
The Data Platform Handbook with Jane Estrada

Executive Summary
The Data Platform Handbook, authored by Jane Estrada, provides a comprehensive overview of the essential components and best practices for building effective data platforms in business environments. In this webinar, Jane covers critical aspects such as data domain management, agile development strategies, and the intricate balance between consumer and producer onboarding. She emphasises the importance of data quality, accountability, and decision-making frameworks while addressing identity resolution and the management of Personally Identifiable Information (PII) in banking.
The webinar highlights the significance of data strategy, reference architecture, and governance in organisational development, alongside the challenges of data modelling and ethical considerations. Jane further explores the role of data protection regulations, such as GDPR, and the integration of AI into data processes, offering insights into achieving optimal data management and operational efficiency.
Webinar Details
Title: The Data Platform Handbook with Jane Estrada
Date: 07/07/2025
Presenter: Jane Estrada
Meetup Group: INs and OUTs of Data Modelling
Write-up Author: Howard Diesel
Contents
The Data Platform Handbook with Jane Estrada
Understanding the Structure of Data Platforms
Data Domain Management in Business Processes
Data Management and Agile Development in Master Data Platforms
Consumer and Producer Onboarding in Data Platforms
Data Quality Strategies and Challenges
Identity Resolution and PII Control in Banks
Data Streaming and Scheduling in Business Applications
Accountability and Decision-Making in Data Platforms
Importance of Data Strategy and Reference Architecture in Business Development
Data Architecture and Domain Segregation in Data Platforms
Data Governance and Platform Building
Data Protection and Regulation in Wealth Management
The Challenges of Data Modelling and Domain-Driven Architecture
Ethical Considerations in Governance and Legal Procedures
Placement of Master Data Master Data in Data Platforms
Data Profiling and Unstructured Data in Business
Data Management Strategies for GDPR and the Right to be Forgotten
Integration of AI in Data Processes and Workflows
The Data Platform Handbook with Jane Estrada
Howard Diesel opens the webinar and introduces Jane Estrada. Jane presented her book, ‘The Data Platform Handbook.’ The book focuses on data governance and data architecture and emphasises the importance of linking data architecture to business architecture for optimal technology and platform integration.
Jane, a long-time fan of DAMA and a resident of Toronto, shared that she was originally from Sri Lanka and has a background in political science and computer science. Additionally, she holds a Certified Data Management Professional (CDMP) certification. She possesses extensive experience in data-related roles, including database developer, data modeller, and data architect, primarily in the financial and telecommunications industries.
In her career, Jane has created seven in-house data platforms and authored a book to document her experiences. Jane also emphasises the importance of foundational principles in data platforms, regardless of whether they are built or bought. According to Jane, ‘the Data Platform Handbook’ addresses the integration layers and aims to dispel the notion that past methodologies, like those from Bill Inmon and Ralph Kimball, are no longer relevant in light of modern technologies like NoSQL, presenting data architecture as an evolving discipline.

Figure 1 "Introduction to The Data Platform Handbook"
Understanding the Structure of Data Platforms
A data platform is an ecosystem designed for the efficient distribution of data, enabling producers to publish data once for multiple consumers to access. Centralising data simplifies governance and enhances data quality, making it crucial for effective data strategy, especially when managing numerous applications. Typically, Jane notes, a data platform consists of three layers: the Raw Layer, the Standardised Layer, and the Consumer Specific Layer.
Data sources feed into the platform, while consumers extract data, and mechanisms for data observability and quality ensure integrity. It's essential to source data from relevant, reusable applications to maximise value, and both streaming and batch processing can be utilised for data handling.
In the financial sector, both streaming and batch processes, such as those involving CSV files, are essential for managing data effectively. The data architecture consists of multiple layers: the Raw Layer handles unstructured and structured data, allowing for streaming, storage, and archiving; the Standardized Layer is crucial for organizing data by domain, implementing a common data model, and ensuring data quality; while the Consumer Specific Layer amalgamates various domains to present a tailored view, incorporating elements like customer data, transactions, and products. Additional layers can enhance the platform with virtualisation and analytics capabilities. Properly setting up these foundational components allows for future growth and adaptability of the data infrastructure.

Figure 2 "Agenda"

Figure 3 "What is a Data Platform?"
