
Reference & Master Data Management for Data Citizens

Executive Summary
This webinar delves into the critical aspects of data management. The webinar encompasses the key responsibilities of data stewardship, challenges and strategies in data and quality management. Additionally, Howard Diesel shares an understanding of Multidimensional Databases (MDB) and their application in data quality, as well as the significance of data reliability and trustworthiness. Furthermore, he shares data integration, quality management in DQ projects, the role of technology in data management and user experience in project management. Howard covers using new and existing records in data management and compliance, the selection of identifiers in data assessment, modelling and identifiers, and managing record matching in data stewardship.
Webinar Details
Title: Reference & Master Data Management for Data Citizens
Date: 19 September 2024
Presenter: Howard Diesel
Meetup Group: Data Citizens
Write-up Author: Howard Diesel
Contents
Data Management and Data Stewardship in Training
Data Management and Decision Mandates
The Key Responsibilities of Data Stewardship
Challenges and Strategies in Data Management and Quality Management
Understanding the MDB Dimensions and Application in Data Quality
Understanding the Importance of Data Reliability and Trustworthiness
Understanding and Implementing Trust in Data Management
Data Integration and Quality Management in DQ Projects
The Importance of Data Management and the Role of Technology in Data Management
Data Management and the User Experience in Project Management
Data Quality and Reference and Master Data Management
Navigating External Data Subscription and Standards
Challenges and Importance of Data Management in AI and Cloud Computing
Importance and Management of Reference Data
Challenges of Master Data Management
Understanding Data Model Management and Record Acquisition
Use of New and Existing Records in Data Management and Compliance
Importance and Selection of Identifiers in Data Assessment
Data Modelling and Identifiers
Understanding and Managing Record Matching in Data Stewardship
Data Management and Data Stewardship in Training
Howard Diesel opens the webinar by greeting the attendees. He shares that this session in the series of ‘Reference & Master Data Management’ will emphasise the importance of collecting comprehensive information and supporting documentation. It will also be helpful for those who are considering the specialist exam. The webinar covers categories of data, different channels, Master Data, Reference Data stewardship, and the standard operating procedures involved. Howard uses this list to highlight the increasing significance of data stewardship in organisations, noting the rising trend of technical professionals taking on data steward roles.

