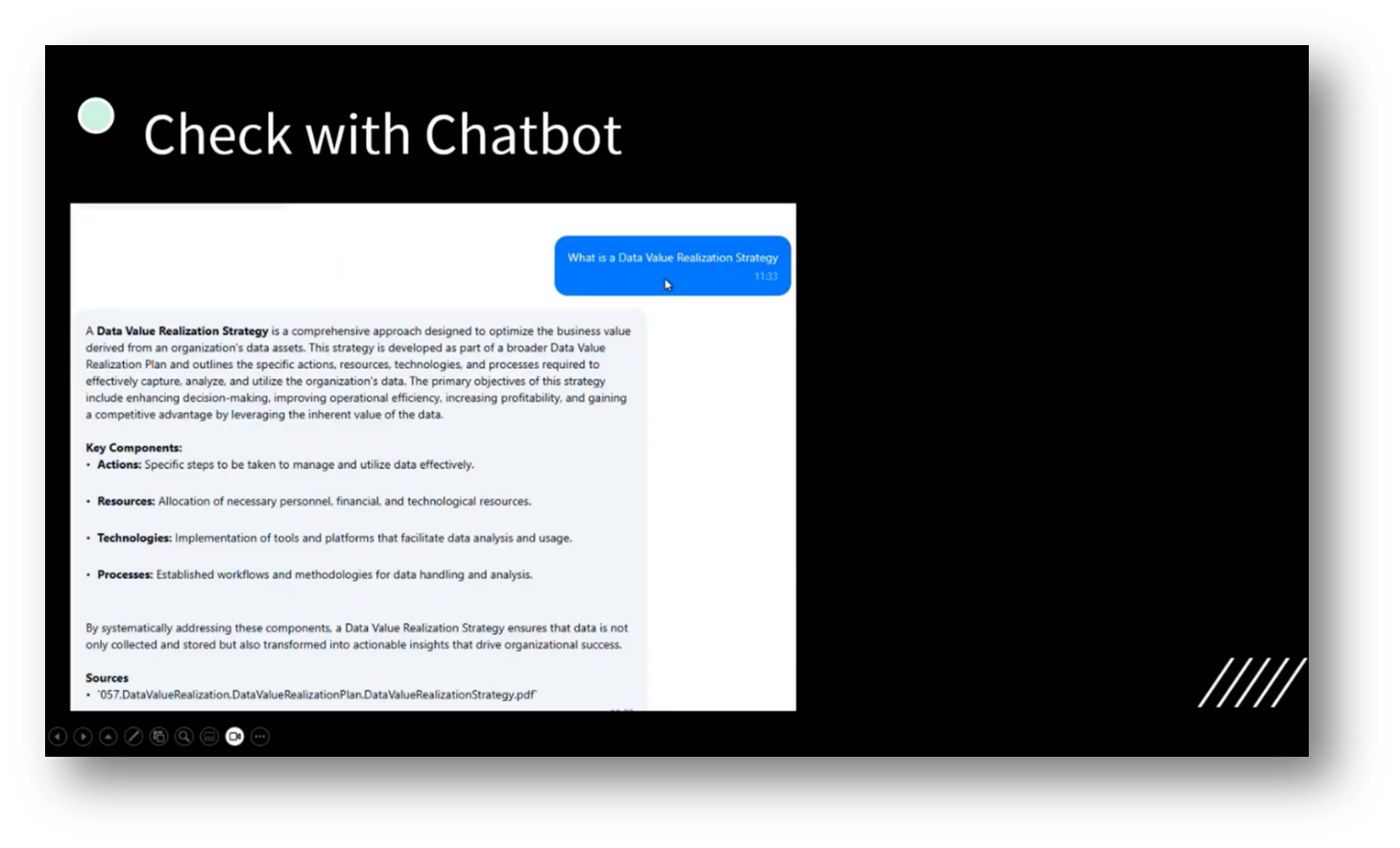
Figure 50 Check with Chatbot
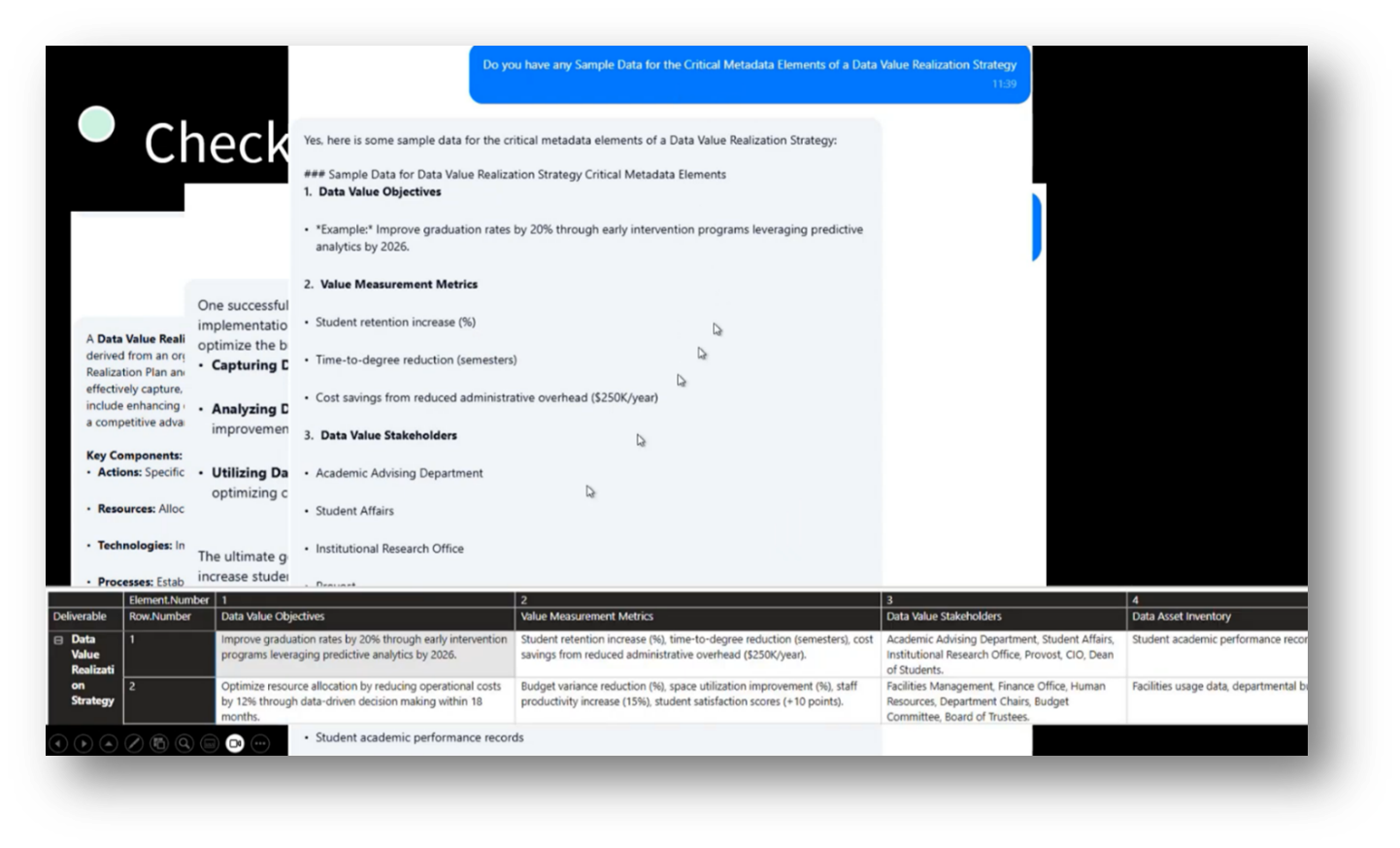
Figure 51 Chat Assistant Sourcing Answers
Data Computation and Reasoning Techniques in AI
The use of separate workflows for data pre-computation in generating deliverables revolves around utilising prompts to communicate with AI models, such as getAnthropicTechniques. Howard describes the extensive work involved in preparing data, including defining industry-specific terms and organising various components into a structured format suitable for integration into deliverables such as PDFs and spreadsheets.
Howard highlights the process of refining prompts to enhance the accuracy of the AI's responses, including adjusting parameters such as temperature settings to control the creativity of the output. Comparisons are made to other reasoning systems, such as Prodigy, noting the potential for advanced inferencing based on graph theory. Additionally, the importance of ensuring the AI does not fabricate data and adheres to established procedures is emphasised.