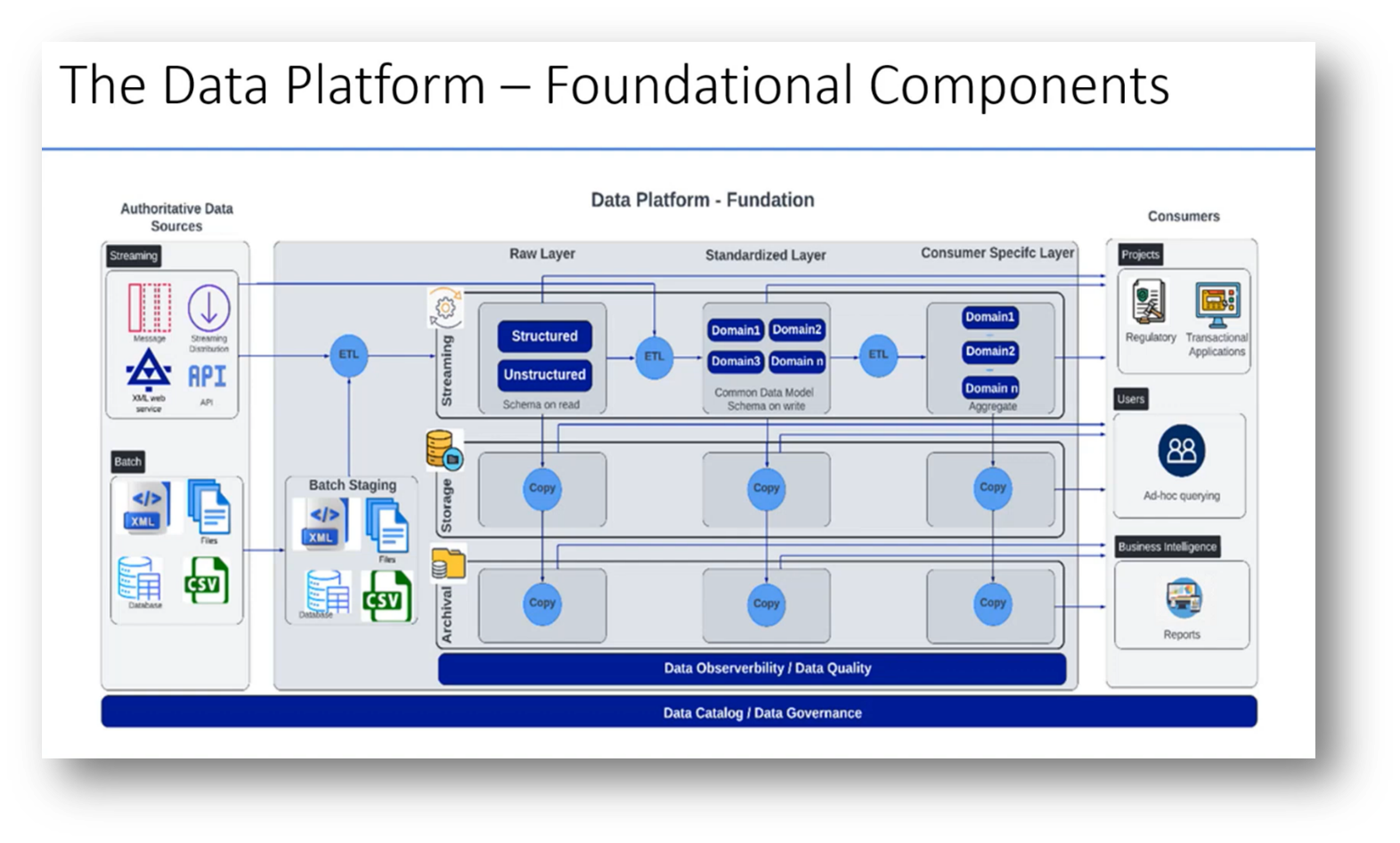
Figure 4 "The Data Platform - Foundational Components"
Data Domain Management in Business Processes
In the business domain, data is structured around various processes that involve multiple domains, each with distinct contexts. To effectively manage data, Jane recommended categorising it by data domains—such as customer, employee, and trade transactions—rather than by specific business processes. This approach enables users to combine data from different realms for tailored analyses in a Consumer Specific Layer that reflects business needs. Additionally, Jane shared that integrating Metadata from the Raw Layer into the Standardised Layer allows for better identification and utilisation of data, facilitating marketing and other business functions by specifying which data is applicable for specific purposes. Unlike conventional frameworks, this model advocates for producers to publish directly to either the landing zone or the standardised layer, streamlining data accessibility and relevance.
Data management practices often emphasise a strict approach, requiring that data first go through a Raw Layer before reaching a standardised layer. However, many modern applications are capable of delivering real-time data in predefined formats, allowing for direct entry into the Standardised Layer without the need for an intermediary landing zone.
This approach enhances flexibility and efficiency, particularly for legacy systems like mainframes that struggle with real-time processing. Traceability remains intact, as these applications can provide a clear lineage from the Standardised Layer back to the data sources. Ultimately, governance should determine data ownership and access rights regarding the pathway to the standardised layer, enabling varied patterns of data processing.
Data Management and Agile Development in Master Data Platforms
Jane focused on integrating a Master Data platform and managing Metadata in data domains. She highlighted the need for agile access control to data, emphasising the importance of cataloguing and establishing data contracts to facilitate effective governance amidst the demand for data consumption. Additionally, an attendee raised their concerns about balancing speedy data ingestion with proper management and understanding of the data, while emphasising the pivotal role of Metadata management in ensuring the success of data platforms. Jane and the attendee discussed the option of embedding Metadata-driven development within the system development life cycle to achieve effective outcomes.