Figure 1 Master & Reference Data Management Series: Data Citizen
Data Management and Decision Mandates
Last week's session, ‘Reference & Master Data Management for Data Managers,’ focused on various aspects of data management regarding the responsibility of Data Managers. Howard used exam sample questions, taken from the Data Management Body of Knowledge’s (DMBoK) revised material. Additionally, he shared key points on Reference and Master Data and the readiness assessment. Howard highlights the importance of decision mandates for data managers and citizens. He elaborates on categories such as big bet decisions, delegated decisions, ad hoc decisions, emergency updates, and temporary data needs. It was revealed that the data steward and citizen are responsible for a significant number of implementation decisions, thus emphasising the critical role they play in the data management process.
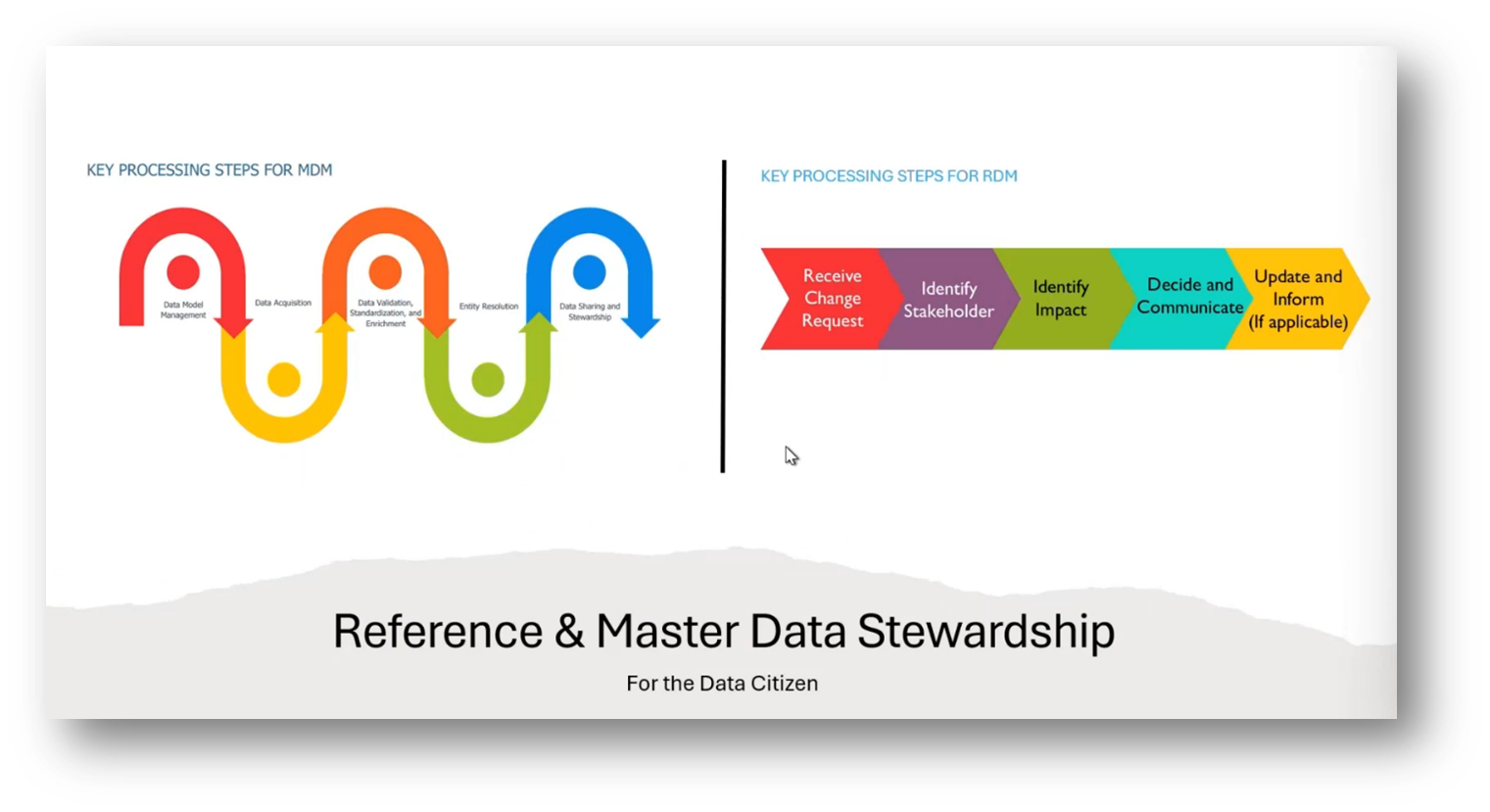
Figure 2 Reference and Master Data Stewardship
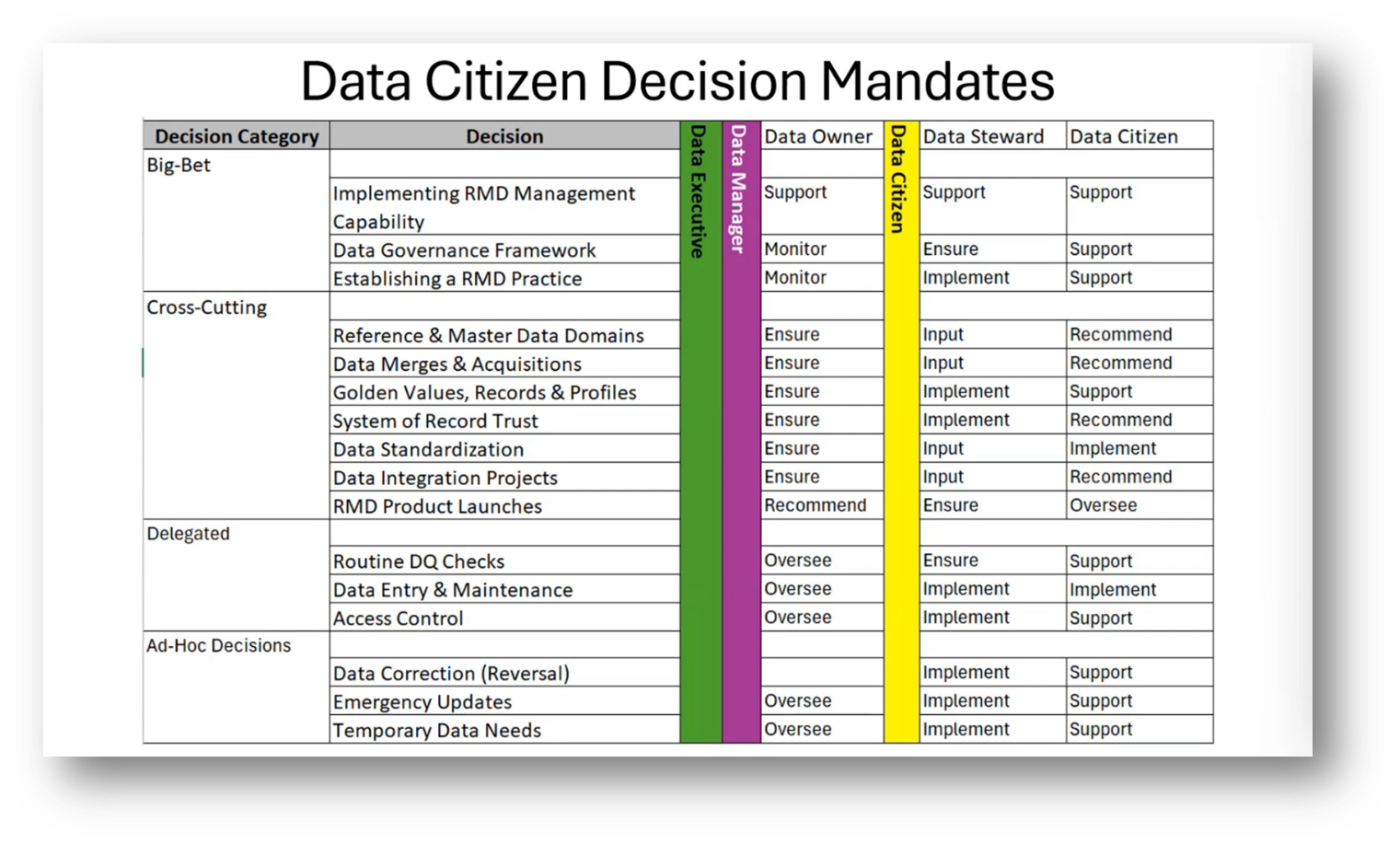
Figure 3 Data Citizen Decision Mandates
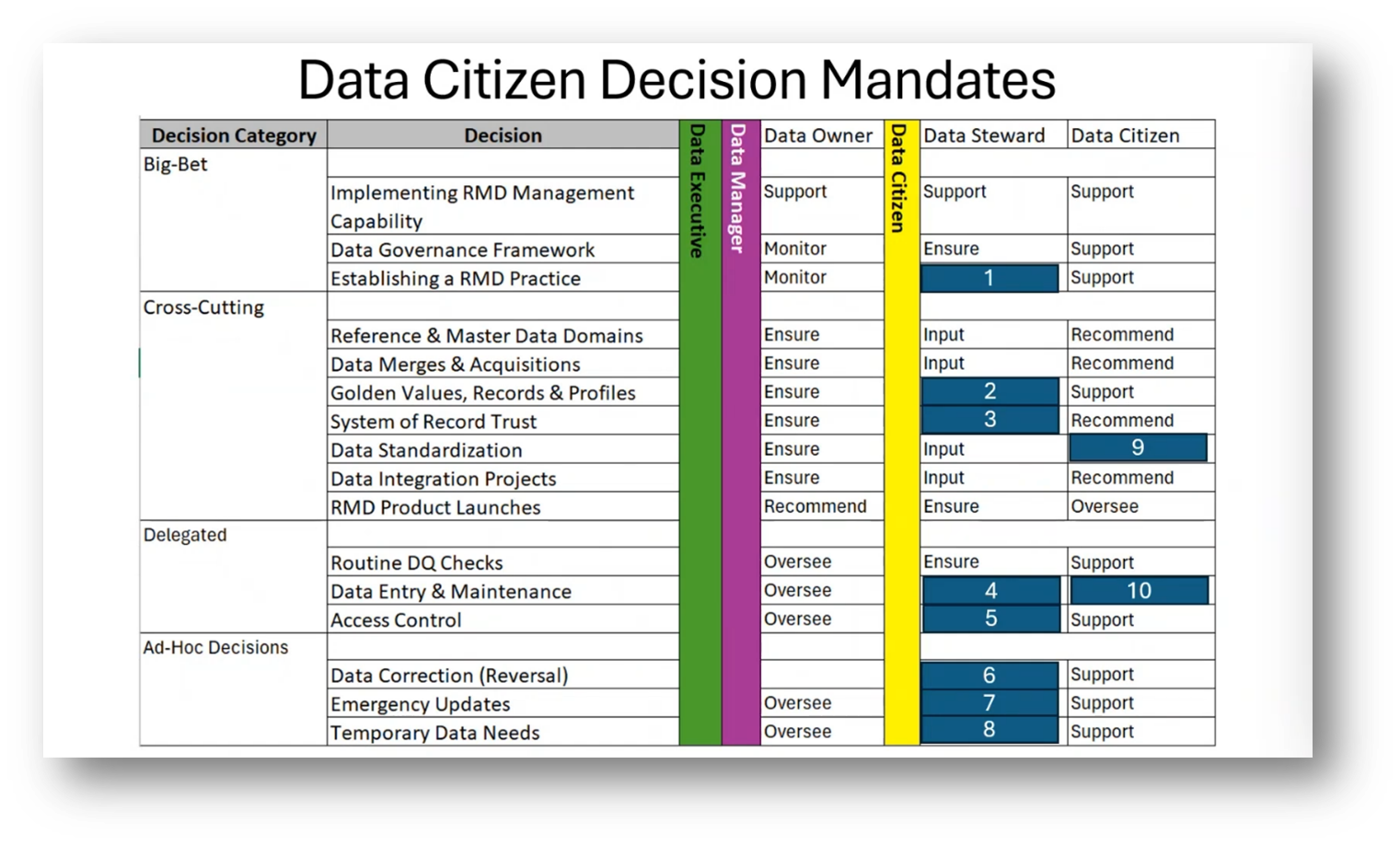
Figure 4 Data Citizen Decision Mandates continued
The Key Responsibilities of Data Stewardship
The key stewardship responsibilities include data quality assurance, Data Governance, compliance, education on best practices, and advocacy for the value of Reference and Master Data. Stewards ensure that policies are implemented and maintained while also educating others about the impact of their actions on data quality. They advocate for the benefits of Reference and Master Data, championing its reliability and serving as a sounding board for its improvements.

Figure 5 Key Responsibilities of RMD Stewardship
Challenges and Strategies in Data Management and Quality Management
In the transition from being “application-centric” to “data-centric,” the main challenges are breaking down silos and addressing limited resources. The focus is on establishing an authoritative source to move data to the organisational level. Additionally, managing duplicate records, ensuring regulatory compliance, and addressing data privacy. DQ work focuses on the total data quality management methodology, specifically establishing a Reference and Master Data environment. This involves assessing metadata quality, data architecture, data definition, and data lineage. Lastly, the methodology measures the cost of non-conformance to make a business case for improving Reference and Master Data.

