
Enhancing Semantic Clarity in Data Modelling for Data Executives

Executive Summary
This webinar highlights the importance of semantic clarity and consistency in data management, particularly within the realm of big data analytics. Howard Diesel emphasises the need for effective data strategies that tackle the challenges of semantic standardisation while engaging with domain language models and generative AI in educational institutions.
The balance of driving and limiting forces in decision-making is crucial, along with the implementation of clear business definitions and strategies. Additionally, Terminology alignment and force field analysis are essential for enhancing collaboration across organisations.
Howard then underscores the role of business information models and ontologies in data management as they help address semantic inconsistencies and support efficient decision-making. Lastly, the webinar navigates the interplay between semantics and structure in object-oriented programming, as well as integrating ontology and data in graph databases, which is vital for ensuring regulatory compliance and improving communication within organisations.
Webinar Details
Title: Enhancing Semantic Clarity in Data Modelling for Data Executives
Date: 13 March 2025
Presenter: Howard Diesel
Meetup Group: African Data Management Community
Write-up Author: Howard Diesel
Contents
Semantic Clarity and Consistency in Master Data Management
Semantic and Syntactic Consistency in Big Data Analytics
Data Strategy and Challenges in Semantic Standardisation
Domain Language Models and Engaging with Generative AI in Education Institutions
Balancing of Driving and Limiting Forces in Decision Making
Implementing Business Definitions and Strategies
Terminology Alignment and Force Field Analysis in the Organisation
Semantic Clarity in Business and Its Impact on Communication and Decision Making
Regulatory Compliance, Semantic Clarity, and Information Architecture
Business Information Model and Data Management
The Business Information Model and Its Role in Data Management
Addressing Semantic Inconsistencies and Enhancing Collaboration in Organisations
Business Cases and Efficient Decision Making in Semantic Charity
Challenges and Solutions in Data Modelling and Semantics
Business Information Model and Ontology
Navigating Semantics and Structure in Object-Oriented Programming
Data and Ontology in Knowledge Graphs
Integration of Ontology and Data in Graph Databases
Understanding Data Element and Data Attribute in Database Regulation
Semantic Clarity and Consistency in Master Data Management
Howard Diesel opens the webinar and shares that his focus will centre on the importance of semantic clarity and consistency in managing data. In particular, when building a business case for Master Data Management (MDM). He goes on to add that key aspects of the presentation will include focusing on critical success factors, as highlighted by Gartner.
Gartner’s piece emphasises the need for consistent and objective semantics, striving for a single version of the facts rather than a single version of the truth and strategically managing semantics at different scopes. Howard adds that effective communication with stakeholders is crucial in this respect. It is helpful to include expressions of benefits in relatable business terms to avoid abstraction in Master Data Management (MDM) efforts.

Figure 1 'Semantic Clarity & Consistency Management' Deck

Figure 2 "Know your CSFs before you start"

Figure 3 Gartner's CSF Master Data Management
Semantic and Syntactic Consistency in Big Data Analytics
In a recent research article conducted by Victor Rohr and Ron Rundnicki, it was highlighted that the importance of semantic and syntactic consistency is a key enabler for big data analytics. A notable working group explored various aspects, including data lakes and the need for consistent semantic layers across datasets. The article's authors' investigations also covered open-linked data, knowledge graphs, and ontologies, focusing on strategies to achieve this consistency in big data. Their discussion raises critical questions about whether consistency can be achieved through human efforts or if it requires the implementation of classification systems, AI, or large language models. For anyone interested in the findings, search here.

Figure 4 Critical Enabler for Big Data Analytics

Figure 5 Force Field
Data Strategy and Challenges in Semantic Standardisation
Howard shares on his practice of conducting SWOT analyses as part of data strategy, focusing on strengths, opportunities, threats, and weaknesses. Key restraining forces include various regulations and frameworks such as BCBS 239 and anti-money laundering, which create complexity in integrating differing ontologies, leading to challenges in standardisation and resource limitations.
Resistance to change, lack of clear communication, and inconsistent implementation of data definitions contribute to difficulties in achieving semantic clarity. Legacy data poses additional challenges, as changing it can be costly. Conversely, Howard notes that driving forces highlight the importance of strong data governance and stakeholder engagement to foster commitment to consistent terminology and standards, ultimately resulting in improved clarity across the organisation.
Domain Language Models and Engaging with Generative AI in Education Institutions
Howard then shares the advancements in generative AI, specifically the introduction of Domain Language Models (DLMs) alongside existing Large Language Models (LLMs) and Small Language Models (SMLs). He emphasises the need for collaboration between semantics, business ontologies, and productivity tools and underscores the increasing importance of semantic clarity.
The effectiveness of LLMs in simplifying complex concepts is exemplified in asking an LLM to explain ideas to a user as though they were a 5-year-old. Howard mentions the integration of knowledge graphs to validate LLM responses, ensuring accuracy through pre- and post-loading processes. Additionally, he notes how academic institutions are encouraging the use of AI by requiring students to share their input prompts alongside the generated responses, fostering a deeper engagement with AI technologies like ChatGPT.
Balancing of Driving and Limiting Forces in Decision Making
The use of driving and restraining forces to assess the implementation of a semantic layer’s success is explored. Howard notes that a zero score indicates a balance between these forces, signalling a need for deeper analysis to break the deadlock. Key driving factors for success included clear definitions, consistent terminology, effective governance, and increased stakeholder engagement through community practices. Howard then highlights differences in approaches to managing terminology, with one attendee advocating for starting with domain definitions to avoid siloing, leading to valuable insights about differing word interpretations among stakeholders.

Figure 6 Driving Forces (Success Factors)
Implementing Business Definitions and Strategies
It is imperative to engage with various stakeholders (including marketing, sales, and finance) to achieve semantic consistency in definitions. This is most evident in the challenges that arise when trying to get a consistent definition of "customer" across different domains. Additionally, Howard highlights the significant time investment required for developing effective business definitions, learning specific approaches, and the complexities involved in standardisation.
Resistance to change, communication issues, and inconsistent implementations are common challenges faced with regards to achieving standardisation. A balanced Force Field Analysis (FFA) is suggested by Howard as a tool to evaluate both driving and restraining forces when presenting a business case. This allows for the identification of potential benefits as well as weaknesses and threats and facilitates continuous monitoring and adjustment of strategies to overcome obstacles.