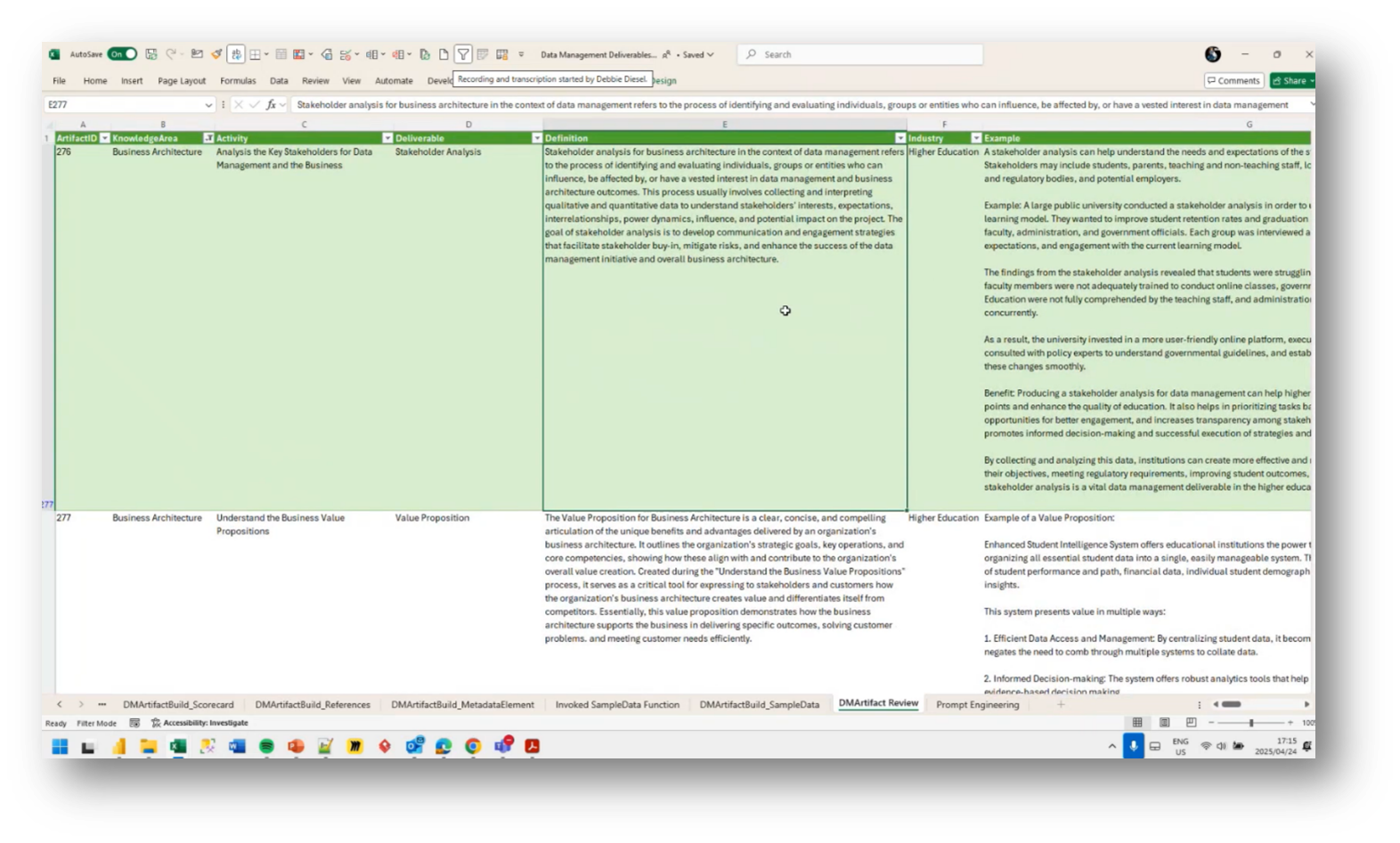
Figure 52 Data Management Deliverables
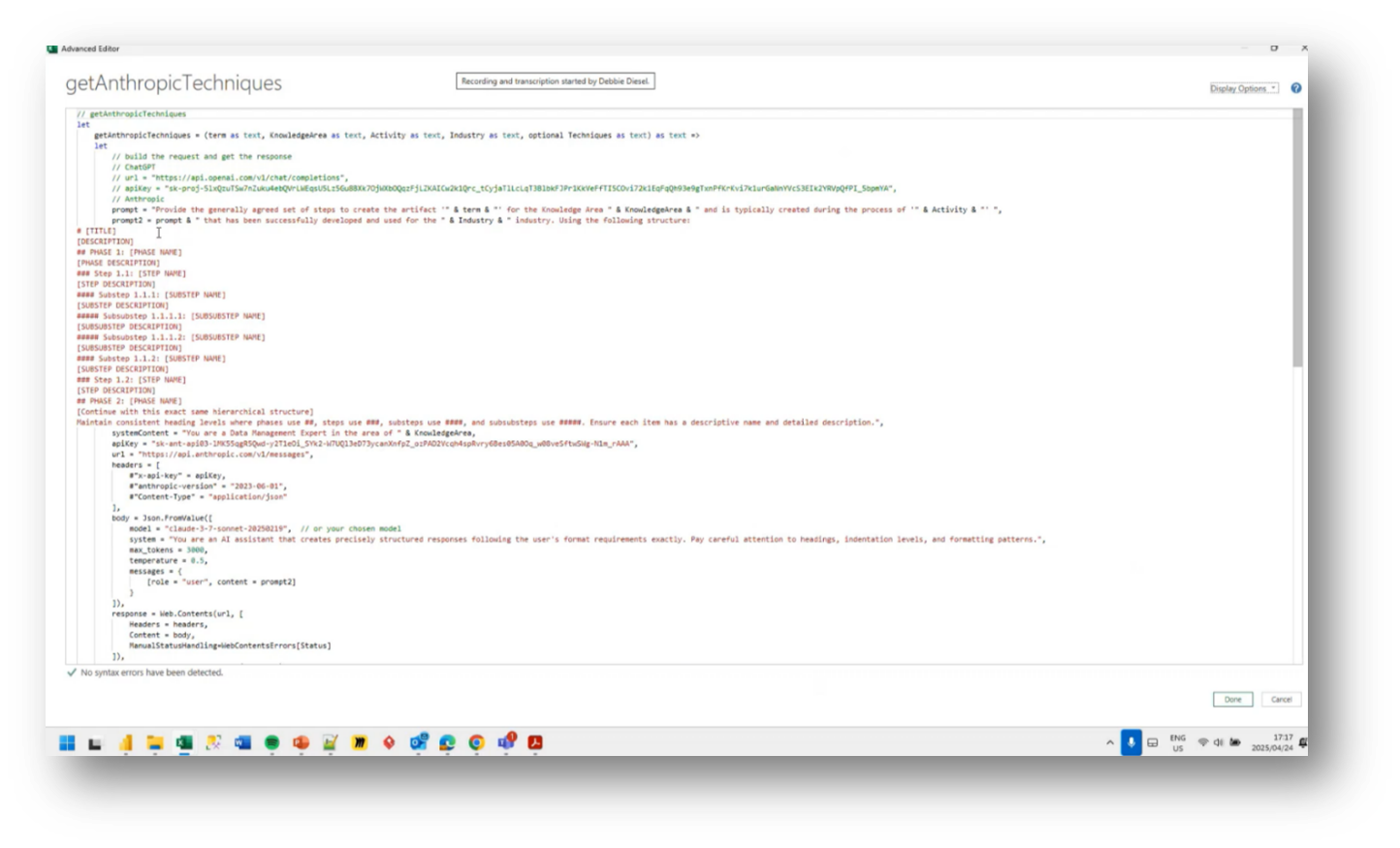
Figure 53 getAnthropicTechniques
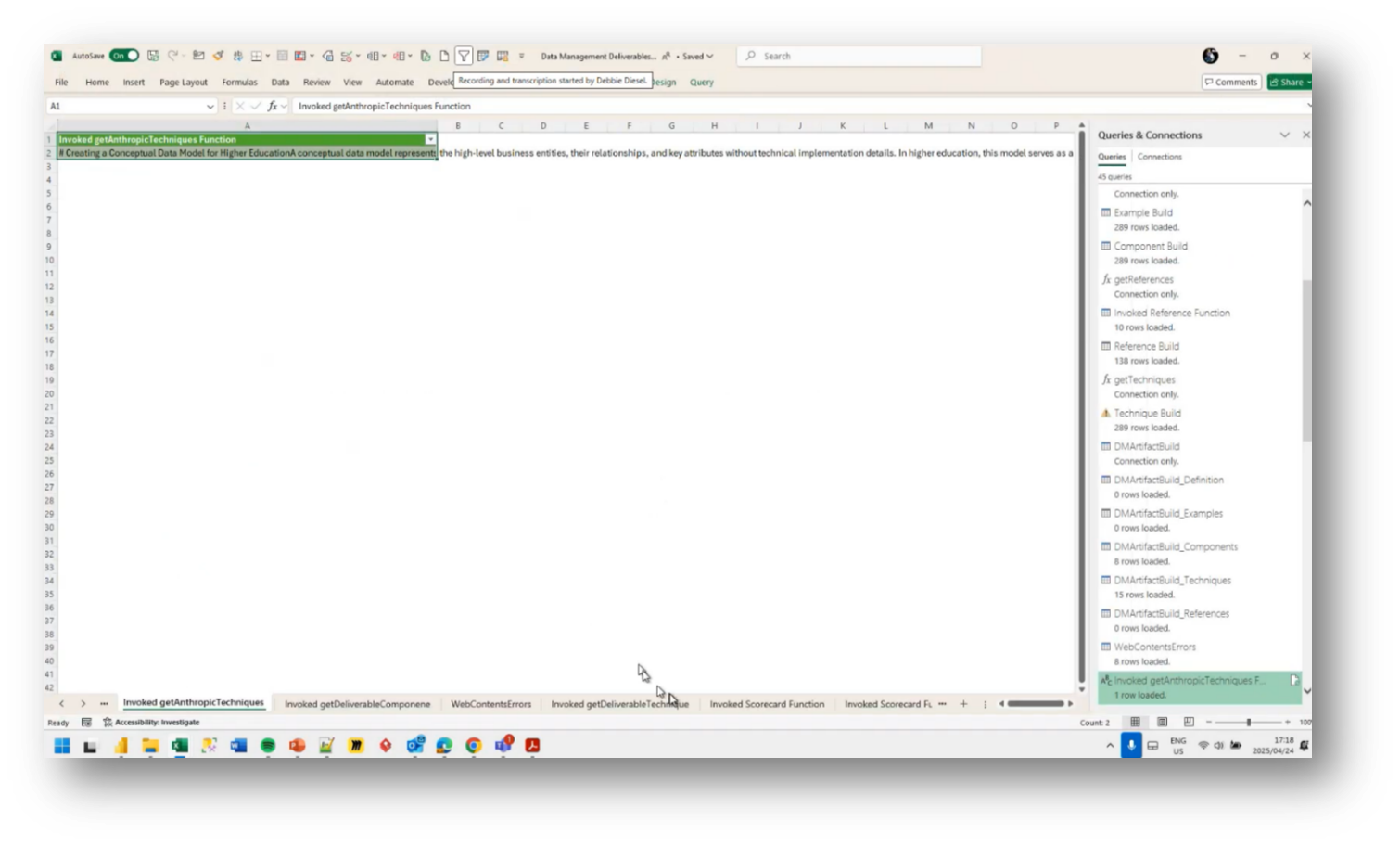
Figure 54 Applying getAnthropicTechniques
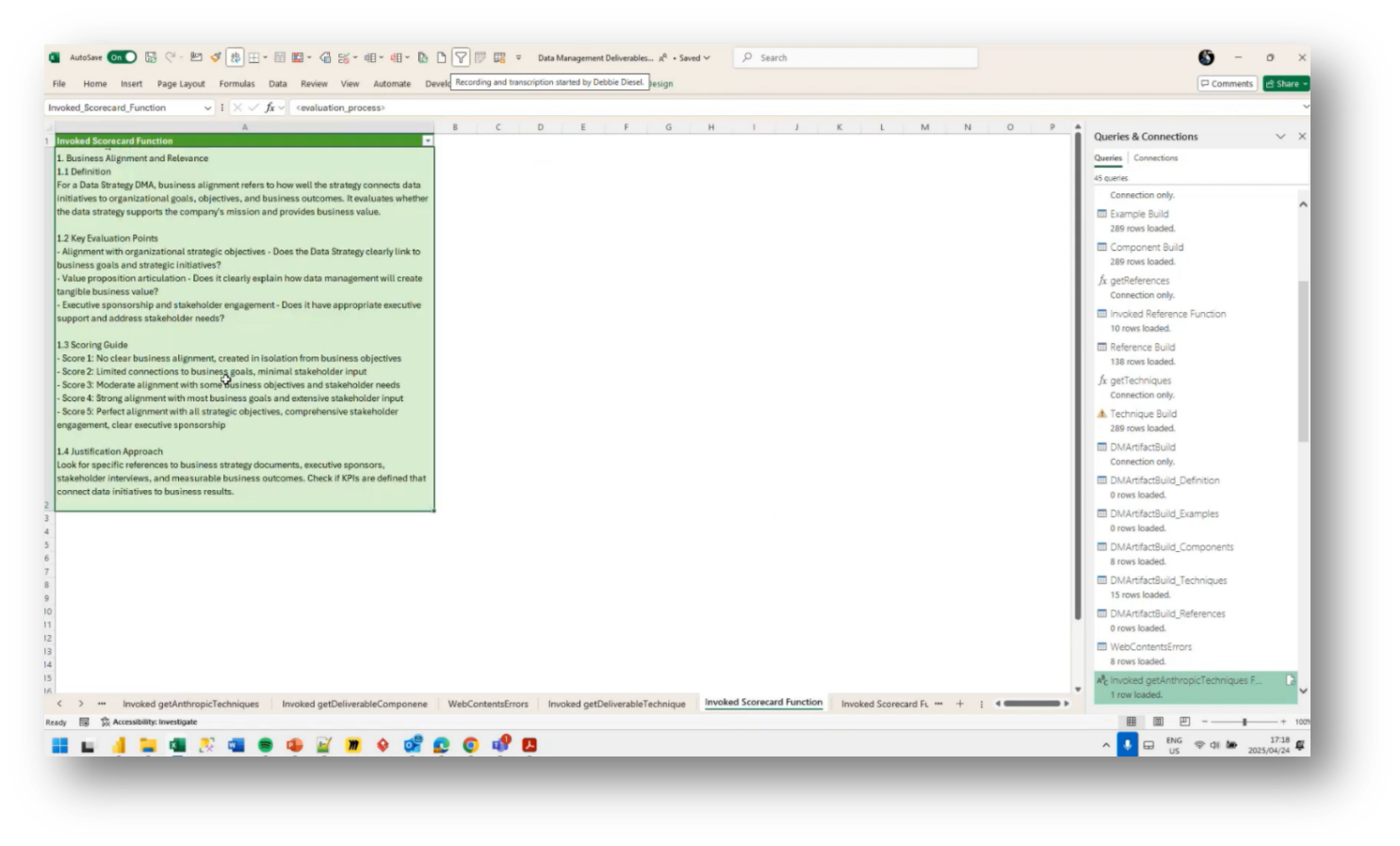
Figure 55 Sourcing Information from Data Management Deliverables
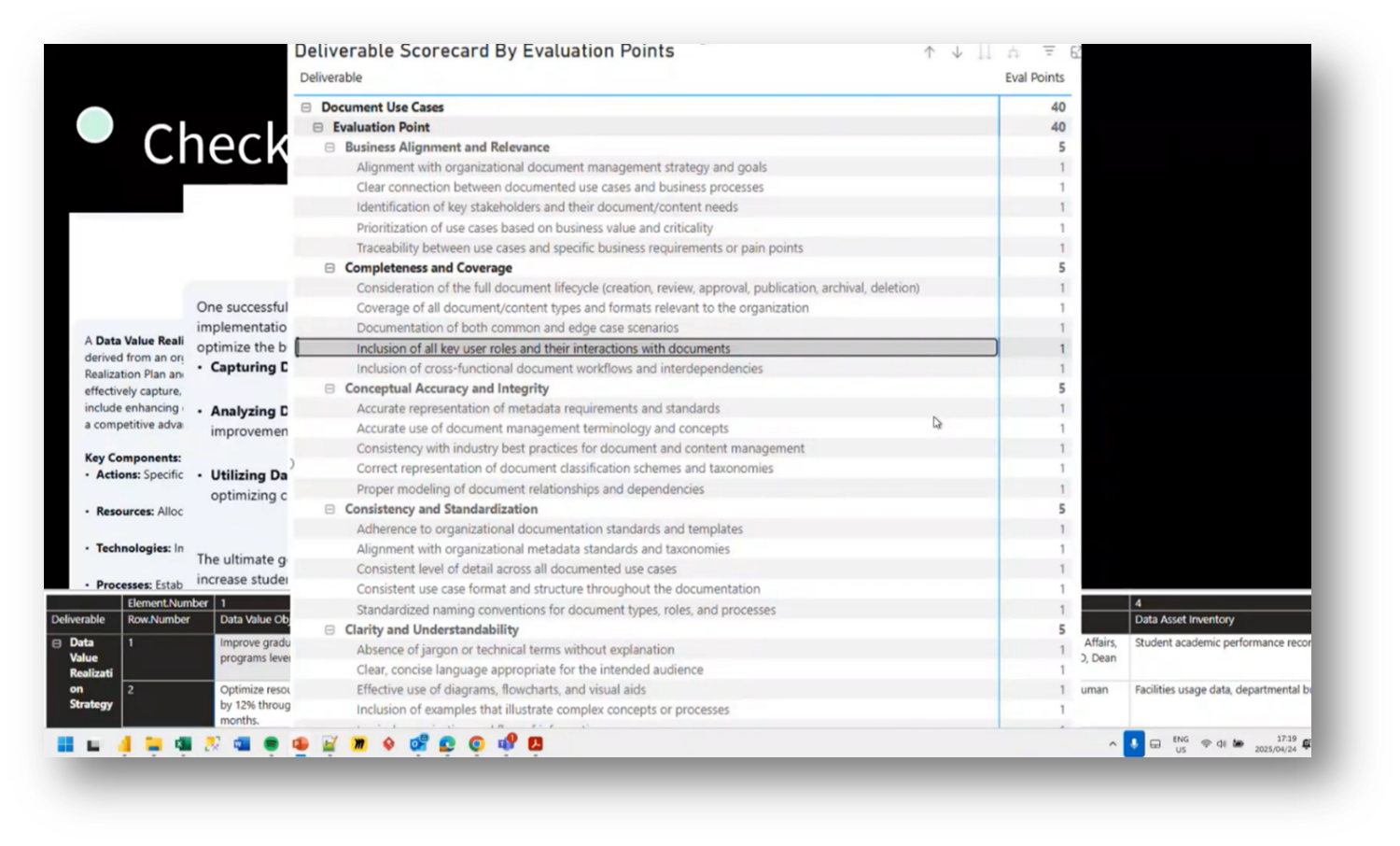
Figure 56 Deliverable Scorecard by Evaluation Points
Future of Data Governance: From Control to Automation
The need to modernise Data Governance by moving away from traditional command-and-control methods centres on utilising chatbots and Large Language Models (LLMS) to provide users with immediate answers and relevant data. Professor John Talbot emphasised the importance of minimising manual intervention and integrating Data Governance into automated systems, likening it to Auto Pilot, which enables users to access necessary information independently.