Figure 6 Common RMD Challenges
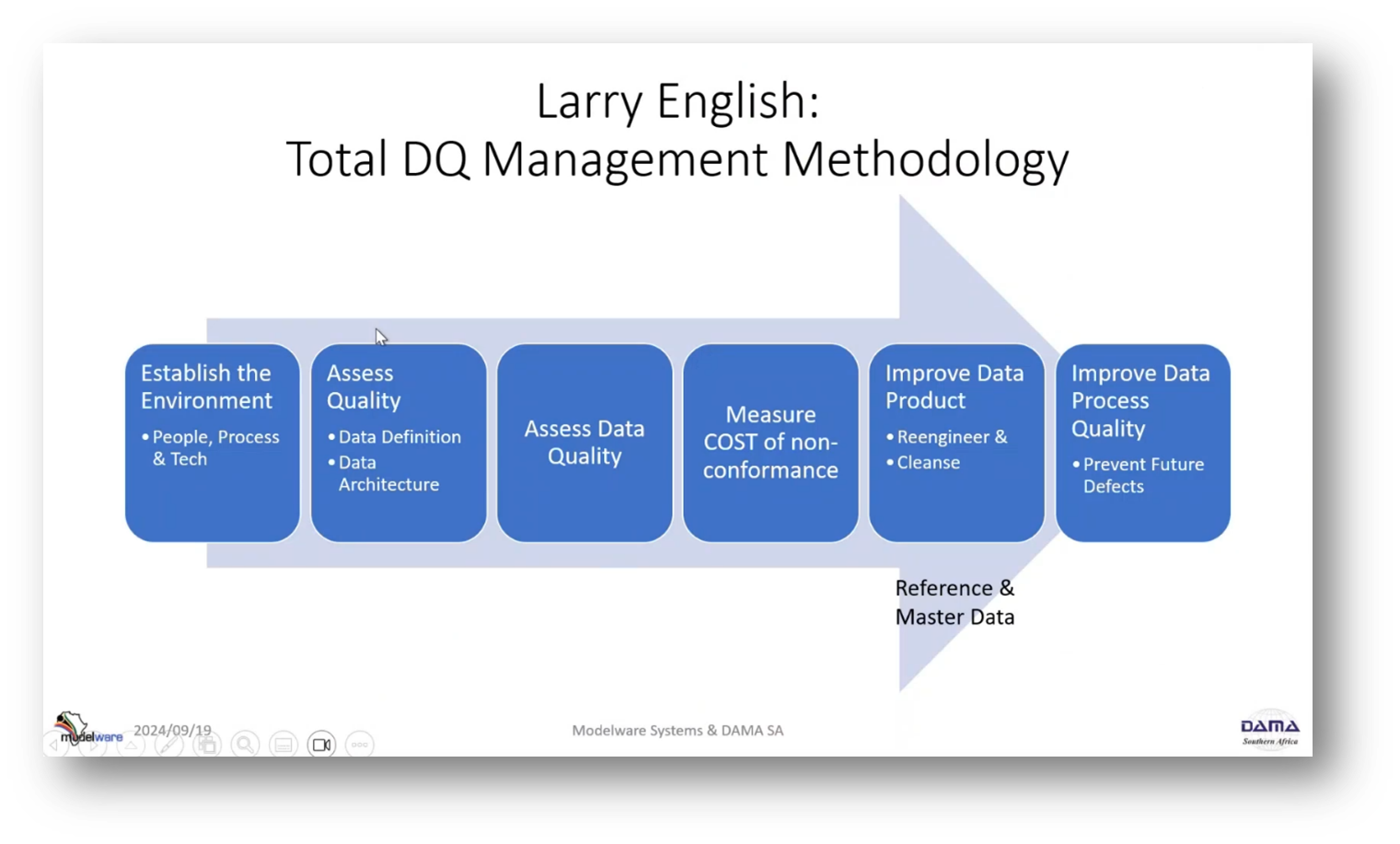
Figure 7 Larry English: Total DQ Management Methodology
Understanding the MDB Dimensions and Application in Data Quality
It's important to consider data quality dimensions in data management, which can be categorised as “intrinsic” and “contextual.” Intrinsic dimensions are measurable at the data level, while contextual dimensions are based on the data's use case and fit-for-purpose. The DAMA definition from the UK is a good starting point, but it's crucial to customise dimensions to fit your business’s specific needs. Additionally, a five-step approach can be used to address data quality challenges. Start by identifying pain points, then select appropriate quality dimensions, measure internal consistency, and ensure the reliability and trustworthiness of the data.
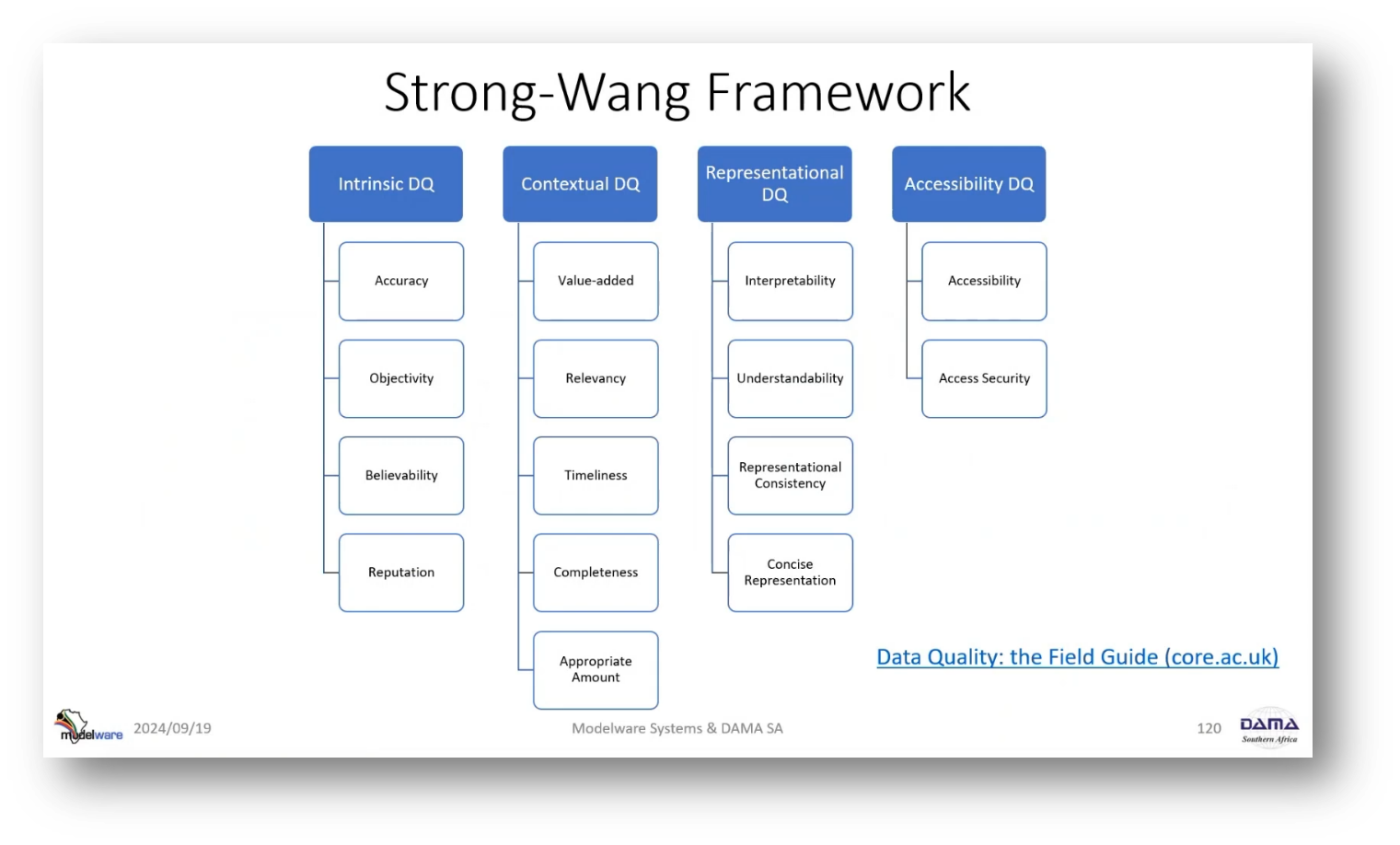
Figure 8 Strong-Wang Framework

Figure 9 Context Data Quality

Figure 10 Putting Data Quality Metrics into Practice
Understanding the Importance of Data Reliability and Trustworthiness
For making informed data-driven decisions, Howard emphasises the importance of data reliability and trustworthiness. The distinction between reliability and trustworthiness is based on internal data quality dimensions and a measure of how well data can be counted on to be of high quality. The concept of "data downtime" describes periods when data is partial, erroneous, missing, or inaccurate. Thus, leading to service interruptions and hindering analytical processes. The development of reliability and a culture of trust to establish a score that garners business advocacy requires earning and quantifying data trust. Overall, preventing dirty data and ensures that organisational data is healthy and ready for action.