Figure 7 Resistance Forces (Failure Factors)
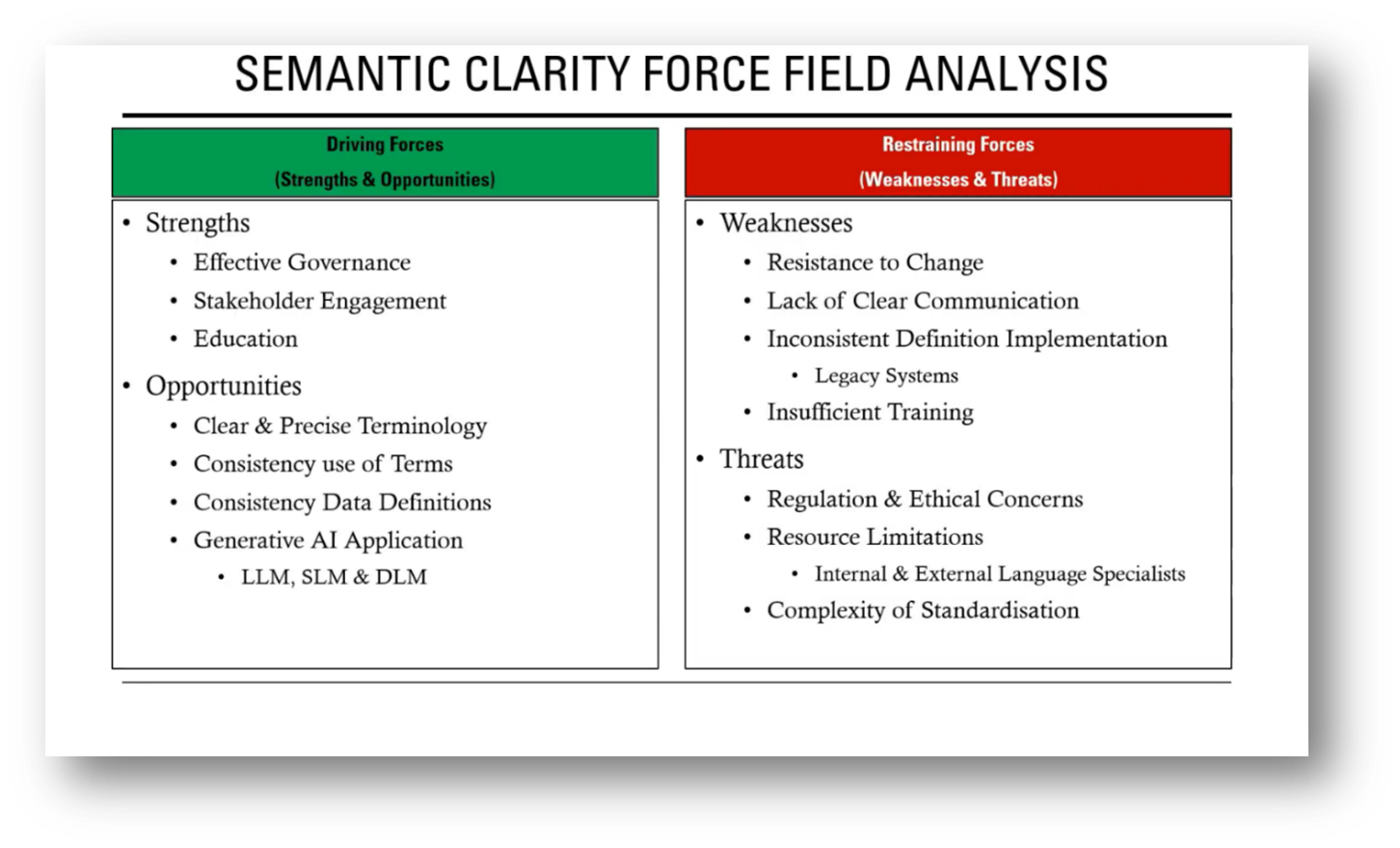
Figure 8 Semantic Clarity Force Field Analysis

Figure 9 Addressing a Balanced FFA
Terminology Alignment and Force Field Analysis in the Organisation
An attendee communicates to Howard that their organisation has agreed on adopting a common definition for a term used across various departments while allowing each area to use its own terminology. This approach, according to the attendee, recognises that business units, such as insurance, may refer to customers by different terms - like "insurance taker" instead of "client" - due to their specific language and context. Although achieving complete alignment on definitions may be challenging, a generic term will be established that everyone can relate to while local terminology can still be used.
Semantic Clarity in Business and Its Impact on Communication and Decision Making
The business case for achieving semantic clarity within an organisation emphasises the importance of standardising business terminology and definitions to enhance data quality, improve collaboration, and increase efficiency. By addressing challenges stemming from differing interpretations of terms—illustrated by a discrepancy between the stock market and central bank definitions of "cross-border flows" - the organisation can foster a consistent understanding among stakeholders. This clarity not only leads to accurate data interpretation but also facilitates better communication and quicker decision-making by minimising misunderstandings, ultimately driving more effective collaboration and improved outcomes.

Figure 10 Semantic Clarity Business Case

Figure 11 "Main Objective: Achieve semantic clarity within the organization by standardizing business terminology and definition"
Regulatory Compliance, Semantic Clarity, and Information Architecture
Howard shares an example to highlight the critical importance of regulatory compliance and semantic clarity in business terminology. The example is of a bank that was fined 54 million Rand due to misuse of terms relating to BCBS 239, stemming from a poorly defined business glossary.
The incident underscores the need for standardisation of terminology in reports to enhance audit readiness and operational excellence, ultimately reducing misunderstandings and improving data governance and stakeholder engagement. Key challenges include confusion and misinterpretation of metrics, as seen with Airbnb's approach to managing consistent definitions.
Howard and the attendees then discussed architectural frameworks. Particularly, Howard notes that data architecture primarily deals with the physical and logical aspects of data, while information architecture focuses on conceptual structures. This reinforces the necessity of a clear business information model to promote semantic clarity across the organisation.