A key aspect of this approach involves conducting Metadata analysis to inform users about the data available, its quality, and the processes for acquiring new datasets. Additionally, the system would provide feedback on Data Quality issues and guide users in understanding and addressing these challenges, thereby empowering data scientists to make informed decisions without being constrained by bureaucratic processes.
An attendee relates the project to the transition from a "fly-by-wire" approach, where a pilot maintains control of an automated aircraft, to a "governed-by-wire" model, which resembles unmanned drones with reduced human oversight. The focus is on developing a Small Language Model (SLM) for the Data Management domain to build a comprehensive ontology that enhances governance and trust through increased automation and protection. While individuals seeking insights from data still need to engage with it directly, the "governed by wire" system promises to minimise manual intervention and streamline Data Management processes, ensuring that governance is more effective and automatic.
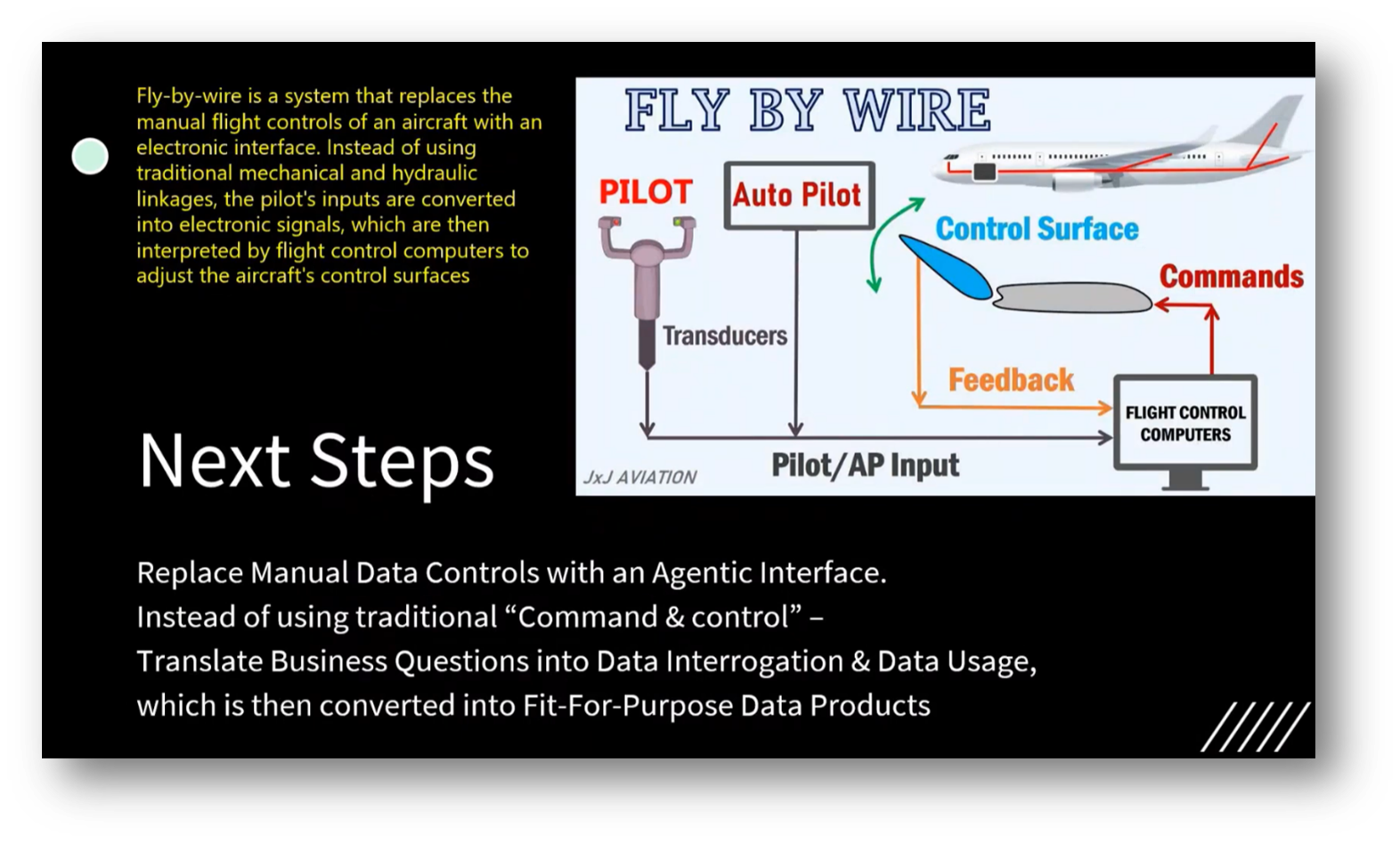
Figure 57 "Fly by Wire"

Figure 58 Fly & Govern-By-Wire Benefits

Figure 59 "Next Steps"
Data Governance and Compliance in Business Environments
Howard highlighted key points that included the need for improved data interrogation techniques to better understand business personas and the desire to transition from generic sample data to using actual business data for more effective testing. He also emphasised the importance of making Data Governance more accessible and user-friendly, allowing individuals to navigate and control their data without relying on manual oversight.
In a discussion on compliance monitoring within the Indian Ministry of Operations (MO), Howard noted the importance of proactive audits and data quality assessments. The conversation highlighted the need for a structured submission process, enabling assessors to review evidence within a specified exchange format, such as JSON.
The attendees and Howard then explored the benefits of utilising vector databases that support multi-tenancy, allowing individual companies to maintain data autonomy while ensuring compliance. A potential challenge mentioned was the time lag between document creation and audit reviews, which could lead to discrepancies if documents change. Overall, the dialogue underscored the innovative approaches to streamline compliance and ensure consistent oversight.
Creating a Business Vocabulary for Access to Documents and Shared Network Drives
John O’Gorman then demonstrated the process of examining discipline values within an organisation. Semantium has the ability to identify individuals in specific roles, such as John O'Gorman, who is located in office 2785 and works as an active consultant and information management specialist. John notes that information, including home addresses and resumes, is accessible, and documents can be attached for reference.