Figure 11 DQ High-Quality Data
Understanding and Implementing Trust in Data Management
Howard introduces a trust scorecard to shift from traditional definitions of reliability to a more comprehensive approach. This scorecard includes achieving data trust through testing, rating, and certification by other users. Additionally, trust rules are defined for evaluating data sources that will become the system of record. Thus, it is important to consider factors such as source priority, data freshness, field level scores, cross validation, consistency checks, and historical accuracy. Master Data is critical, with identifiers being the most crucial elements, followed by core fields and other attributes. Implementation styles, such as registry, hybrid, and repository, determine the focus and priority of work and guide the search for local data sources.
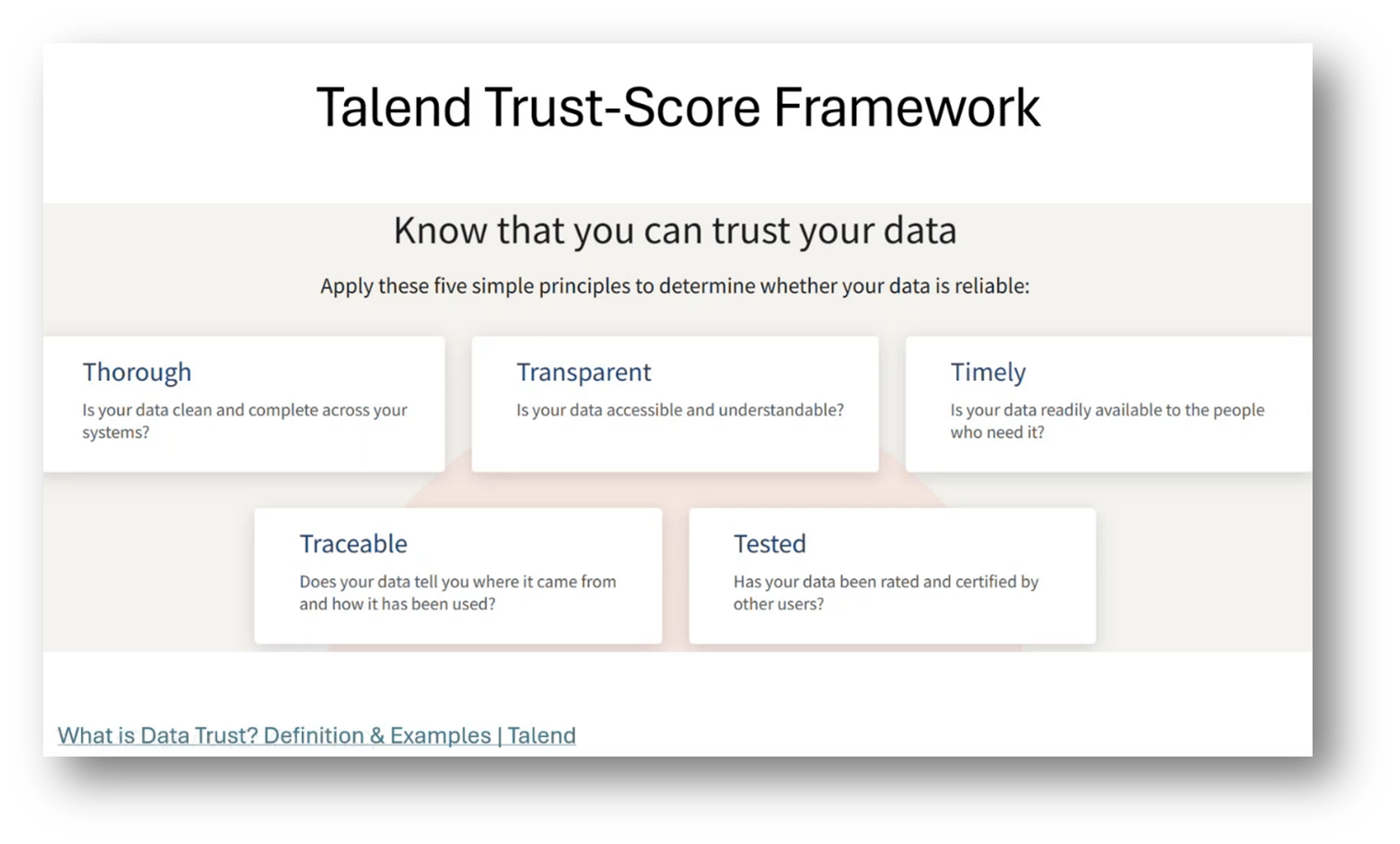
Figure 12 Talent Trust-Score Framework

Figure 13 Talent Trust-Score Framework Reliability and Trustworthy
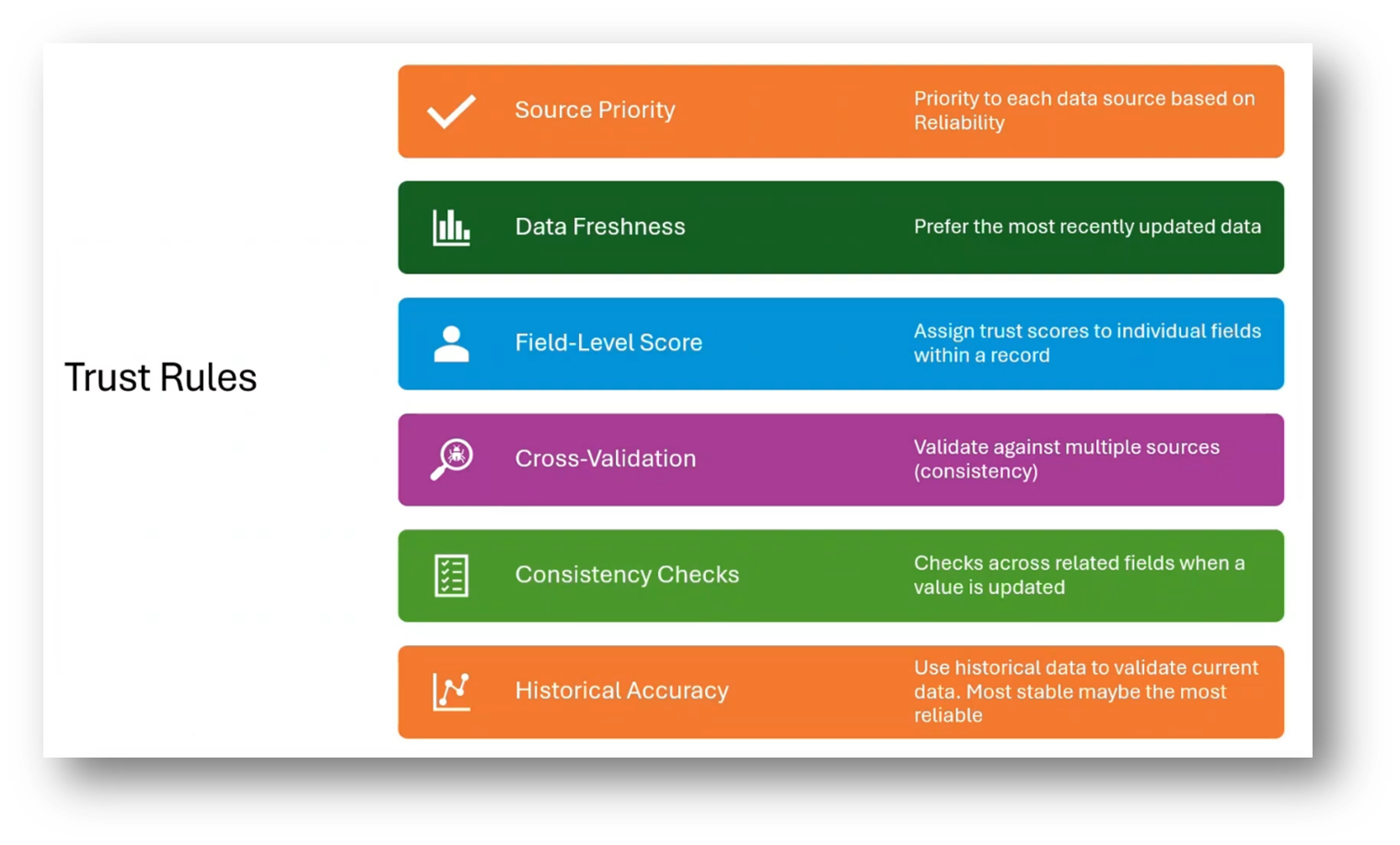
Figure 14 Trust Rules

Figure 15 MDM Implementation Style: What Fields Types go where?