Figure 12 Problem Statement
Business Information Model and Data Management
Creating a fully attributed logical data model may serve as a structured glossary for business terminology. Howard cautions against premature data modelling; instead, he prioritises a clear and simplified definition of business terms that can be agreed upon. This includes breaking down terms into easily digestible components, such as subject, predicate, and object.
Howard then touches on assessing data management practices through frameworks such as the Data Management Capability Model (DCAM) versus the DMBOK. He highlights that while DCAM may not include master data, it effectively evaluates data management processes concerning quality, integration, and consistency.
The Business Information Model and Its Role in Data Management
The business information model is a non-technical solution design framework focused on organising and utilising data within a bank from an information perspective. It defines a vocabulary through a glossary, groups terms into taxonomies, and leverages the Financial Industry Business Data Model (FIB-DM) or Financial Industry Business Ontology (FIBO) as a foundational structure. While FIBO emphasises quality, the model created is not strictly hierarchical; instead, it depicts relationships between various terms, ultimately serving as a blueprint for the organisation. This encompasses the connection between concepts, such as a "safekeeping account," and illustrates how these concepts relate to customers and other elements. Thus, the distinction between terms, taxonomies, and the business information model is essential in understanding the framework's structure and functionality.
An attendee notes that clarifying the separation of business layers, specifically the business term concept model and the business information model, is necessary to eliminate confusion and misinterpretation within the organisation. Additionally, Howard emphasises the need for standardised terminology and clear definitions to enhance data consistency, ultimately aiming to improve decision-making processes. The goal is to combat issues that lead to delays and inefficiencies in decisions. By achieving a common understanding and enhancing collaboration among team members, the organisation expects to see increased efficiency and clarity in its operations.
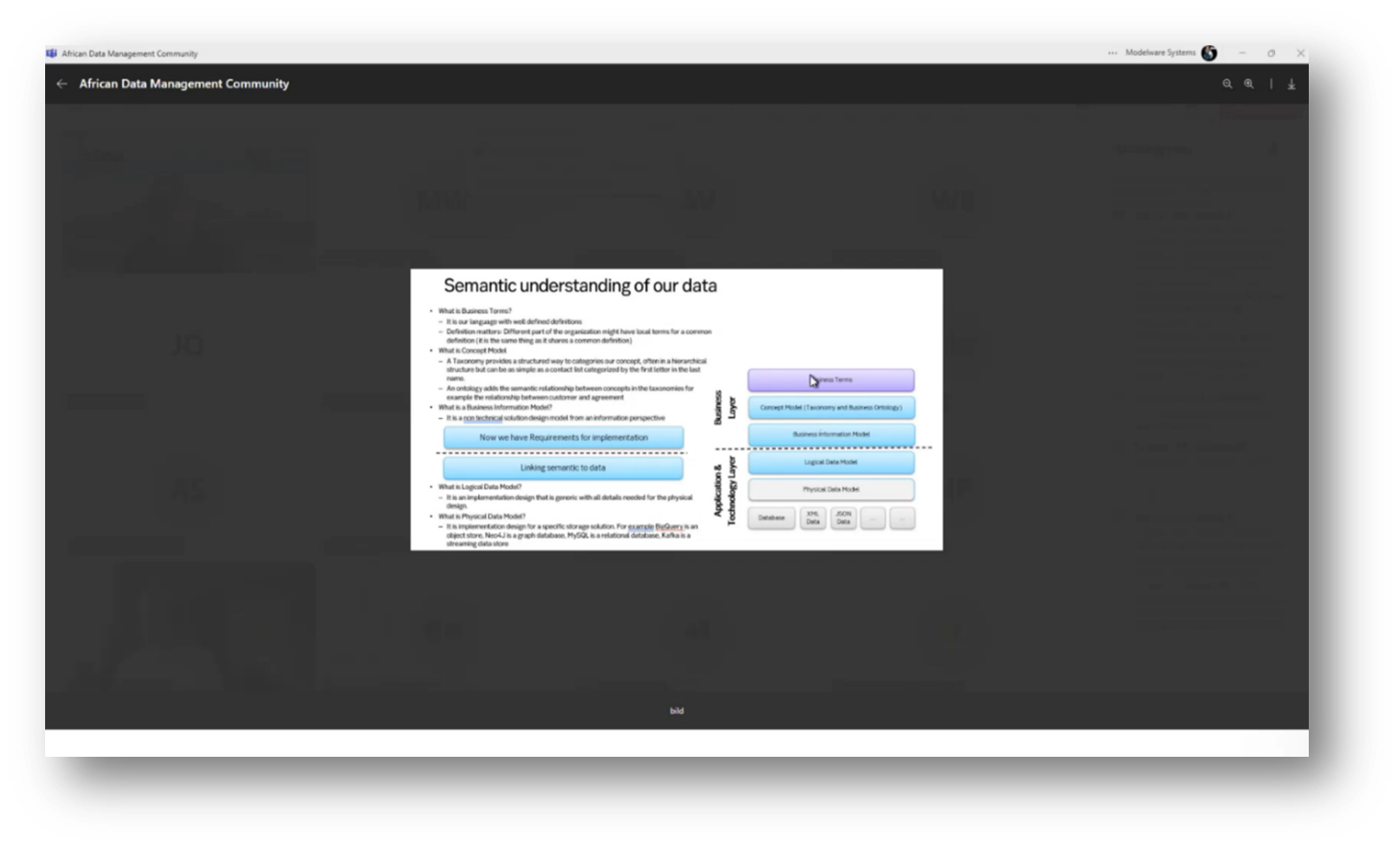
Figure 13 Semantic Understanding of Our Data
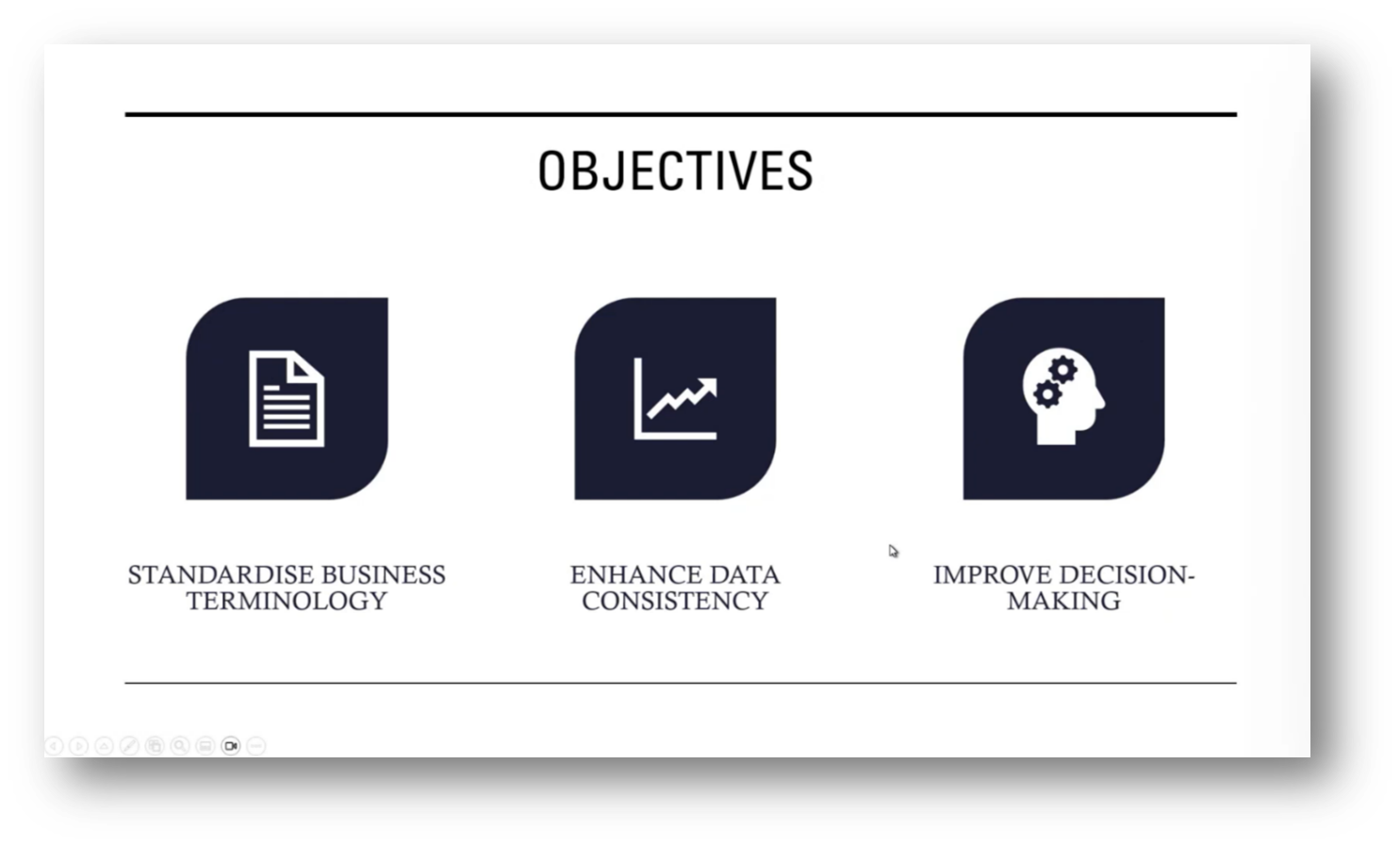
Figure 14 Objectives