Consumer and Producer Onboarding in Data Platforms
The onboarding process for consumers and producers in a federated data platform emphasises a streamlined approach managed by a small, focused team. Jane shared that the team has ensured that all the data is catalogued, documented, and compliant with service-level agreements. In this instance, consumers can initiate projects, perform data profiling, and collaborate with the onboarding team to address any missing fields by engaging with the respective producers.
This consumer-driven model ensures that all data utilised in the platform meets actual needs. While there is a preference for a federated system, some central governance is necessary for effective oversight and control. Additionally, producer onboarding involves formalisations and potential data modelling, requiring the producers to be actively engaged before building out data pipelines. Ultimately, governance and cataloguing remain critical to the success of this structure.
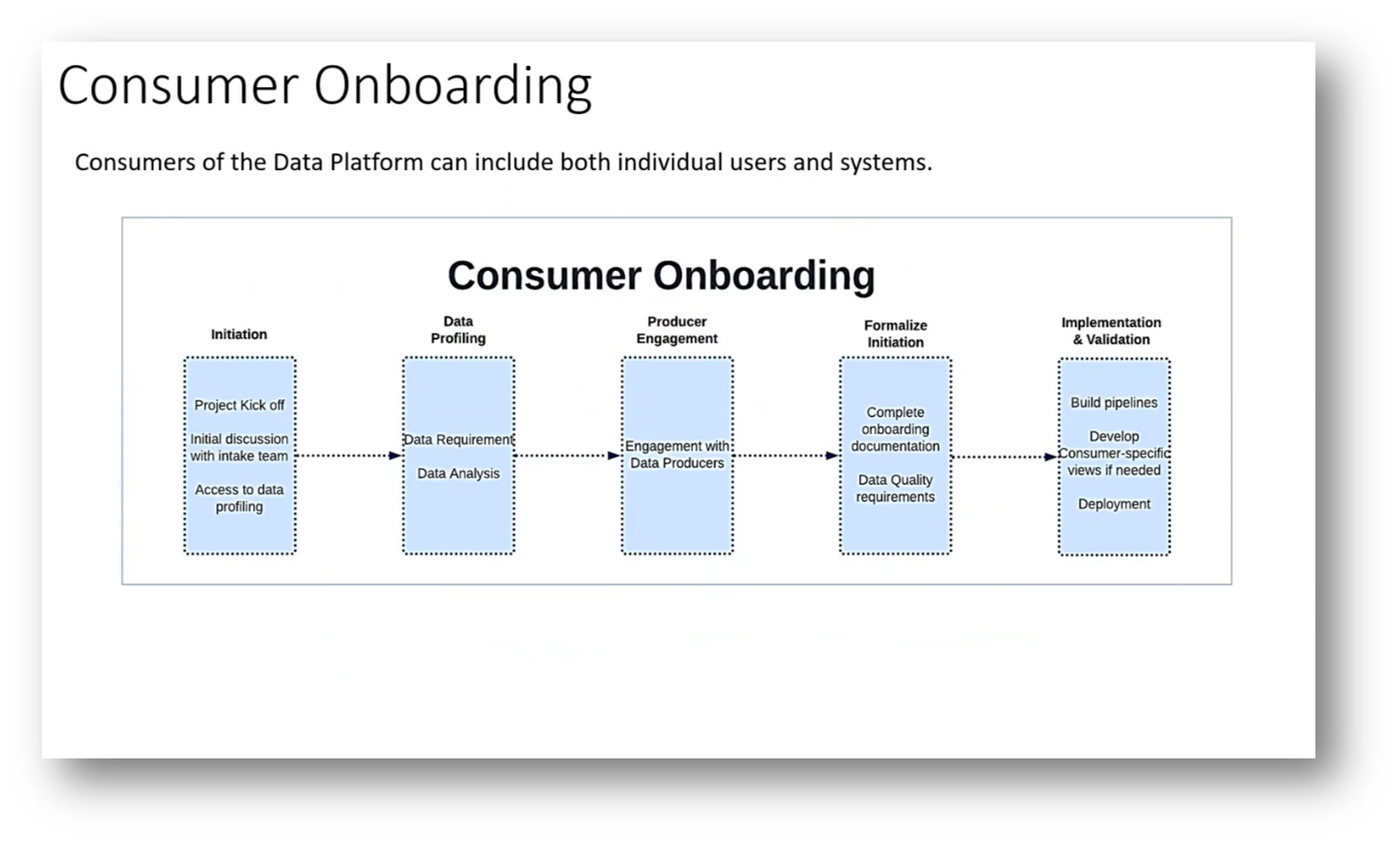
Figure 5 "Consumer Onboarding"
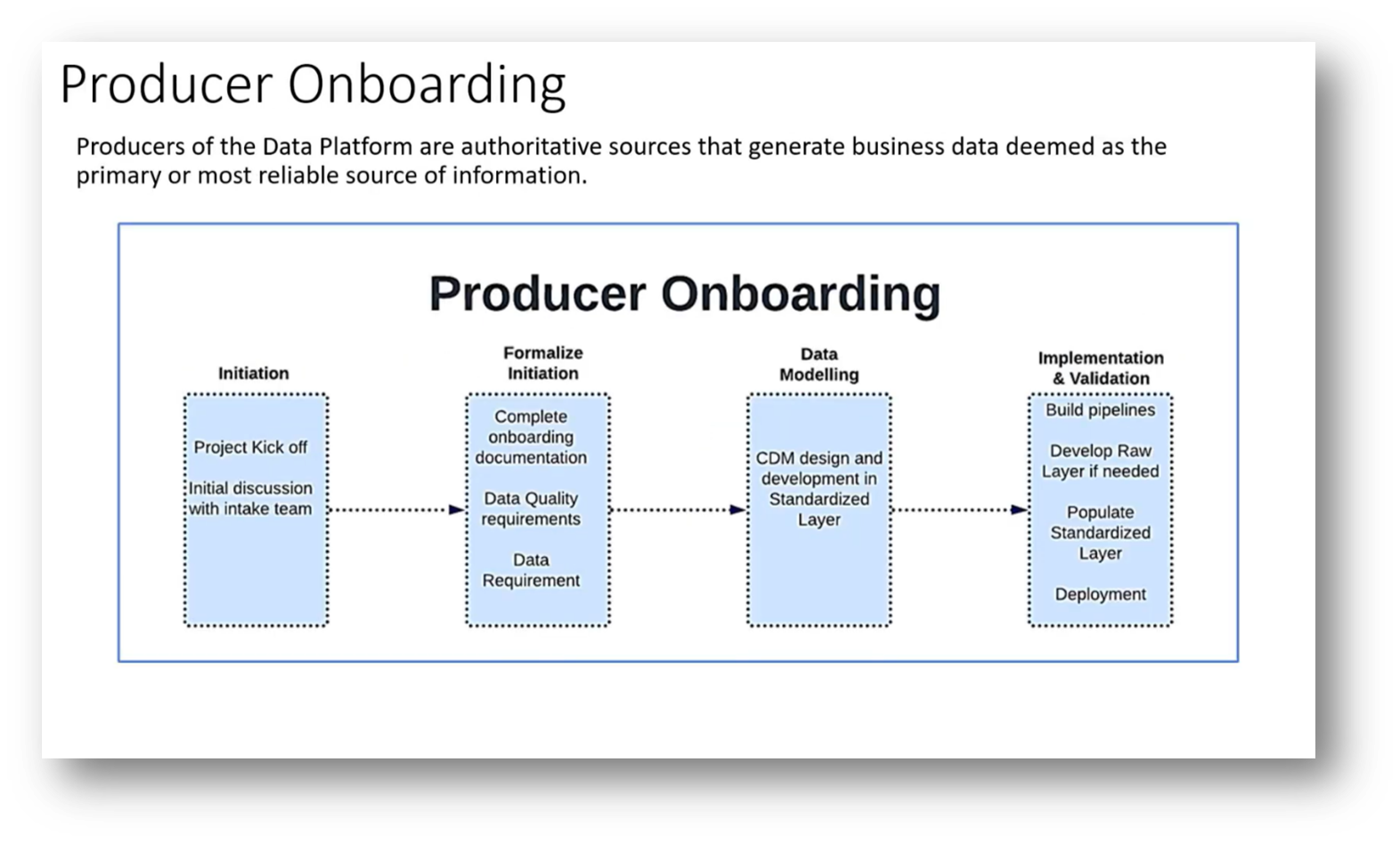
Figure 6 "Producer Onboarding"
Data Quality Strategies and Challenges
Jane discussed the complexities of data quality (DQ) across different stages of data processing. She highlights the importance of balancing early DQ measures with the potential for downstream data failures, emphasising that producers should be responsible for ensuring high-quality data at the source.
Successful strategies involve engaging consumers to identify critical data elements, which must be traceable back to the producers. However, solely placing the burden of fixing data quality on consumers does not address upstream issues. Jane noted that implementing DQ in a Standardised Layer by data domain—focusing on critical identifiers like customer and product IDs—can yield better results than trying to ensure quality at the producer level, especially in environments with numerous applications.
Identity Resolution and PII Control in Banks
An attendee raised a question regarding identity resolution within banking, specifically concerning the challenges posed by customers using different aliases or accounts across different jurisdictions. Jane responded by emphasising the importance of implementing data quality (DQ) layers, which must incorporate access controls for (PII), such as account numbers, and encryption measures.
Access management is more straightforward for consumer-specific views, allowing tailored data aggregation and calculations. It also underscores that consumer expectations dictate data quality, tracing back to the producers and their lineage, while addressing the necessity of standardisation amid evolving market forces within the raw data layer.