Data Integration and Quality Management in DQ Projects
The DQ projects for Reference Master Data (RMD) primarily focus on data integration and data quality work to support the system of record. The key elements include understanding the system of record's data trust expectations and evaluating its trustworthiness. This involves conducting data discovery, working through the data catalogue, performing data trust assessments, data quality profiling, and data quality assessments. Additionally, root cause analysis and addressing data quality issues are essential before labelling a data source as useless.
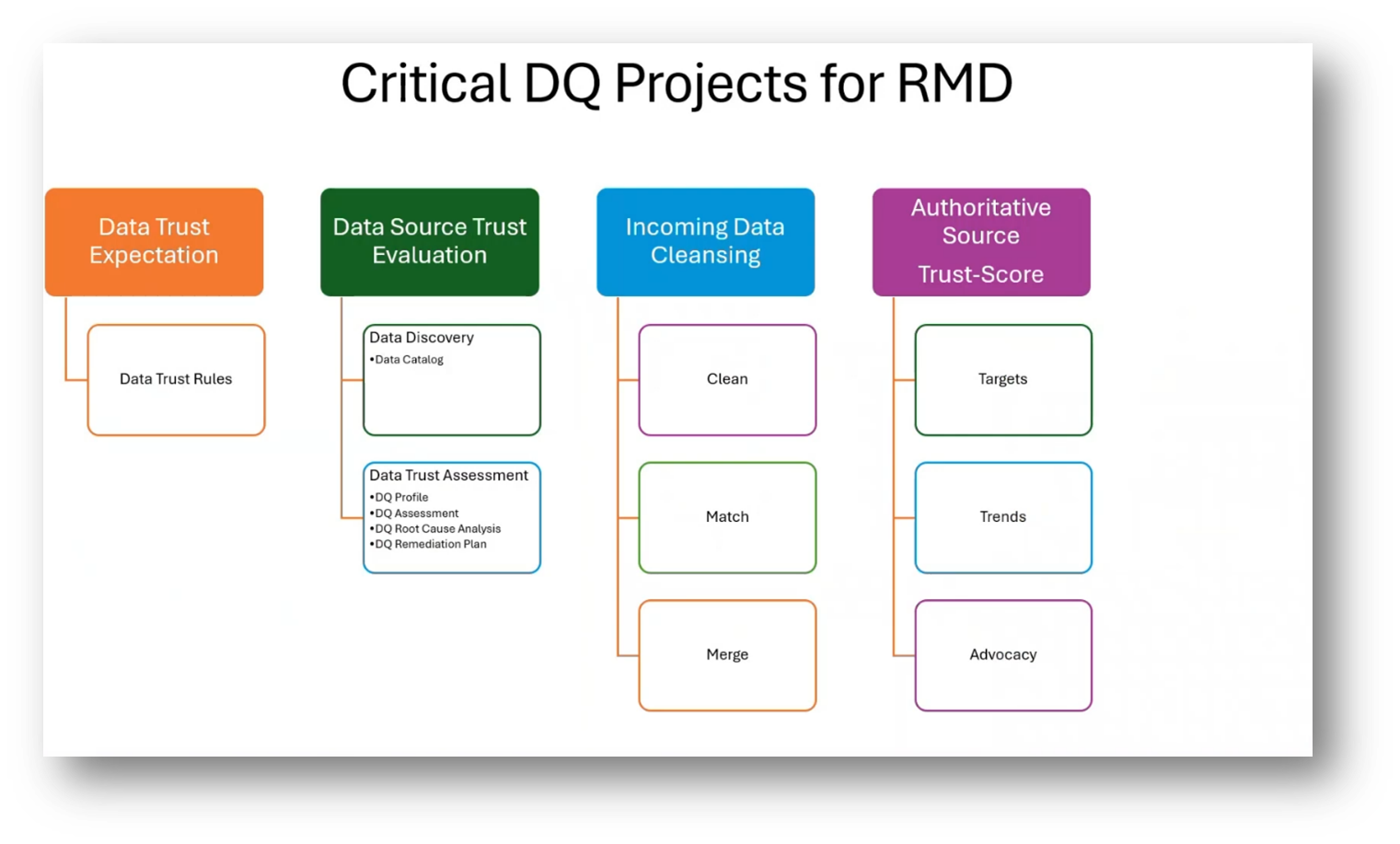
Figure 16 Critical DQ Projects for RMD
The Importance of Data Management and the Role of Technology in Data Management
The process involves establishing a single source of truth for data, ensuring data cleanliness, and evaluating the trustworthiness of authoritative sources. It's crucial to synchronise applications with this single source of truth to align reporting with accurate data. While technology plays a significant role, it's essential to understand that tools alone cannot solve all data management challenges. Manual processes, discussions with data stewards, and subject matter experts are necessary to establish data quality expectations before handing it over to a tool. Ultimately, the success of data management relies on effectively combining people, processes, and technology and not solely on the tools themselves.
Data Management and the User Experience in Project Management
There are challenges to consider when working with data in a DQ project within a Reference and Master Data context. Such as gaining the user's trust in the data and addressing data silos. Thus, it is imperative to understand the users' needs and transform them into “data cheerleaders.” Tools can help with user trust and data silos, but there is still a long way to go in this regard.