Figure 15 Benefits
Addressing Semantic Inconsistencies and Enhancing Collaboration in Organizations
The approach to enhancing clarity within an organisation involves first assessing existing ambiguities and developing agreed-upon terminology, which exposes contradictions from various stakeholders. This process helps identify areas of confusion and leads to necessary updates in dashboards and areas prone to conflict.
Effective implementation requires leadership support, clear communication, and training to ensure that all team members possess the necessary knowledge and skills, particularly in specialised areas such as financial markets. Additionally, it's essential to establish a culture that sustains the defined terms while focusing on ROI through cost savings, improved decision-making, and enhanced productivity.
Addressing semantic inconsistencies is vital for quality data and fostering collaboration. Additionally, ensuring a unified approach to managing business terminology across departments will drive overall success.
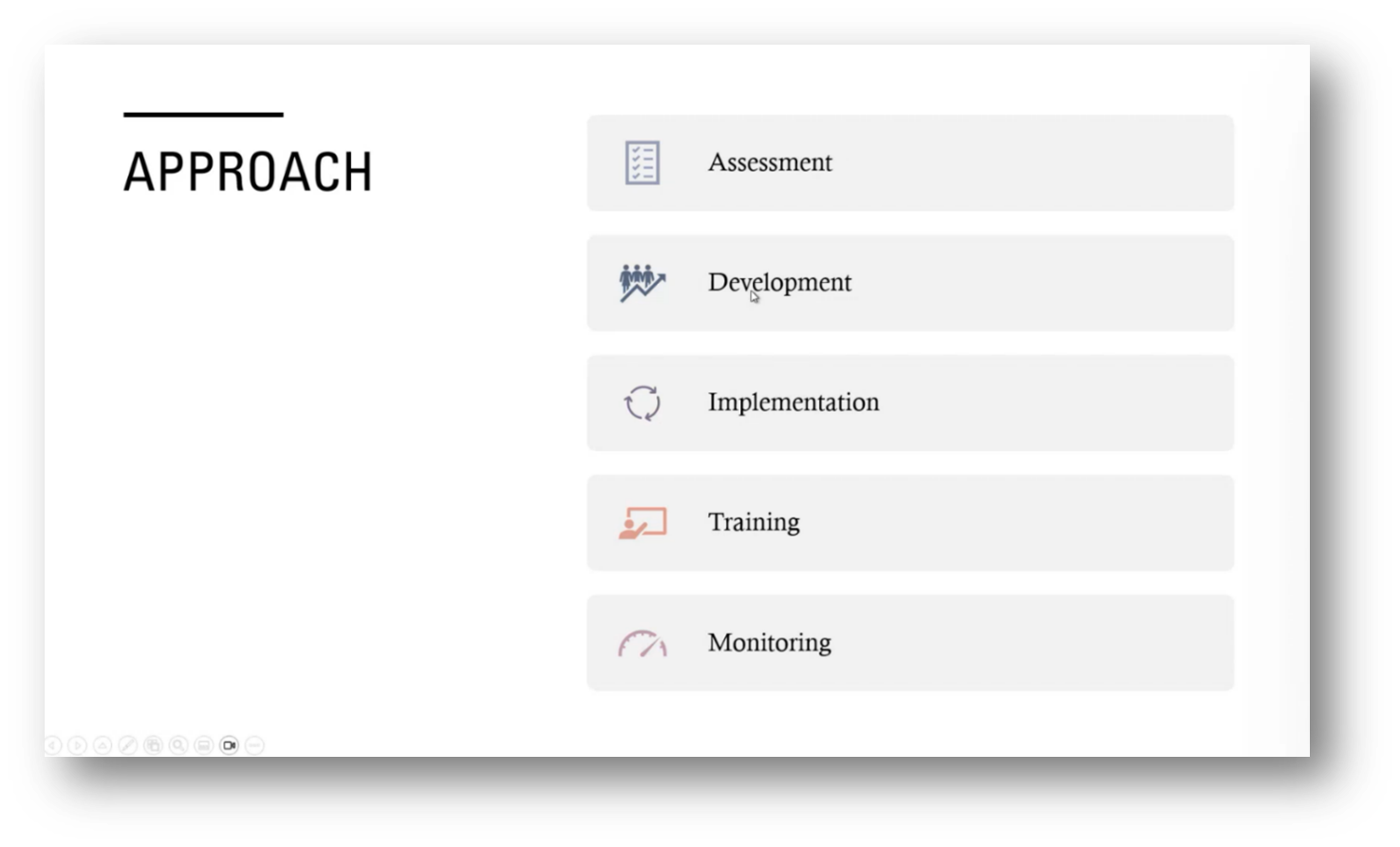
Figure 16 Approach
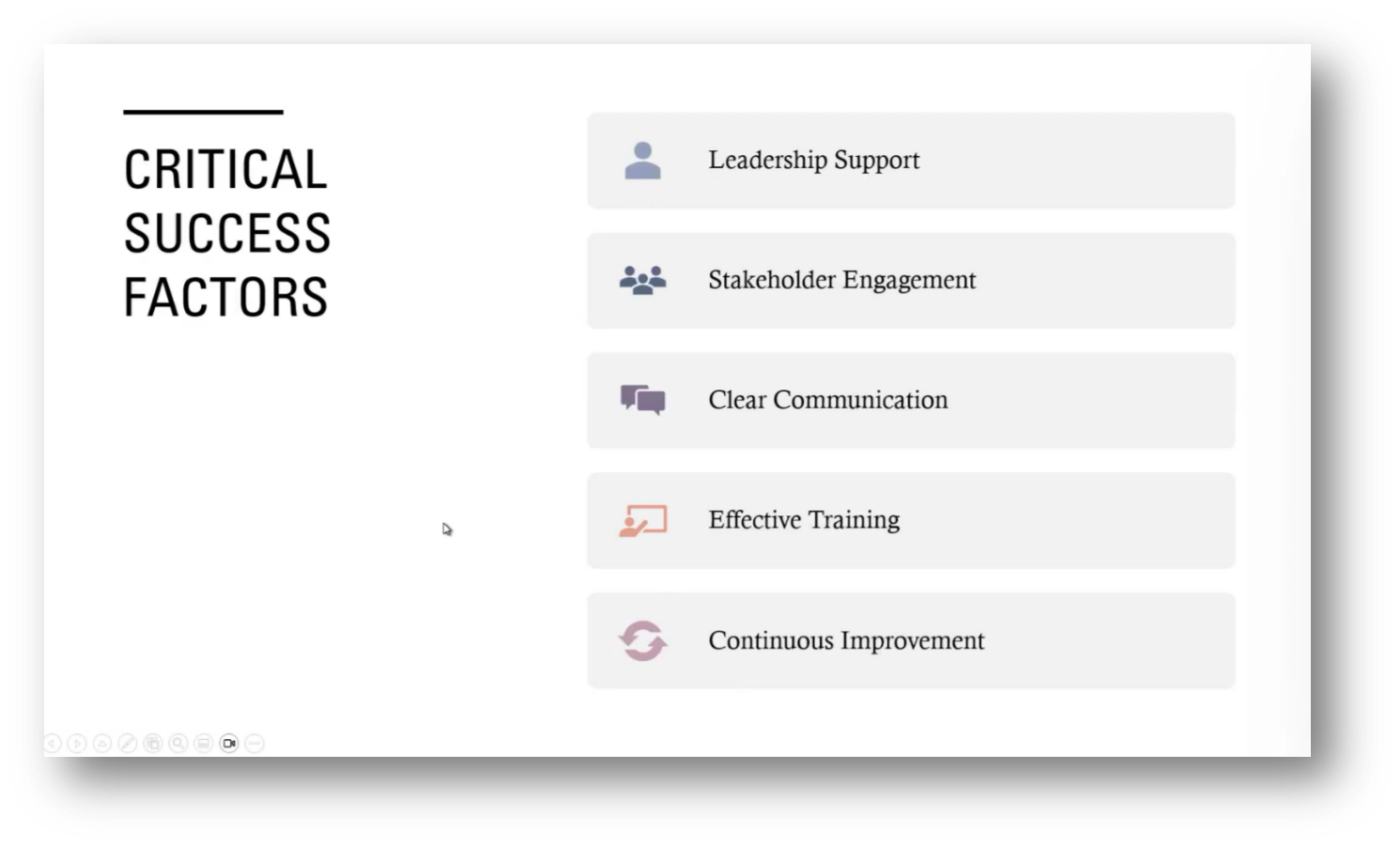
Figure 17 Critical Success Factors
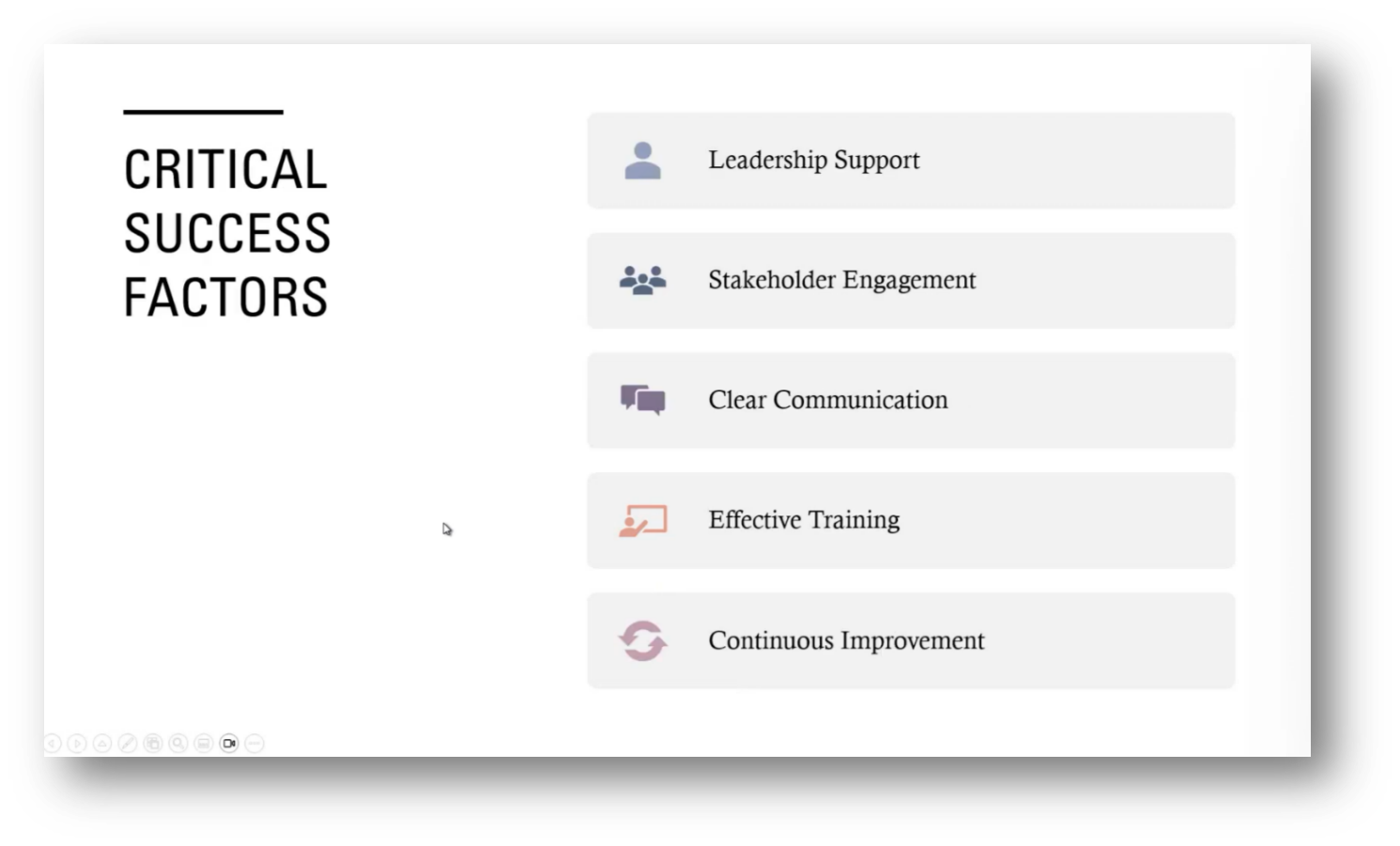
Figure 18 Readiness Factors