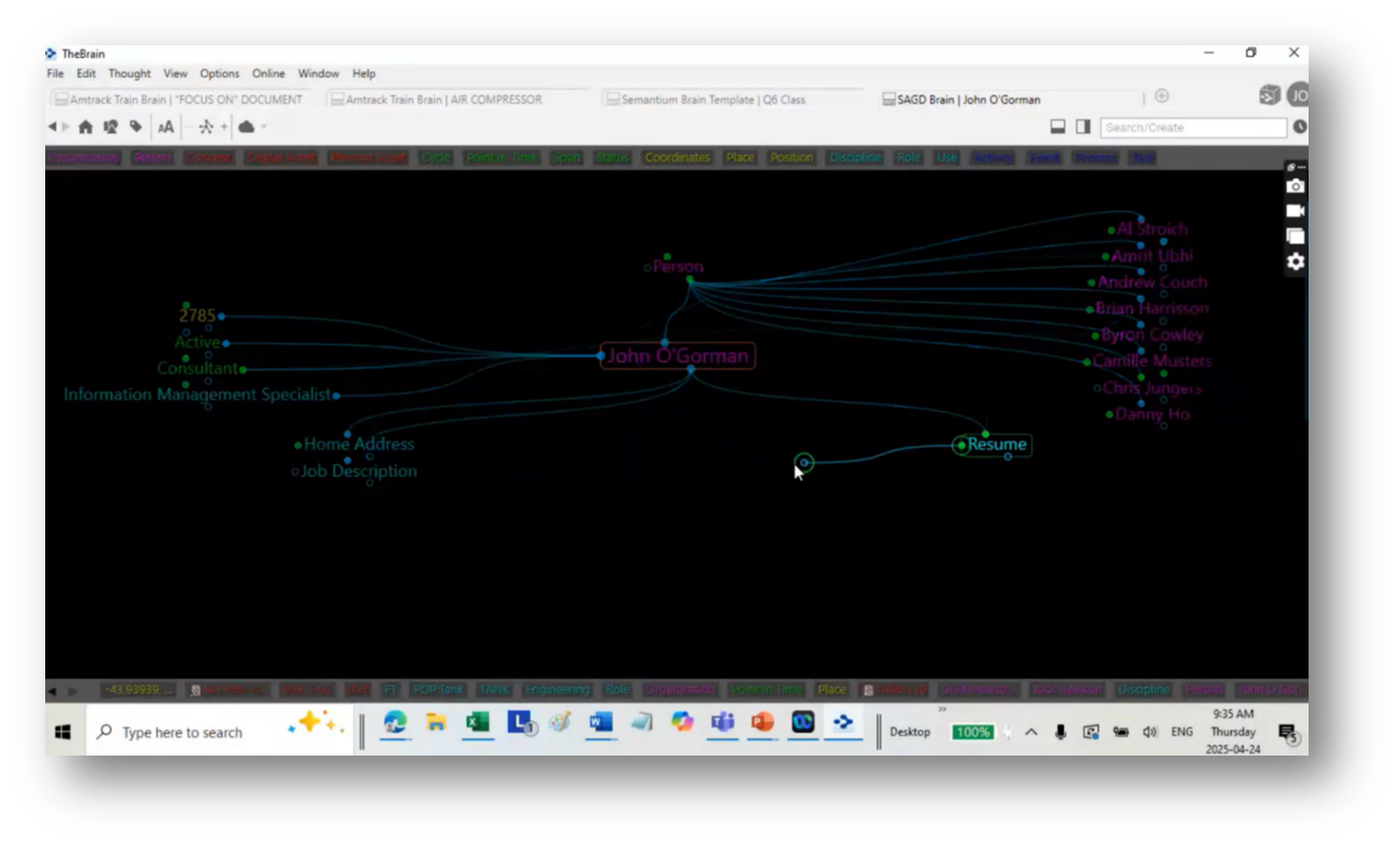
Figure 60 Information Management Tool
Functionality of Semantium as a Classification Software
John shared more on the approach of a technology-agnostic classification system exemplified by a $250 mind mapping software called The Brain, which facilitates comprehensive documentation and training, such as air compressor maintenance guides. It enables users, including new hires, to quickly access definitions and related concepts, facilitating efficient information retrieval.
While the Brain shares some similarities with Gist Semantic Arts, which is marketed as a pre-built upper-level ontology, this system emphasises customisable classifications tailored to specific business needs, rather than relying on domain-specific templates. This flexibility enables users to construct any desired ontology, taxonomy, or document structure, thereby enhancing the system's adaptability and usability.
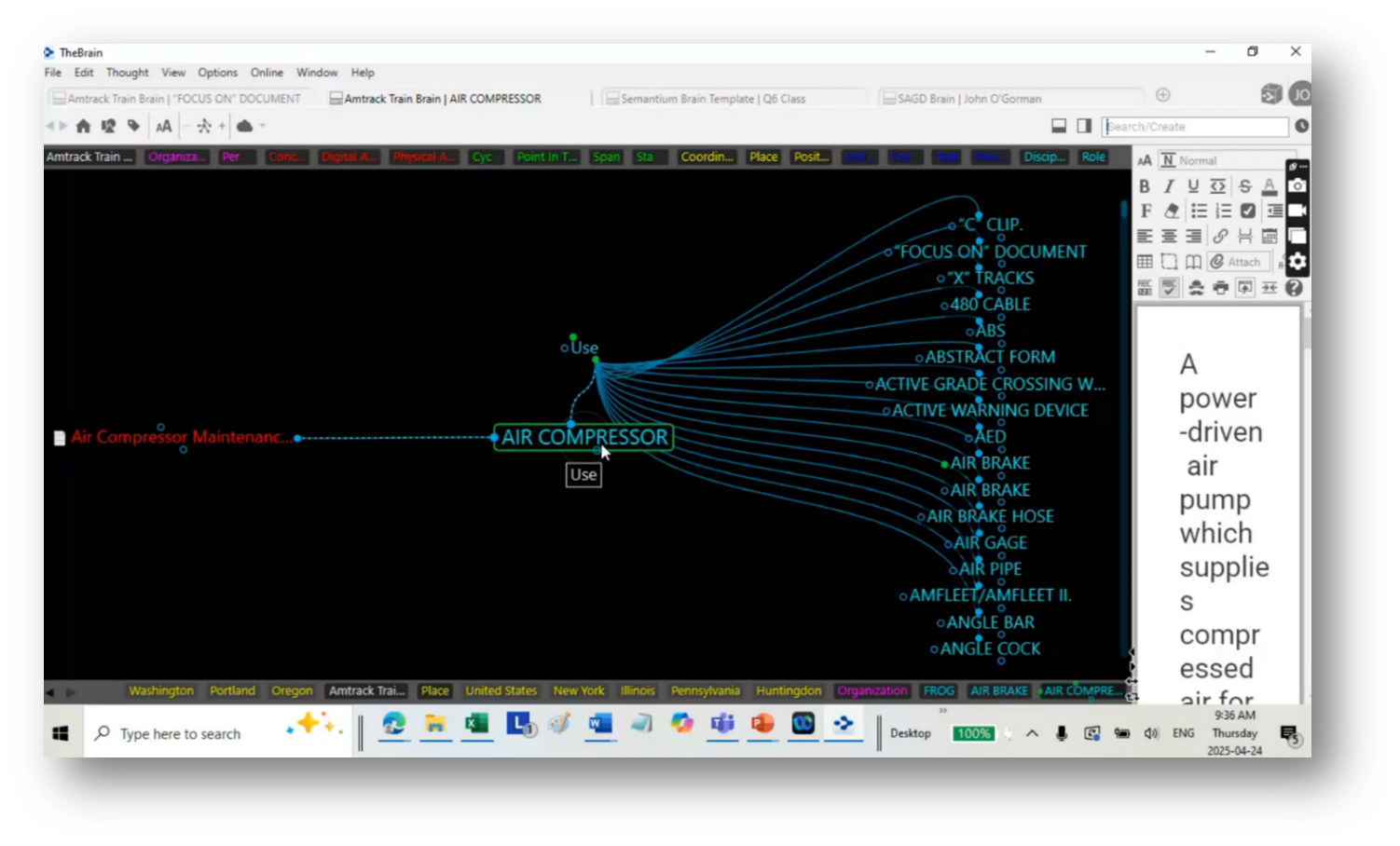
Figure 61 Artefact "Air Compressor"
Figure 62 What the Item is
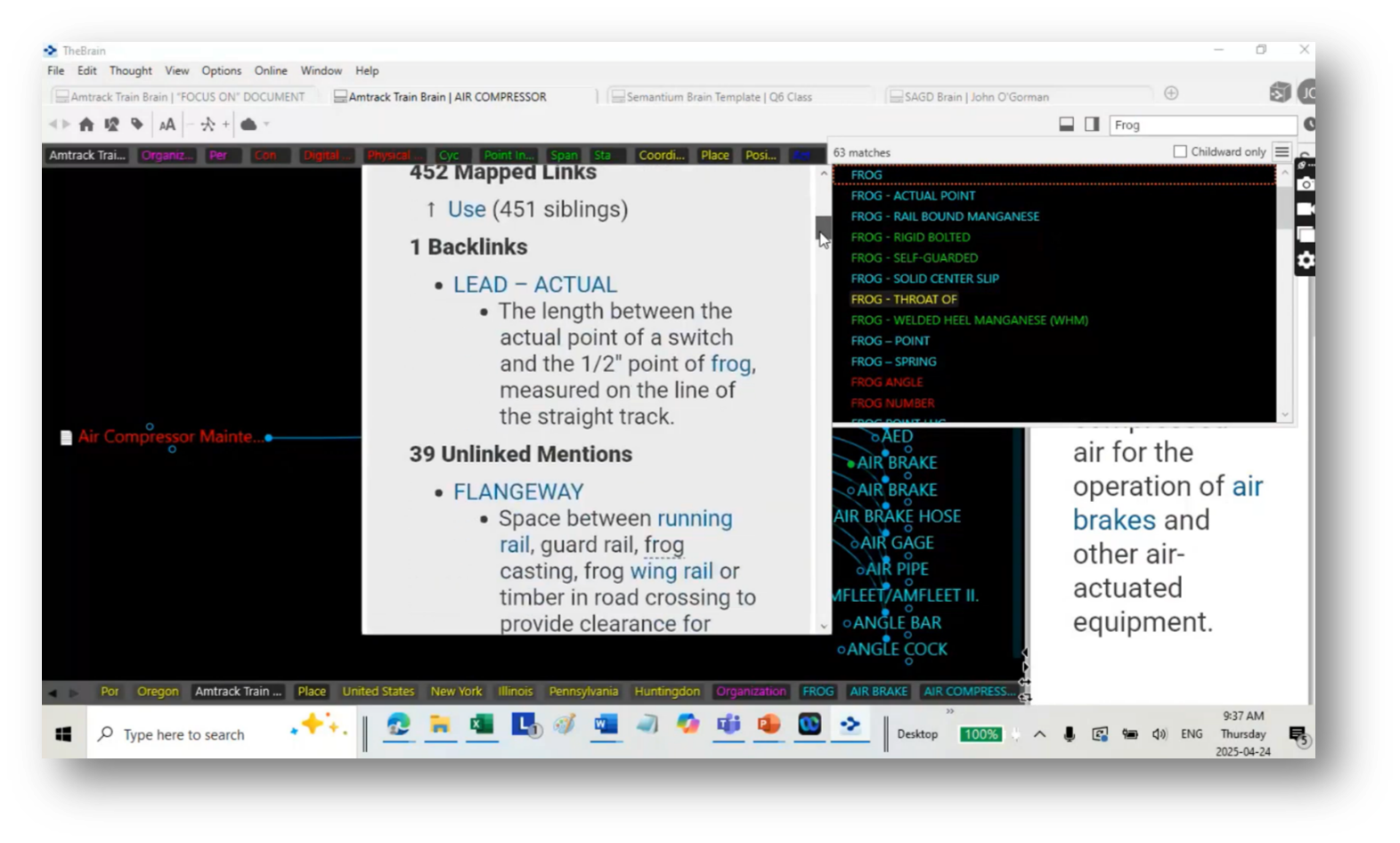
Figure 63 What the Item Links to
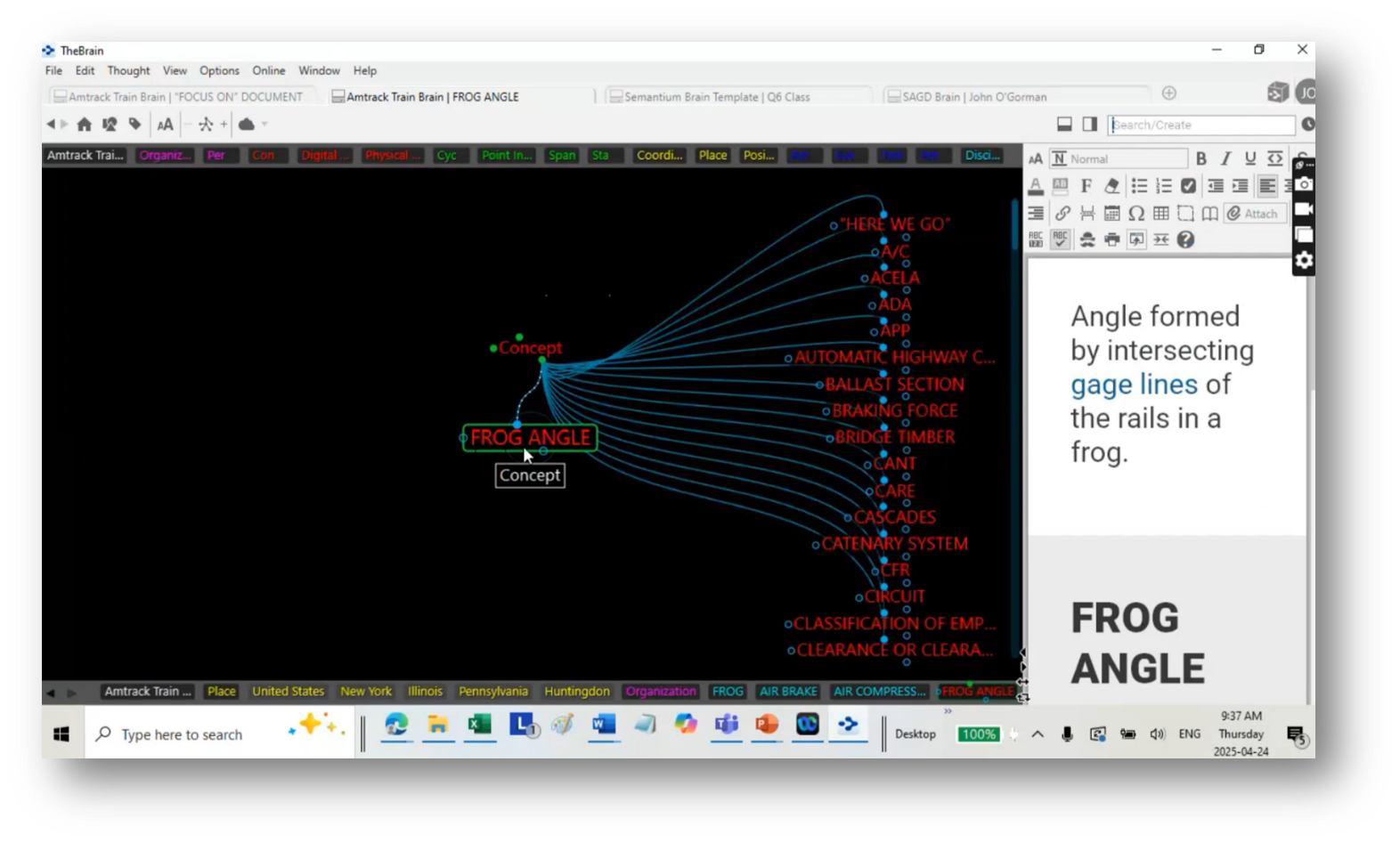
Figure 64 Linked to Item
Constraints and Potential Improvements of Classification Protocols
A classification protocol centres around a highly constrained approach to connecting and labelling edges, with only six options available for this purpose. This framework enables companies to associate addresses with physical assets without requiring the creation of a complex ontology. However, the simplicity of the connectivity can lead to challenges when attempting to differentiate between specific relationships.
By using nodes for clear connections, such as date nodes for points in time, this protocol facilitates straightforward interactions without arbitrary connectors. Additionally, the conversation touches on a desire to explore different systems and their mappings, highlighting the importance of understanding acronyms and templates within the framework.
The constraints of mapping protocols centre around the properties found on the edges and within the quants. The quant types are explained through expressions, such as using the acronym AFE, which stands for Approval For Expenditures, along with its definition. This approach could enhance Howard's methodology by introducing more granularity and control. Additionally, the random nature of current graph situations is highlighted, as people often struggle with semantics, particularly when they are familiar or unfamiliar with certain individuals, such as Howard. Key types of relationships identified include membership (e.g., John O'Gorman as a member of the person class), meronomy (parts and wholes), and precedence, which is used for constructing process maps to clarify the order of tasks.