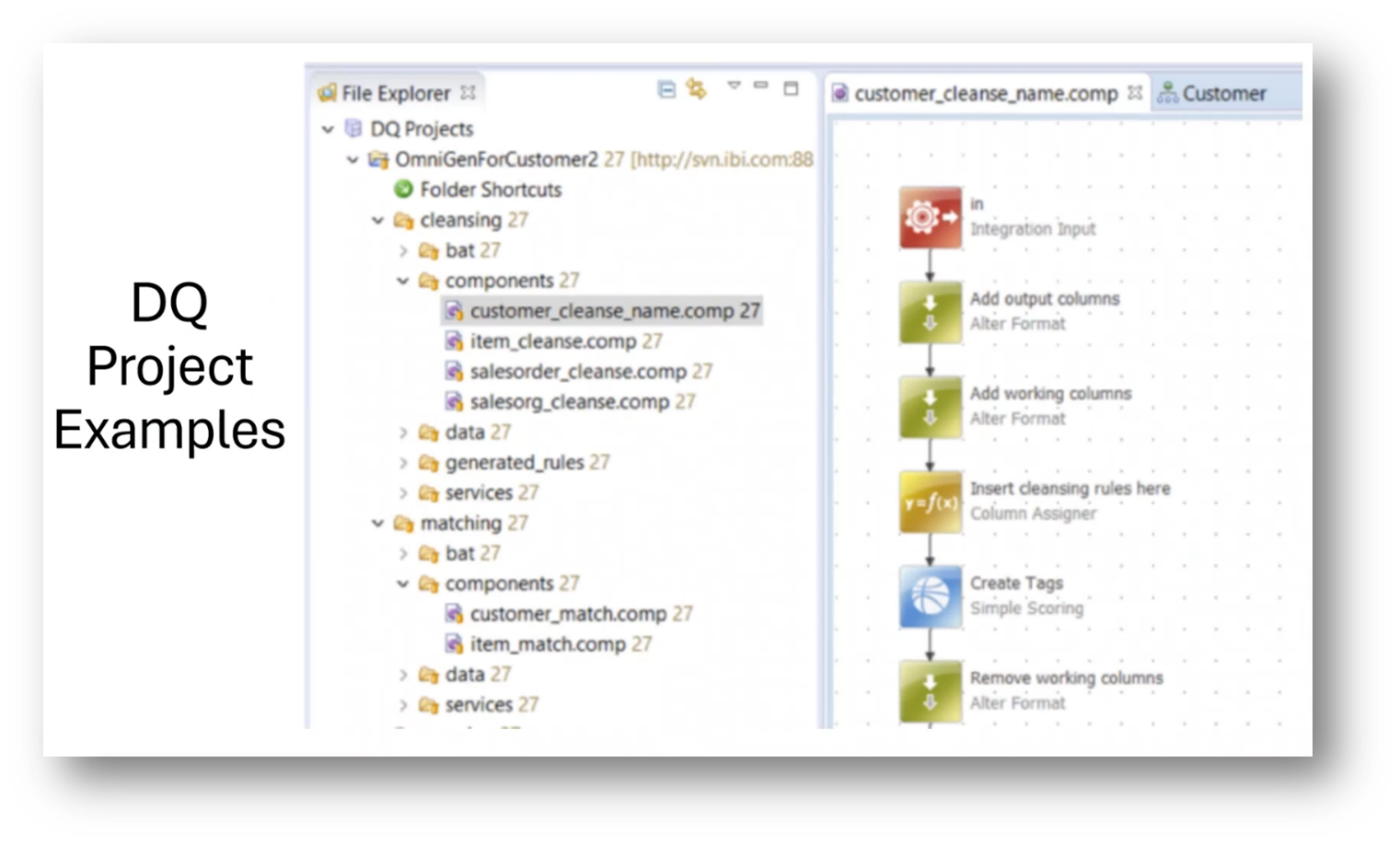
Figure 17 DQ Project Examples
Data Quality and Reference and Master Data Management
Managing Reference and Master Data in a data quality (DQ) project involves handling change requests, identifying stakeholders, and establishing a Reference data working group. Managing international standards and regulations for Reference data, such as country codes and currencies, is crucial as they frequently change. It's essential to have a data steward responsible for ensuring the accuracy and currency of Reference data, as even small errors can have significant repercussions.
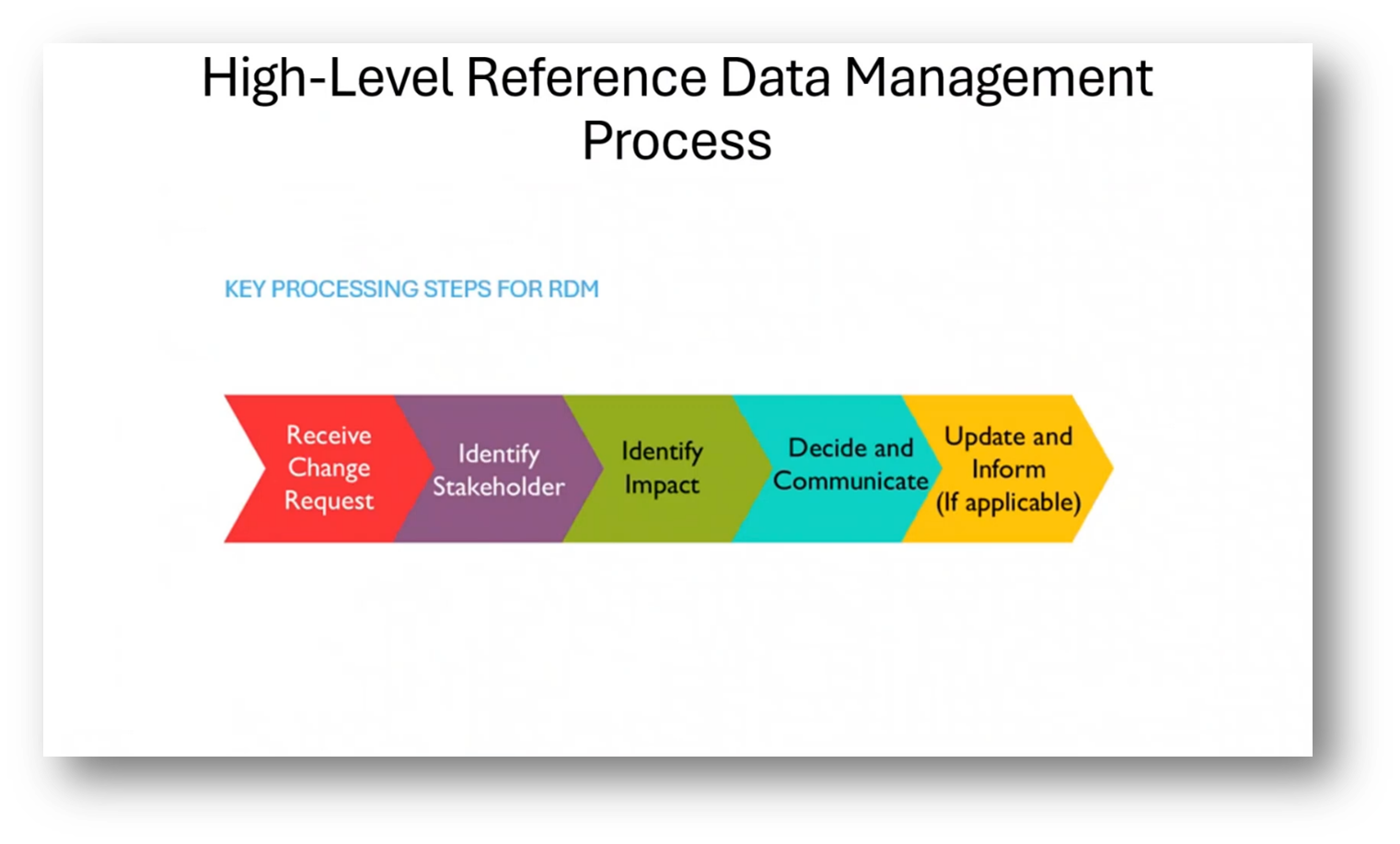
Figure 18 High-Level Reference Data Management Process
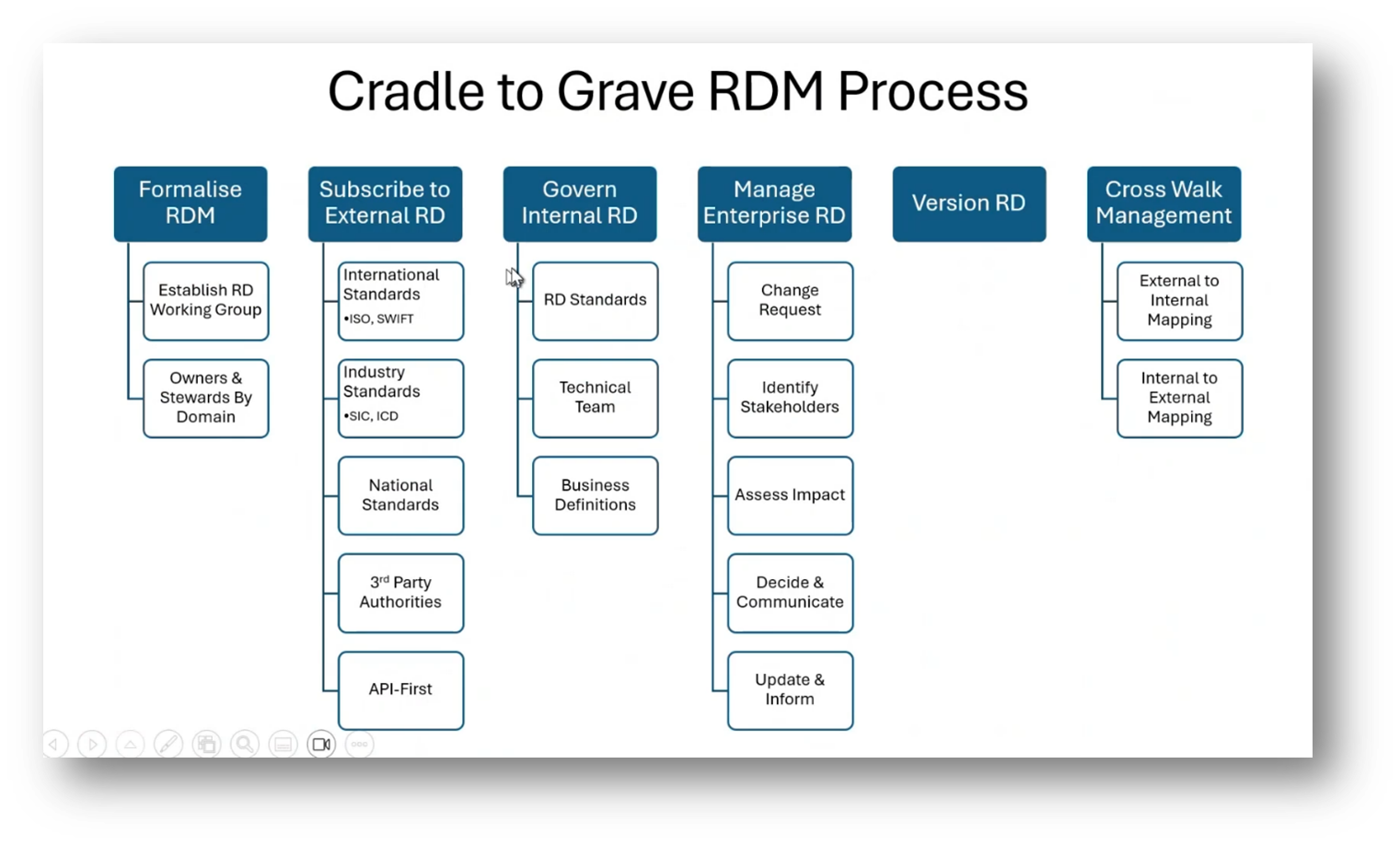
Figure 19 Cradle to Grave RDM Process
Navigating External Data Subscription and Standards