Data Streaming and Scheduling in Business Applications
Jane then addressed how data from various applications is processed, focusing on whether it is transmitted in real-time or at specified intervals. In trading data management, real-time streaming is utilised to capture changes as they occur, ensuring timely updates to the data platform. Additionally, she noted that there is a need for end-of-day data aggregation to facilitate reconciliations, emphasising the importance of both real-time and periodic data handling in maintaining business process integrity across various applications.
Accountability and Decision-Making in Data Platforms
The accountability for data-driven decisions lies primarily with the data stewards and system owners responsible for managing specific data domains, such as product, customer, and finance. While consumers utilise this data, they rely heavily on the data’s accuracy and context provided by the owners. As a result, although consumers make business decisions based on the data, they cannot be held fully accountable, as their reliance on the data owners for clarity and standardisation is paramount.
When developing a data platform, it is crucial to consider several key factors before beginning construction. The responsibilities between data owners and data stewards should be clearly defined, as the integrity of the data relies on their collaboration to ensure it comes from appropriate, authoritative sources.
A strong data strategy, effective Master Data Management (MDM), and clear guiding principles are essential for achieving good data quality, even with centralised data. To avoid common pitfalls, organisations should discuss whether to adopt a federated or centralised approach and outline their vision and strategy for data management, emphasising the importance of these considerations over extensive documentation before building the platform.
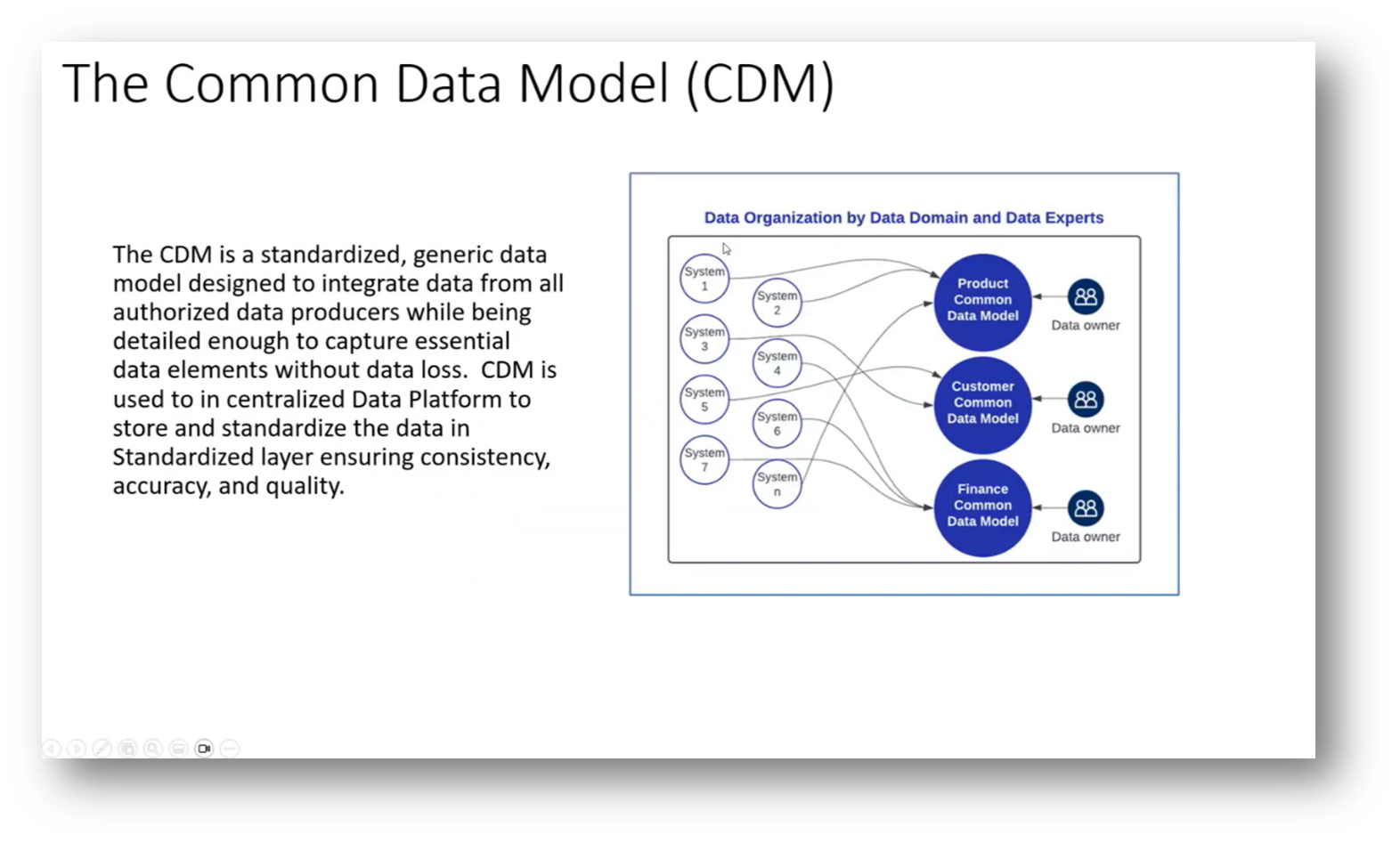
Figure 7 "The Common Data Model (CDM)"

Figure 8 "Methodology"
Importance of Data Strategy and Reference Architecture in Business Development
Establishing a reference architecture that outlines the business requirements across various data layers and latencies is important. This architecture serves as a blueprint for ensuring proper integration of Metadata, Master Data, and data quality considerations within the overall data strategy.