Figure 19 Potential ROI Calculations

Figure 20 Risk & Mitigation
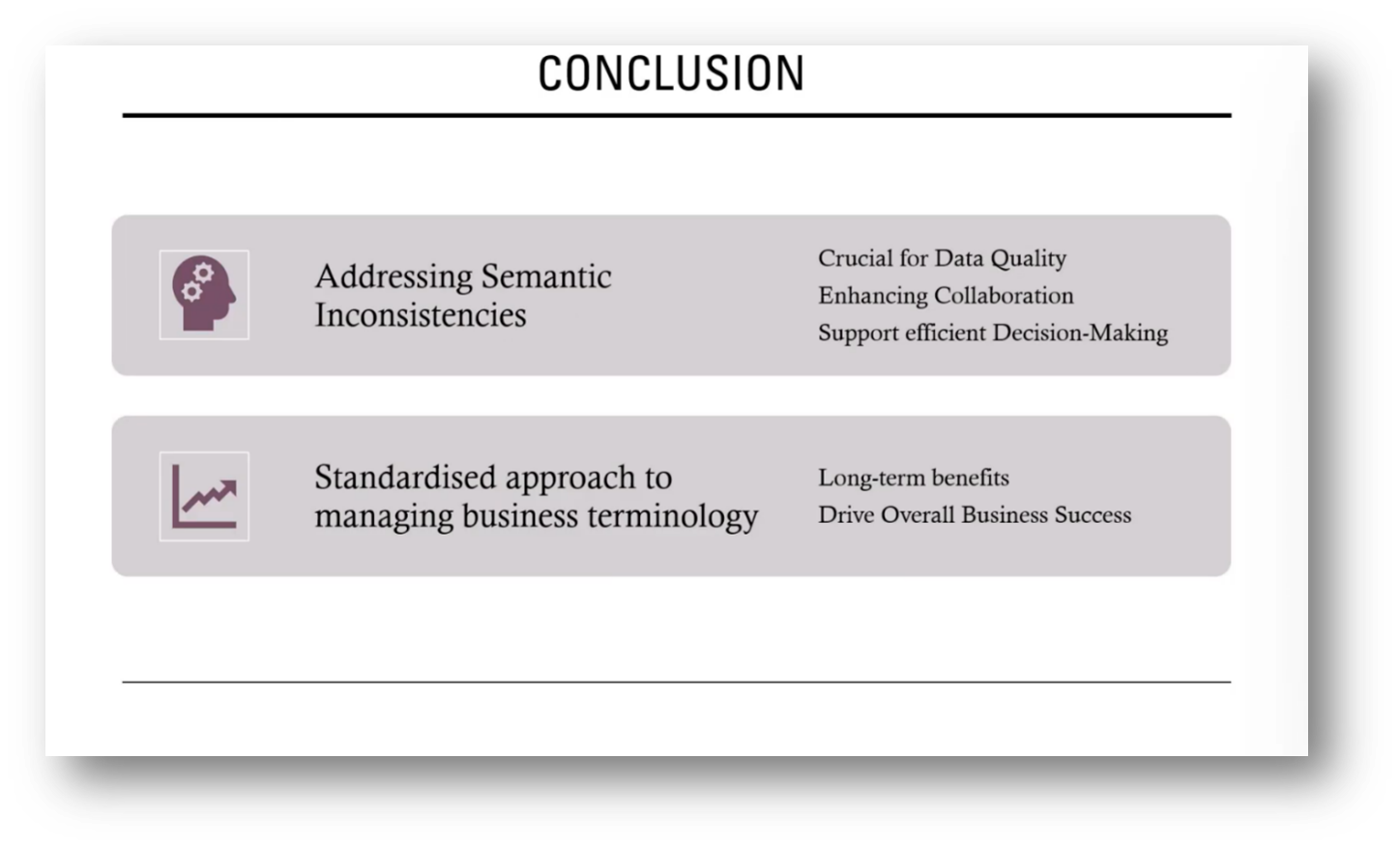
Figure 21 Conclusion
Business Cases and Efficient Decision Making in Semantic Charity
Howard outlines a proposed structure for developing a business case for semantic charity, emphasising the importance of utilising the unique language and narratives of the organisation. Key issues highlighted include minimising revenue losses attributed to misinterpretation of terms and fostering efficient decision-making amidst challenges in data interpretation and understanding among team members. Lastly, a question is raised about whether top management prioritises cost savings or efficient decision-making, suggesting that while data is crucial, misunderstandings often hinder effective collaboration.
Challenges and Solutions in Data Modelling and Semantics
The importance of conducting a thorough assessment of the business approach is emphasised, particularly through the lens of force field analysis. Howard highlights the need for clear communication with the business to address discrepancies and misunderstandings within the terminology used, which can complicate data modelling efforts. An attendee acknowledges that gathering accurate information is a significant undertaking that requires a concerted effort to redefine business definitions and enhance clarity. Additionally, they share insights from their ongoing efforts to improve comprehension and the attractiveness of their business case, particularly in relation to regulatory compliance and the integration of AI.
The attendee stresses the critical role of semantic accuracy in ensuring reliable AI outputs, distinguishing between factual information and potential inaccuracies. A visual representation of account safekeeping was introduced, showcasing the differentiation between class and business concepts. Additionally, key points emerged regarding the assessment of approaches, specifically focusing on force field analysis.
Howard then emphasises the importance of engaging with the business to clarify terms and identify misunderstandings, particularly around discrepancies in terminology. He highlights the need for a readiness assessment before developing a business case, recognising the challenges posed by ambiguities in definitions. Additionally, the necessity of a concerted effort to improve data modelling practices was noted, with examples shared to illustrate misinterpretations. Lastly, an attendee remarks on the ongoing journey to enhance understanding and the role of semantics in leveraging AI effectively, stressing the importance of distinguishing between factual information and hallucinations produced by AI.