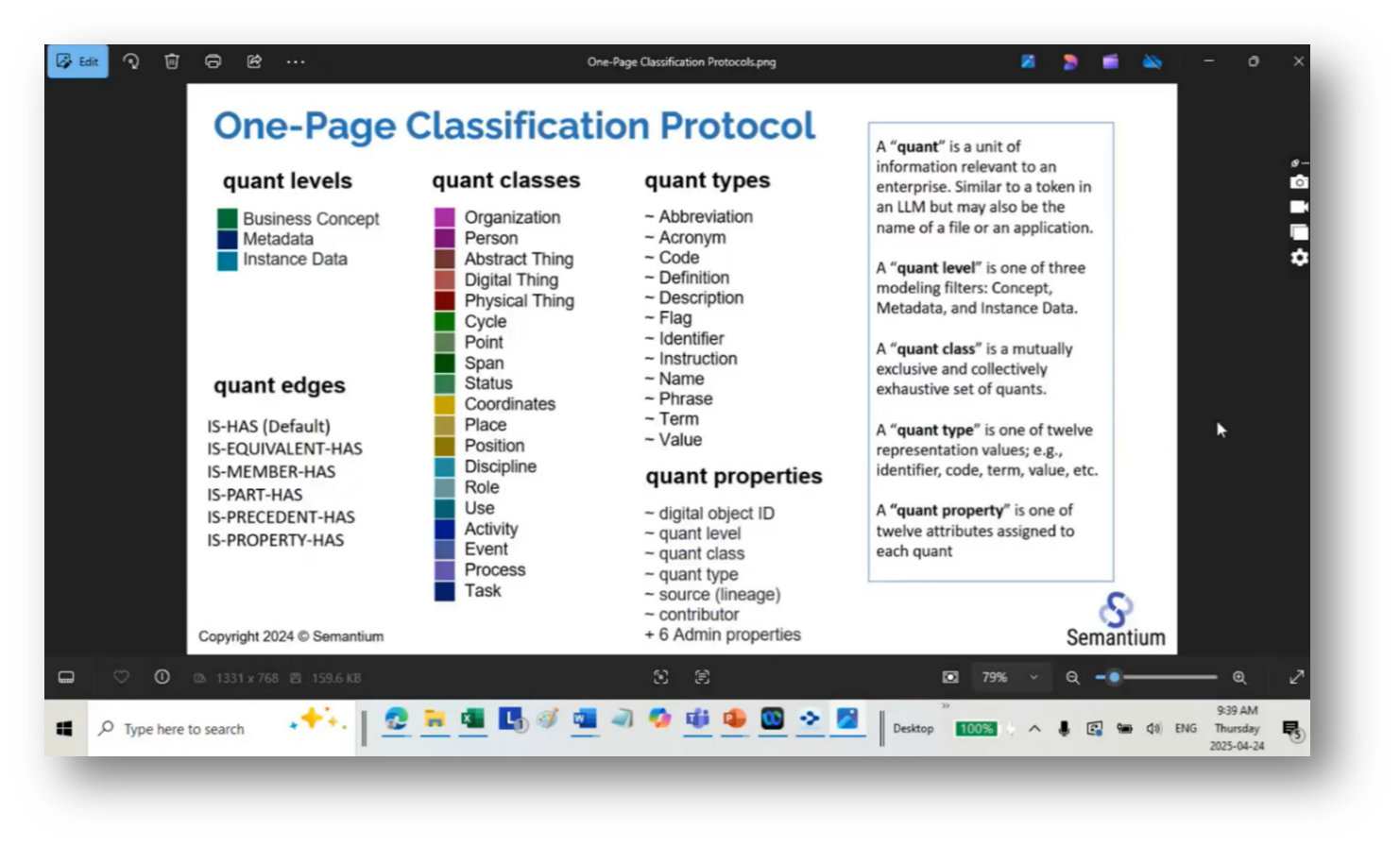
Figure 65 One-Page Classification Protocol
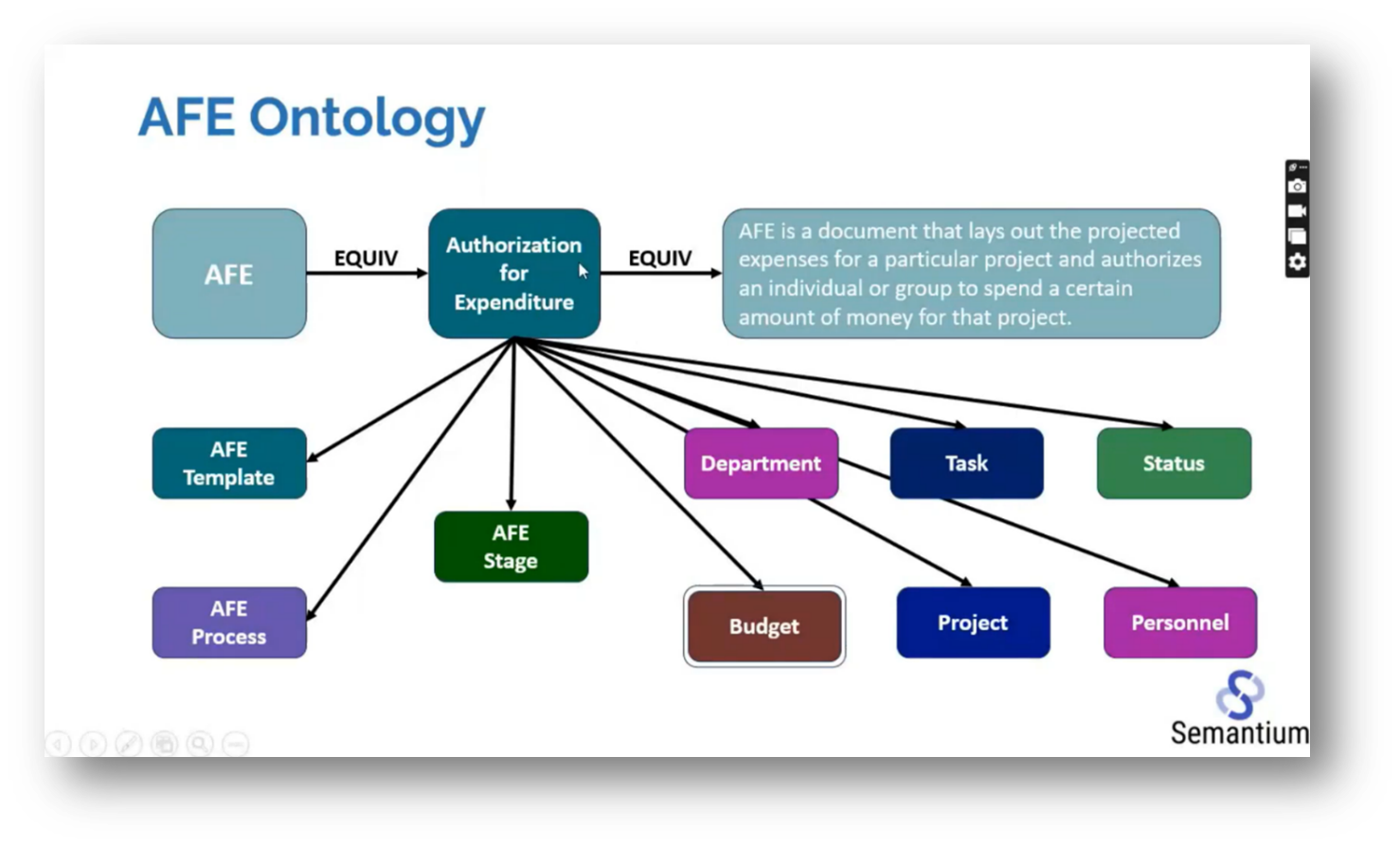
Figure 66 AFE Ontology
Data Modelling and Discipline in Engineering
John emphasises understanding discipline values and their associated document types when building a data model that incorporates academic disciplines. These can include deliverables like bills of materials and functional documents. Templates may guide the building process, allowing customisation based on specific project needs. Additionally, John discusses the navigation of document types and the use of unique codes for different disciplines, enabling efficient access to relevant information, such as foundation drawings for concrete or electrical heat tracing documents. Overall, he emphasises that the focus is on creating a structured visualisation to parse and utilise knowledge areas within engineering disciplines effectively.