Jane acknowledged that, while it may be possible to start building a platform without a solid data strategy, having a comprehensive plan is crucial for long-term success. She emphasised the need for thoughtful consideration of these foundational elements to avoid pitfalls in the data development process.
Data Architecture and Domain Segregation in Data Platforms
In a discussion regarding the architecture of a data platform, a question was raised about the effectiveness of organising data in a Consumer Specific Layer based on use cases rather than data domains. The attendee highlighted that while the Standardised Layer organises data by domain, modelling data according to consumer requirements could enhance access to multiple domains simultaneously. However, Jane responded by emphasising the importance of maintaining normalisation in the Consumer Specific Layer to facilitate long-term maintenance and evolution of the data structure.
Jane shared on a previous engagement where a consulting firm recommended only dimensional modelling, expressing concerns about its effectiveness in larger enterprises where normalisation is crucial for managing complexity. The conclusion was to keep the foundational data layer normalised while allowing denormalisation and aggregation in the Consumer Specific Layer to meet varied use case demands.
A strong recommendation was made against incorporating aggregated data in the Standardised Layer of data architecture; instead, Jane emphasised the importance of keeping aggregated data within specific consumer domains. Additionally, an attendee agreed that while dimensional models can be used in the consumer layer, the Standardised Layer should adhere to a common data model, preferably aligned with the principles of the Microsoft Common Data Model, which facilitates the integration of multiple data sources into a more standardised structure, albeit not strictly following third normal form.
Data Governance and Platform Building
The role of a Data Governance Analyst, particularly in relation to data governance and platform development, underscores the importance of establishing metrics and KPIs to monitor data quality. Additionally, key elements for governance include the effective onboarding of data consumers and producers, which necessitates collecting contact information, service level agreements (SLAs), field-level details, and examples of error handling processes.
Jane stressed that data mapping should be the responsibility of those placing the data, rather than a central team. She highlighted the need for balancing IT-driven platform development with business requirements, noting that while IT teams often lead the process, it's crucial to align the platform with business needs to ensure effective governance.
A discussion then highlighted the challenges of collaboration between IT, the Chief Data Officer (CDO) team, and the business team in understanding and clarifying requirements for data-driven projects. Many in the business team may struggle to grasp the long-term benefits of these initiatives, leading to reluctance in engagement.
Jane suggests that effective communication and collaboration among all three teams are essential, with the CDO team playing a pivotal role in providing business requirements that the IT team can act upon. Additionally, reference architectures focused on industry standards can help align the value proposition and value chain to ensure that the organisation's deliverables meet customer needs. Sharing these frameworks could enhance understanding and foster cooperation among the teams.
Data Protection and Regulation in Wealth Management
An attendee raises a question around data protection for a project involving a corporate client, specifically in the context of wealth management. They asked whether the Register of Processing Activities should include not only systems of record but also backup systems, as this aligns with data protection regulations.
Jane responded by emphasising the importance of encrypting sensitive Personal Identifiable Information (PII), such as account numbers and Social Security Numbers (SSNs), throughout the data flow—from source to consumer end—ensuring compliance with legal requirements for highly confidential data. She added that any processing activities must be accurately documented and regularly reviewed in the respective registers.
Another attendee asked a question around the management of client information, specifically regarding the handling of Social Insurance Numbers (SINs) by brokers and financial advisors. Jane shared that only authorised personnel, such as brokers who have signed the appropriate documents, should have access to clients' SINs and private information, while IT staff and others should not. Additionally, the attendee noted concerns about the misuse of SINs as primary keys for client searches by business teams, which raises legal and ethical issues. Jane responded again, stressing the need for proper protection of client data, alongside a surprise at the lack of adherence to these legal requirements.
The Challenges of Data Modelling and Domain-Driven Architecture
Jane highlighted the importance of data models within data architecture, particularly in the context of domain-driven design. Despite the prevailing notion that data modelling is obsolete due to its complexity and time-consumption, Jane, a data modeller, argues against this viewpoint. She emphasised the necessity of having real data models to ensure accurate data generation and consumption.
While many professionals seek shortcuts through industry models or frameworks, such as FSDM, these alternatives often fail to meet specific needs. The speaker advocates for a more flexible approach to data modelling, recognising that while perfection in data models is unattainable, they should effectively serve as blueprints to fulfil organisational requirements.