Business Information Model and Ontology
A graphical representation of a business information model is presented by an attendee. The representation focuses on the safekeeping account and its relationship to the safekeeping account owner within an ontology or taxonomy. The safekeeping account is identified as a specialisation of an account, while the safekeeping account owner is a specialisation of an account owner.
The ontology serves as a blueprint for the business structure, illustrating how different elements interact. Additionally, the attendee notes that although a unified ontology exists, there may be multiple taxonomies to represent similar concepts, allowing flexibility in terminology based on local business language.
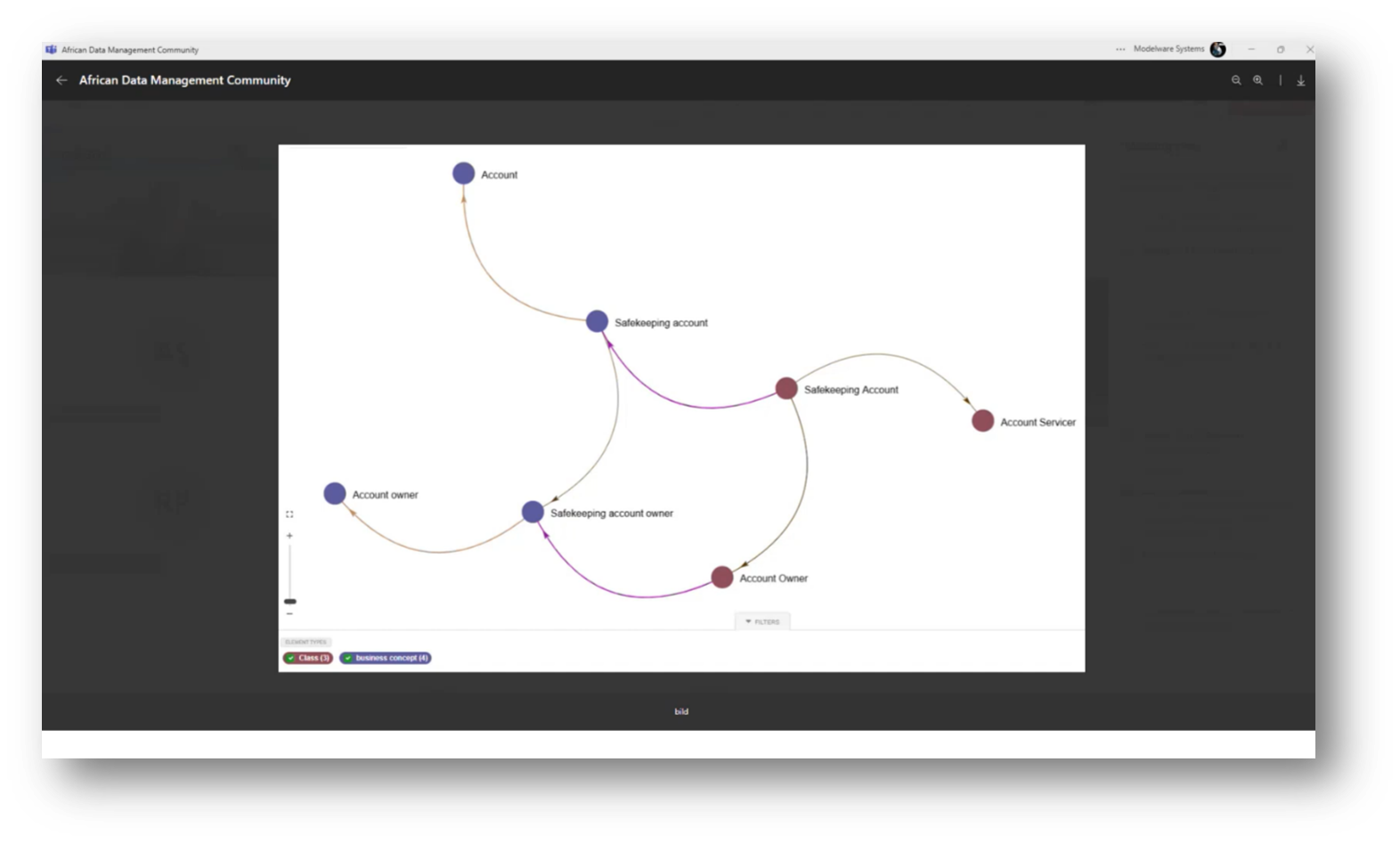
Figure 22 Business Concepts
Navigating Semantics and Structure in Object-Oriented Programming
Howard highlights the challenges that can arise when collaborating with stakeholders, particularly when introducing concepts that may threaten their core essence. He suggests utilising strategies that incorporate varying perspectives to foster collaboration among stakeholders facing common issues. Additionally, he touches on the pitfalls of seeking a single term for concepts while acknowledging the value of understanding synonyms and antonyms within different business units.
In object-oriented programming and ontology development, it is imperative to structure classes and relationships—such as account ownership. Howard adds to this by referring to the use of UML diagrams to facilitate the construction of ontologies. Additionally, tools such as Visual Paradigm and OntoUML are being employed to enhance clarity and navigation in this process.
An attendee emphasises the importance of leveraging object-oriented design principles to navigate the complexities of semantics and structure in business definitions, particularly in defining terms like "customer." They suggest that rather than striving for a singular definition that everyone agrees upon—which is often unrealistic—stakeholders should aim for a standardisation that allows for acceptable specialisations across different departments such as marketing, finance, and customer service. This approach may facilitate better communication and collaboration among teams, reducing conflicts that arise from differing perspectives.
Recognising that collisions often stem from structural rather than semantic differences is key. Establishing a consensus on a foundational definition—while allowing for tailored attributes—can alleviate tensions and enhance understanding across disciplines.