A discussion then highlights the versatility of Howard's content management approach, which enables users to reference various storage locations without concern for the content's origin. By adhering to specific naming conventions or utilising Metadata, users can selectively filter documents based on date ranges.
This capability is particularly valuable during mergers and acquisitions, where integrating information from multiple companies can be a challenging task. By mapping data and establishing synonyms, the process becomes more manageable, facilitating better relationship management of data artefacts. Ultimately, the objective is to improve the efficiency of data handling in complex environments.
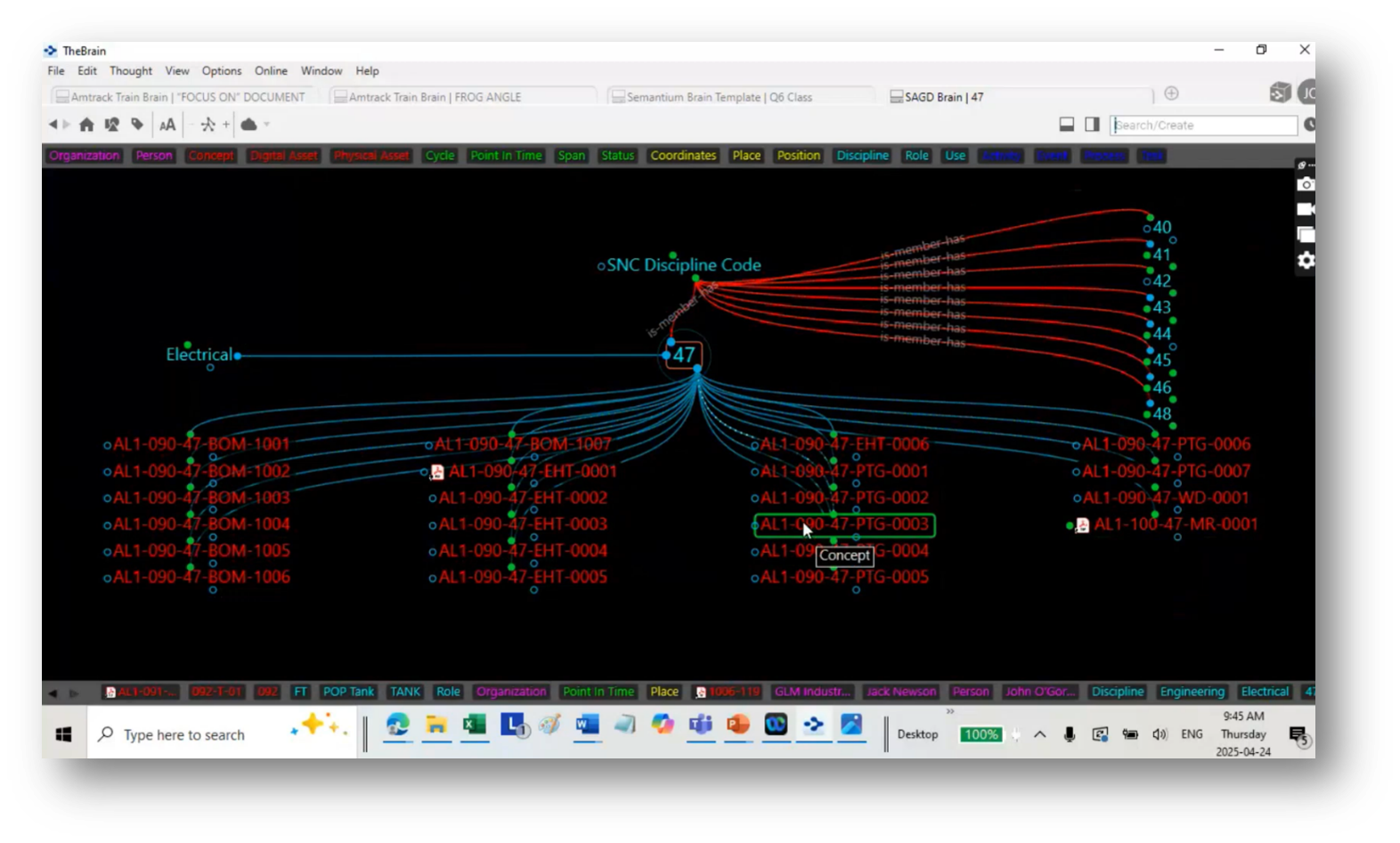
Figure 67 Documents linked to "47"
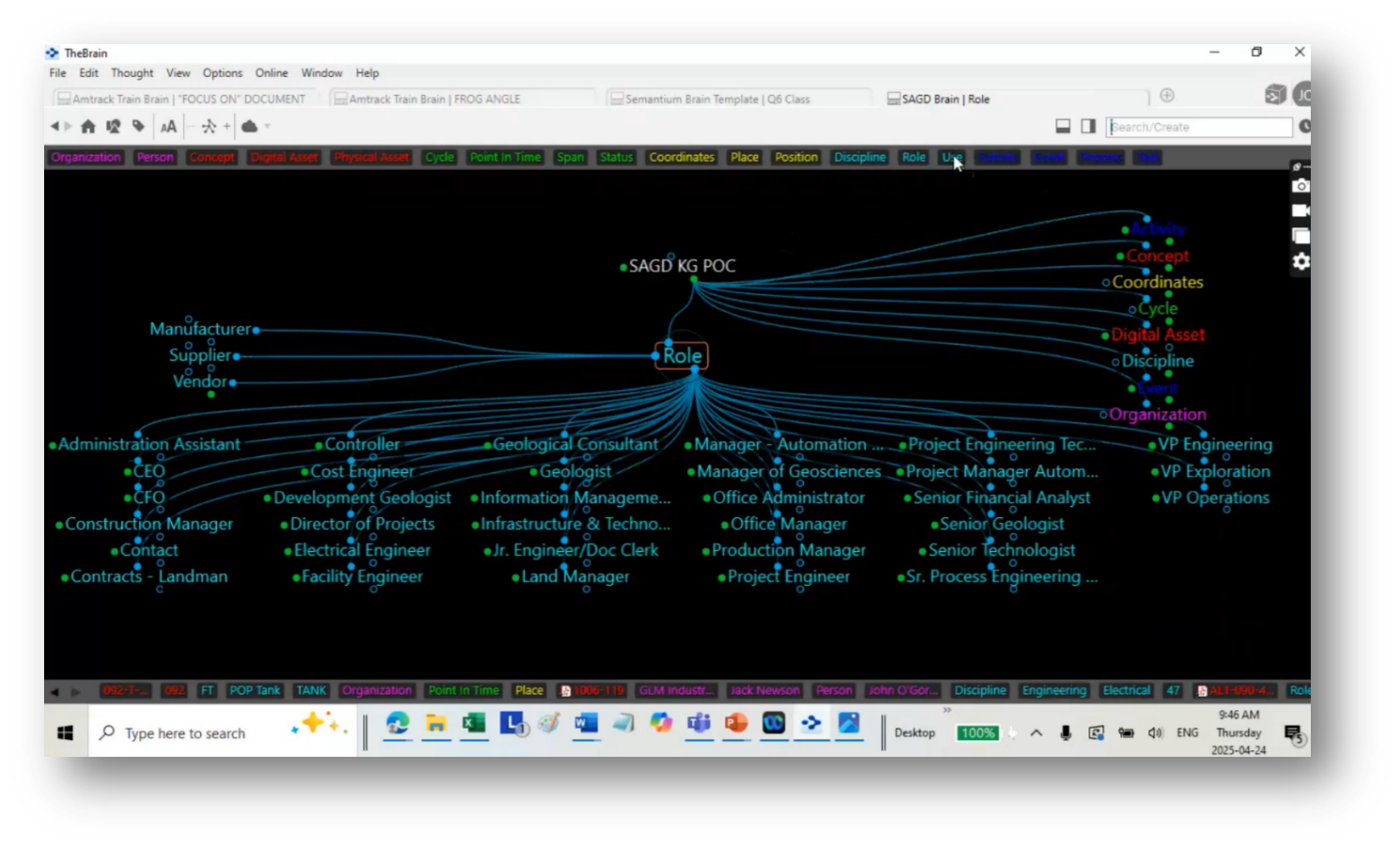
Figure 68 Roles linked to People Involved
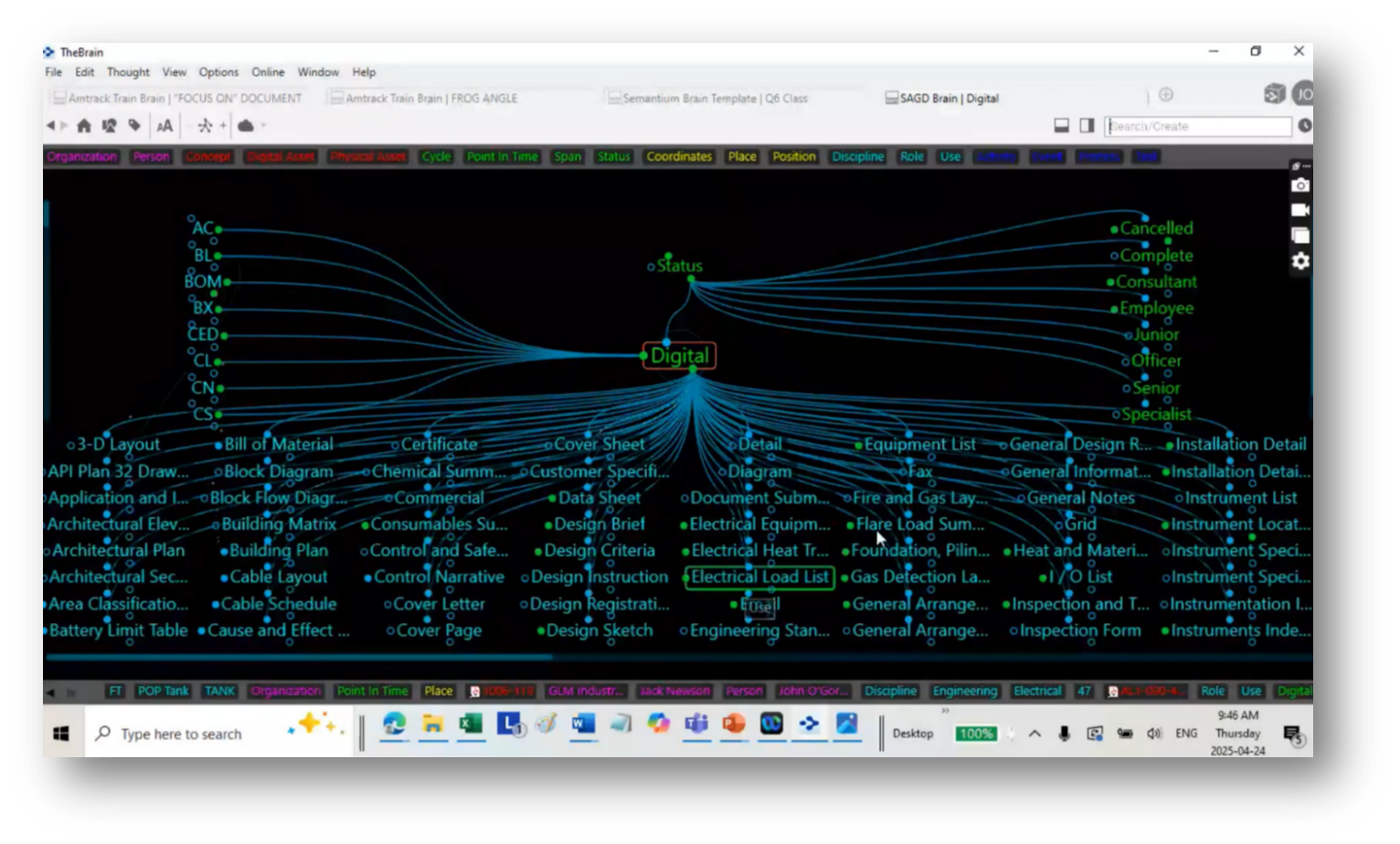
Figure 69 Expanding Information Available to the Term "Digital"
If you would like to join the discussion, please visit our community platform, the Data Professional Expedition.
Additionally, if you would like to be a guest speaker on a future webinar, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!