Jane then spoke to the importance of data modelling as a foundational map for understanding data production and quality, contrasting this with the current trend of minimal data modelling in environments like data lakes. Despite the popularity of models such as the medallion architecture by Databricks, the speaker argues that effective data models are crucial, especially in structured data environments like finance, where they can reveal the intricacies of data source and lineage. Ultimately, business processes should drive data modelling to ensure that the resulting structures meaningfully inform data consumption.
Ethical Considerations in Governance and Legal Procedures
An attendee is then advised to consult the GDPR practice notes by another attendee, who added that the practice notes can provide valuable insights into compliance issues. By identifying specific concerns through these notes, she can present them to the legal team to address governance challenges and ensure they align with legal standards. The attendee recommended exploring the official GDPR website for relevant information, using targeted keywords to delve into detailed precedents and guidelines. Additionally, Jane highlighted the importance of legal accountability and emphasised that responsibilities should not all fall on an individual.
Placement of Master Data Master Data in Data Platforms
The Master Data Management (MDM) role in a data platform involves cleansing, matching, and generating unique identifiers for data, which differs from the data platform's function of distributing standardised data without performing extensive matching or cleansing.
While some organisations, including the one mentioned, may place MDM within the platform's "golden zone" or standardised layer, it is suggested that MDM should operate externally to the platform to effectively create golden records by merging and matching in the source systems. This approach poses challenges, as operational teams are necessary to address errors and manage updates and deletions, which are typically not handled by the data platform itself, as it focuses instead on data insertion.
Data Profiling and Unstructured Data in Business
Data profiling is essential for effective consumer onboarding; however, it is often overlooked, particularly when distinguishing between structured and unstructured data. While structured data is typically prioritised for profiling, unstructured data also holds significant value, especially if it contains critical business information such as memos.
Data architects need to support data scientists in profiling both types of data to ensure their quality and usability. Although certain data, such as technical error logs, may not warrant extensive profiling, key unstructured data should be properly governed. Tools such as JSON documents and Postgres support unstructured formats, facilitating this process and ultimately helping businesses make informed decisions.
Data Management Strategies for GDPR and the Right to be Forgotten
Jane emphasised the importance of accommodating GDPR requirements within data platforms, particularly in relation to consumer rights such as the right to be forgotten. She highlighted the challenge of managing data retention in a system characterised by append-only databases, where deletion is not a standard practice.
To comply with GDPR, businesses must implement mechanisms for purging outdated account data, particularly for closed accounts that are over nine years old. This can be done annually through batch processes. Furthermore, organisations must ensure the ability to remove individual consumer data upon request, rather than solely relying on a predetermined retention cycle.
A discussion between Jane and attendees then highlighted the challenges of data deletion in systems handling large volumes, particularly emphasising the need for a more frequent delete strategy rather than an annual approach. It notes the importance of separating data into layers—streaming, storage, and archival—while acknowledging that many projects require retention of data for the first three years.
In South Africa, the Protection of Personal Information Act (POPIA) affords individuals the right to be forgotten; however, businesses may be required to retain certain data to comply with legal obligations. As a solution, some organisations opt to mask rather than delete data, allowing for privacy while still retaining necessary records for operational and regulatory purposes.
Lastly, Jane focused on the challenges of managing personal data under GDPR, particularly regarding the right to be forgotten and the complexities of removing individual records from interconnected databases. She emphasised the importance of businesses complying with regulations not only internally but also with third-party stakeholders, who must adhere to the same data protection rules. Additionally, a key point is the necessity of establishing processing agreements, rather than just sharing agreements, to ensure that downstream data handlers manage personal information appropriately, especially in contexts involving data usage for AI.
Integration of AI in Data Processes and Workflows
The integration of AI into data processes and workflows is a key focus for many companies, prompting discussions on its placement within data platforms, such as under business intelligence or closely integrated across various data layers. Opportunities for AI utilisation include enhancing data catalogues by automating the discovery of technical Metadata and facilitating ad hoc querying through tools like Google Gemini, which can generate queries for data extraction.
The concept of a data lake house—a combination of a data warehouse and a data lake—further emphasises this integration, allowing for big data to flow into warehouses and become actionable sources when linked to specific processes. This evolving architectural approach is paving the way for more efficient data management and analysis.
The integration of AI into business processes requires that AI models produce results that can be effectively channelled back into the data warehouse, enabling traceability and justifying decision-making. Many use cases for AI emerge within pre-existing data infrastructures, but issues can arise, such as incomplete data or incompatible formats that prevent the execution of specific AI models.
This can lead to data leakage, where necessary data is not readily available for immediate integration into AI processes. To address this, firms may need to operate outside their current setups initially. It’s essential to consider the value proposition when approaching data warehousing, which includes identifying and acquiring the missing data necessary for optimal model performance.