Figure 23 Visual Paradigm
Figure 24 Enterprise Architecture
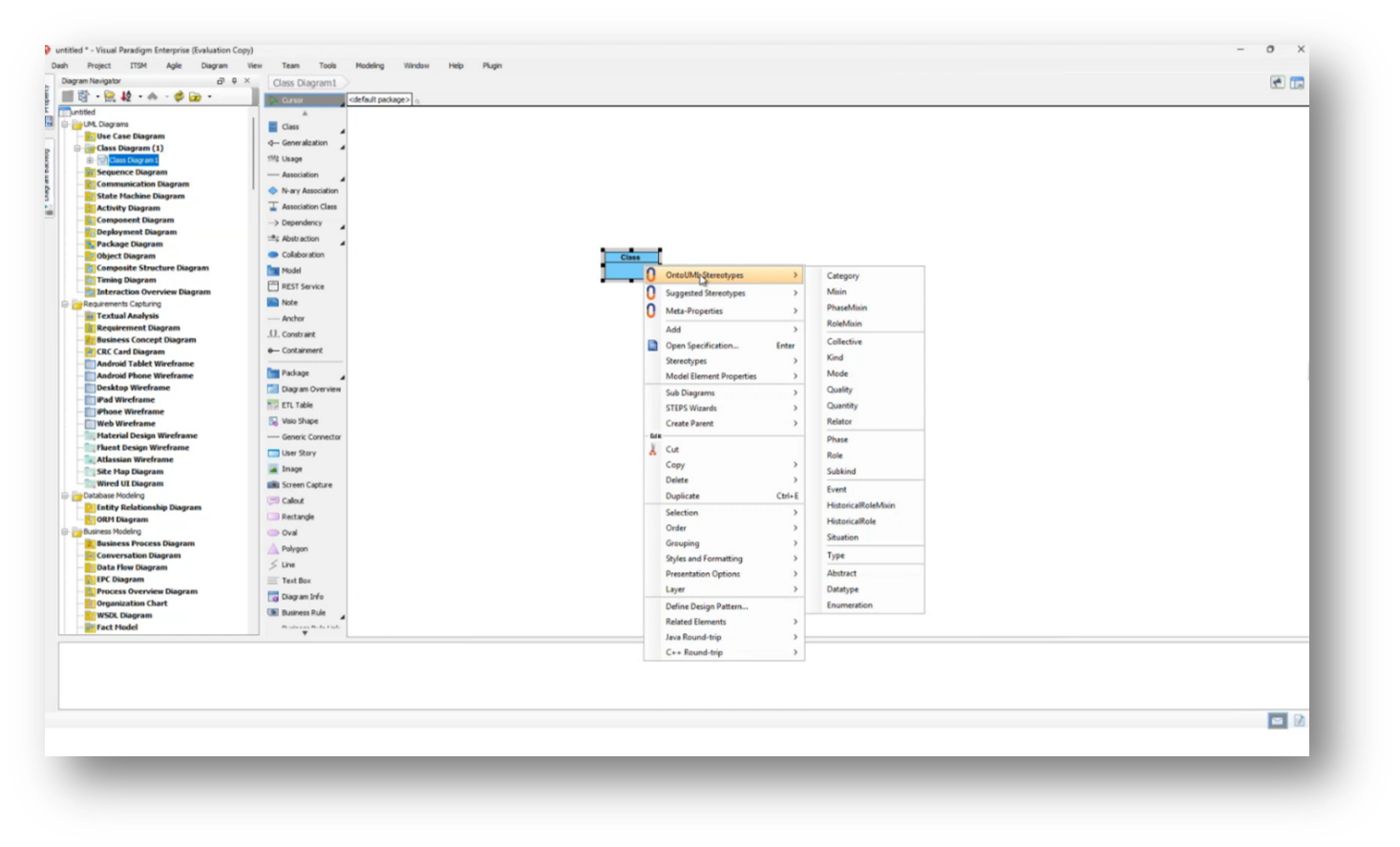
Figure 25 OntoUML Stereotypes
Data and Ontology in Knowledge Graphs
The process involves using "sortles" and "rigids" to assign terms, which can then be utilised in a plugin to generate an ontology and create a .ttl file. This file can be loaded into Protégé and subsequently into a knowledge graph. When building a knowledge graph, it is essential to consider the relationships between data products, such as publisher data, in a mesh architecture and ontologies. The data should ideally remain in its original form while forming a logic structure that integrates the ontology and traces models back to the actual data storage. The application will then present the relevant information based on this structured approach, which is vital for effective data access and utilisation.
Integration of Ontology and Data in Graph Databases
Howard shares that he has been working on integrating an ontology into a graph using Neo4j Aurora. This involves associating data nodes created in the graph with URIs in the ontology to establish relationships between the data instances and existing ontologies. The goal is to load relevant data into the graph to facilitate preferential reasoning and inference, which supports business needs and decision-making. Additionally, it is essential to understand the specific questions that the business wants to answer and ensure that the associated data products in the graph can support these insights. While there is a possibility of loading only metadata about where to find the data, having actual data in the knowledge graph is beneficial for analysing customer engagements, behaviours, and relationships at a master data level.
An example of BCBS is mentioned, as it highlights the importance of understanding data relationships, particularly in the context of risk analysis within significant businesses and their complex ownership structures. Additionally, utilising graph data to visualise these connections can reveal dependencies among entities, such as how a decline in one business affects others. This is exemplified in a practical instance shared from a central bank, where loading 30,000 balance sheets initially created confusion until relationships were mapped using an ontology, allowing for clearer insights and the ability to filter out irrelevant information. This highlights the need for careful data loading and organisation to enhance analysis and reasoning in complex datasets.
Understanding Data Element and Data Attribute in Database Regulation
Howard wraps up the webinar by noting the distinction between data elements and data attributes when discussed in the context of data management and regulation. Specifically insights from the EDM Council. He elaborates on this by stating that a data element is understood as the physical representation of data, such as a column in a relational database. In contrast, a data attribute refers to its representation in a logical data model, often involving metadata aspects like data type and precision. Ultimately, this differentiation can lead to semantic confusion, as interpretations may vary based on context. Clarity on these terms is essential for effective communication in data quality discussions and practices.
If you would like to join the discussion, please visit our community platform, the Data Professional Expedition.
Additionally, if you would like to be a guest speaker on a future webinar, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!