The process of integrating data into a platform requires careful governance to ensure accessibility for users, such as machine learning models or reporting tools. Timeliness is crucial; delaying the inclusion of new data sources can result in users seeking alternative solutions, which disrupts data flow and visibility.
Effective data management hinges on the quality of the data being processed, as inadequate or missing fields can significantly hinder AI functionality both within and outside the platform. Therefore, swift and efficient data landing is essential for maintaining operational effectiveness.
A key point Jane highlighted was the importance of traceability in AI systems, as many algorithms lack this feature. Establishing traceability involves creating small steps between processes, which can enhance understanding and accountability. Jane noted that responsible AI practices emphasise Metadata, elevating its significance to match that of the data itself. Effective management of both Metadata and data is crucial, especially as companies face legal challenges related to decisions made years prior that impact individuals' lives. Lastly, Jane underscored the necessity of meticulous oversight in AI systems to prevent potential liabilities.
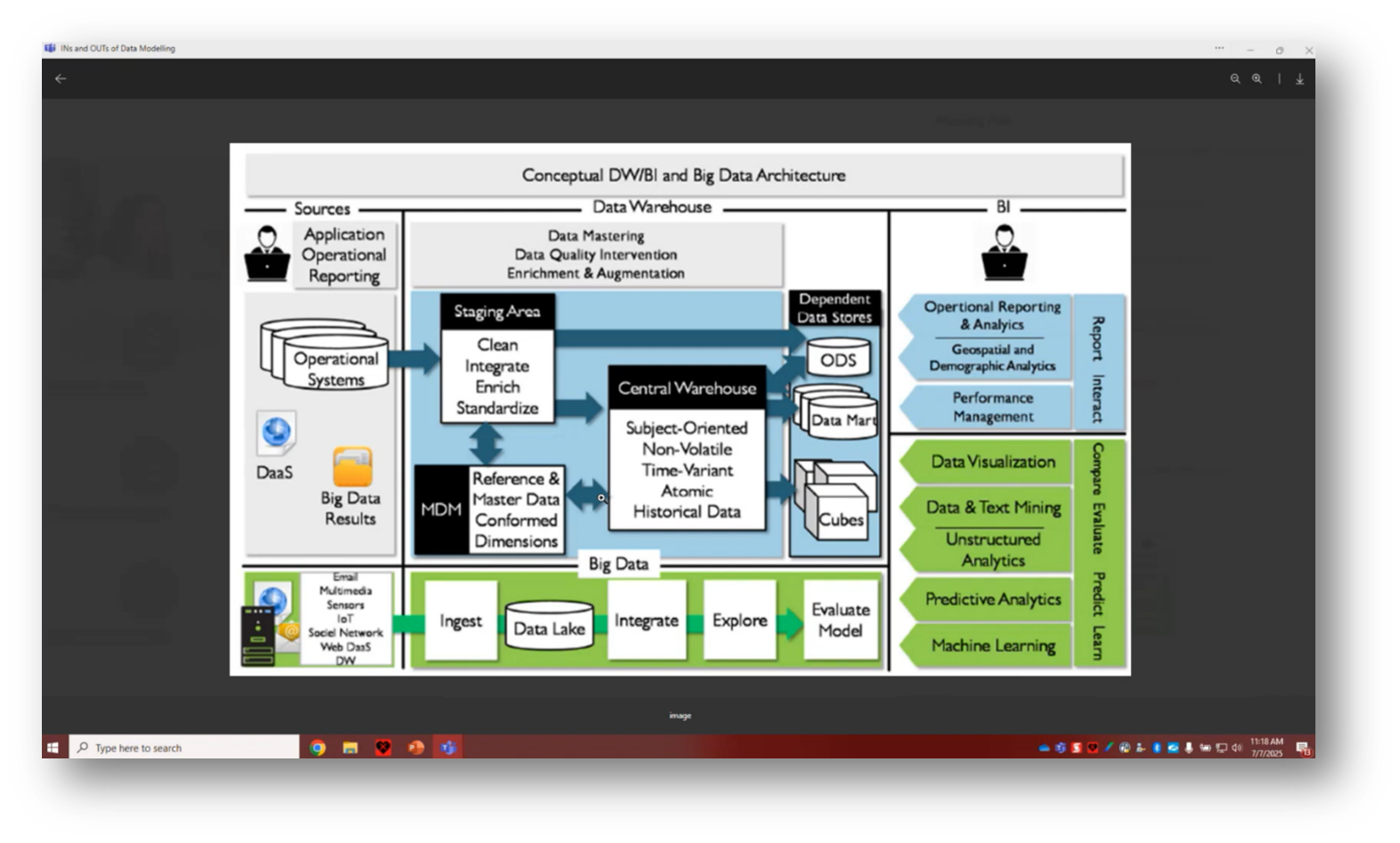
Figure 9 "Conceptual DW/BI and Big Data Architecture”
If you would like to join the discussion, please visit our community platform, the Data Professional Expedition.
Additionally, if you would like to be a guest speaker on a future webinar, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!