When subscribing to external Reference data, consider obtaining data from third-party authorities and adhering to international, industry, and national standards. Using APIs for data retrieval enables real-time updates and seamless integration with cloud services, minimising the need for manual data downloads and updates. In Saudi Arabia, the Citizen Bank manages citizen data for various ministries through a centralised service bus, highlighting the importance of centralised data management.
Challenges and Importance of Data Management in AI and Cloud Computing
Recently, AI and its dependency on cloud and API-driven systems have been highlighted for quick data classification and categorisation. These insights highlight the need to govern internal Reference and Master Data and establish technical team standards. In addition, defining business terms and managing crosswalks are essential. An example of good governance in practise is a tool called TopBraid EDG by TopQuadrant. It manages taxonomy and Reference data sets. The tool focuses on the complexities of Reference Data Governance, including controlled vocabulary, multi-faceted classifications, and the challenges of data modelling for applications versus enterprise taxonomies.
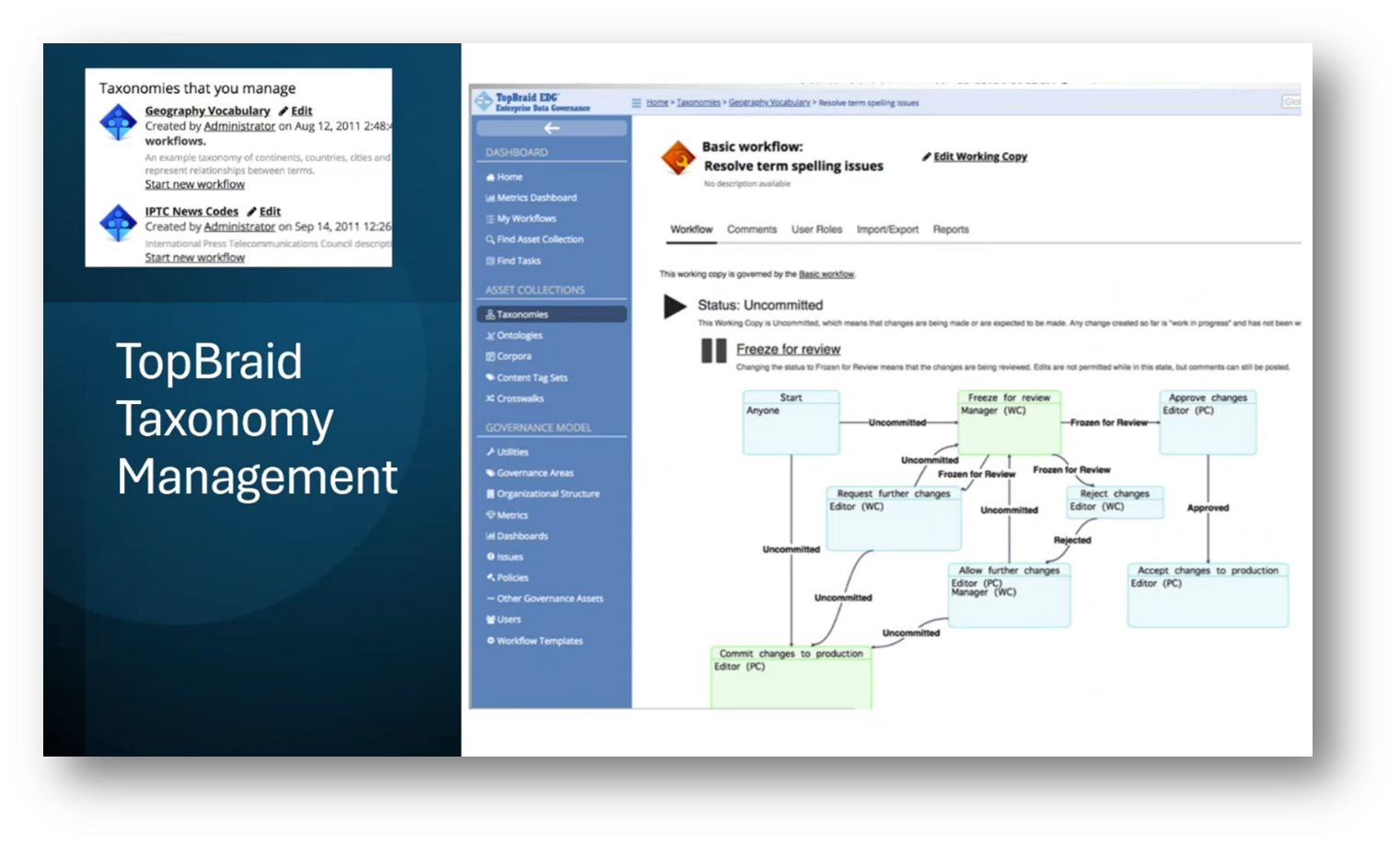
Figure 20 TopBraid Taxonomy Management
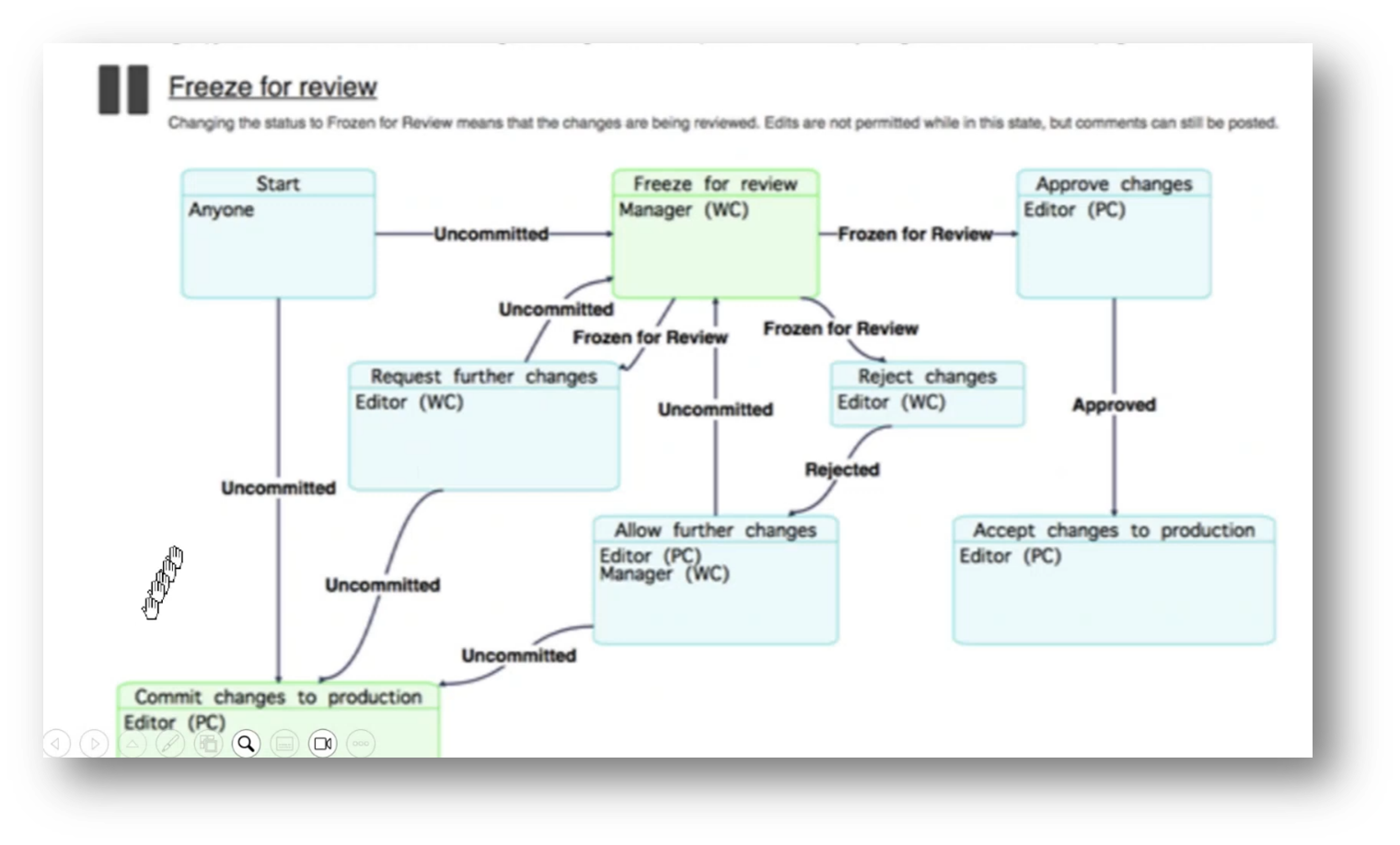
Figure 21 TopBraid Taxonomy Management zoomed in
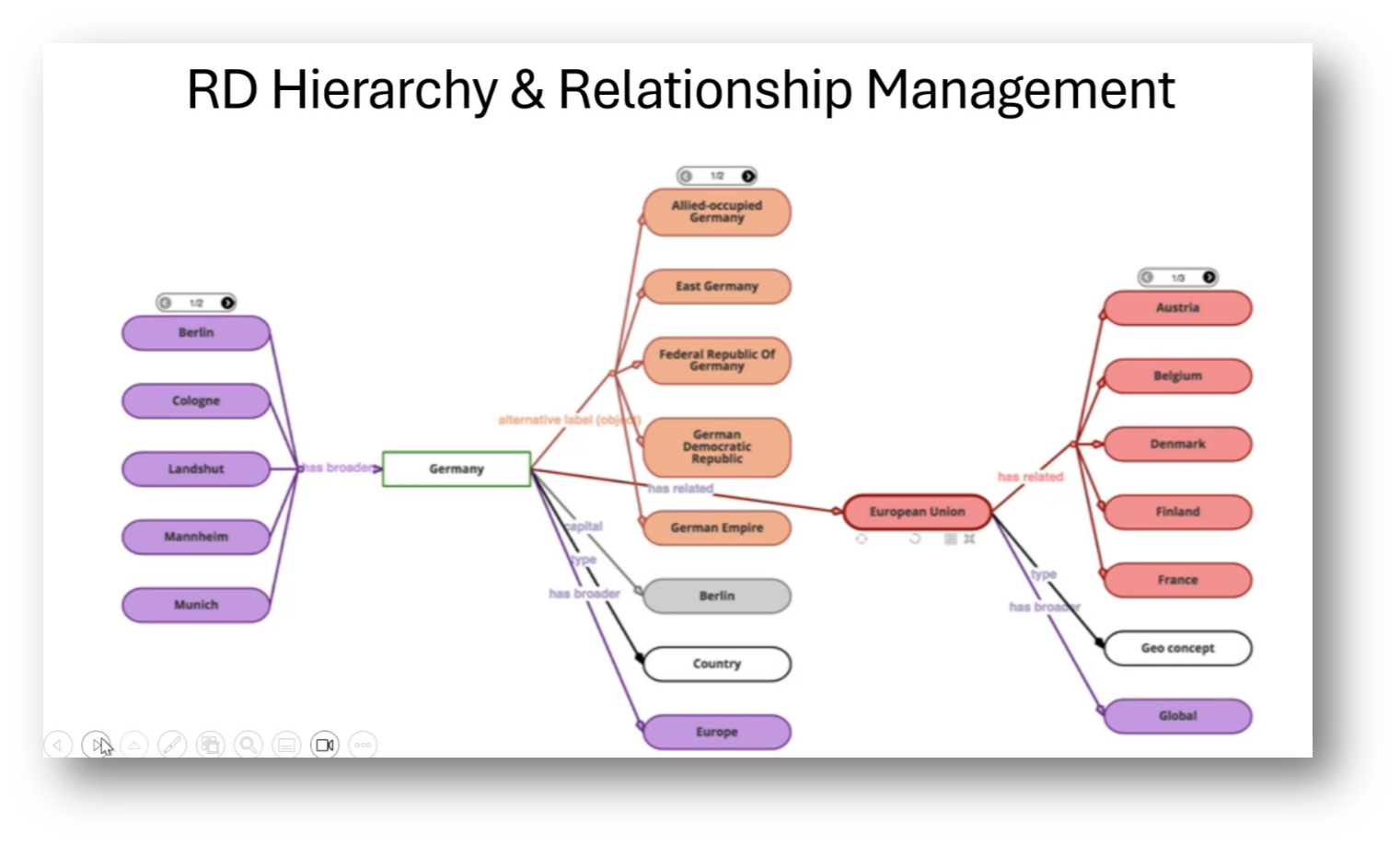
Figure 22 RD Hierarchy and Relationship Management
Importance and Management of Reference Data
Howard focuses on the importance of Reference data in managing Master Data. He highlights the significance of getting the Reference data right before progressing to other areas, emphasising the role of Reference data in categorisation and classification. Additionally, he mentions the process of Reference data publication, stressing the need for API-driven access and the subsequent change management and notification processes.
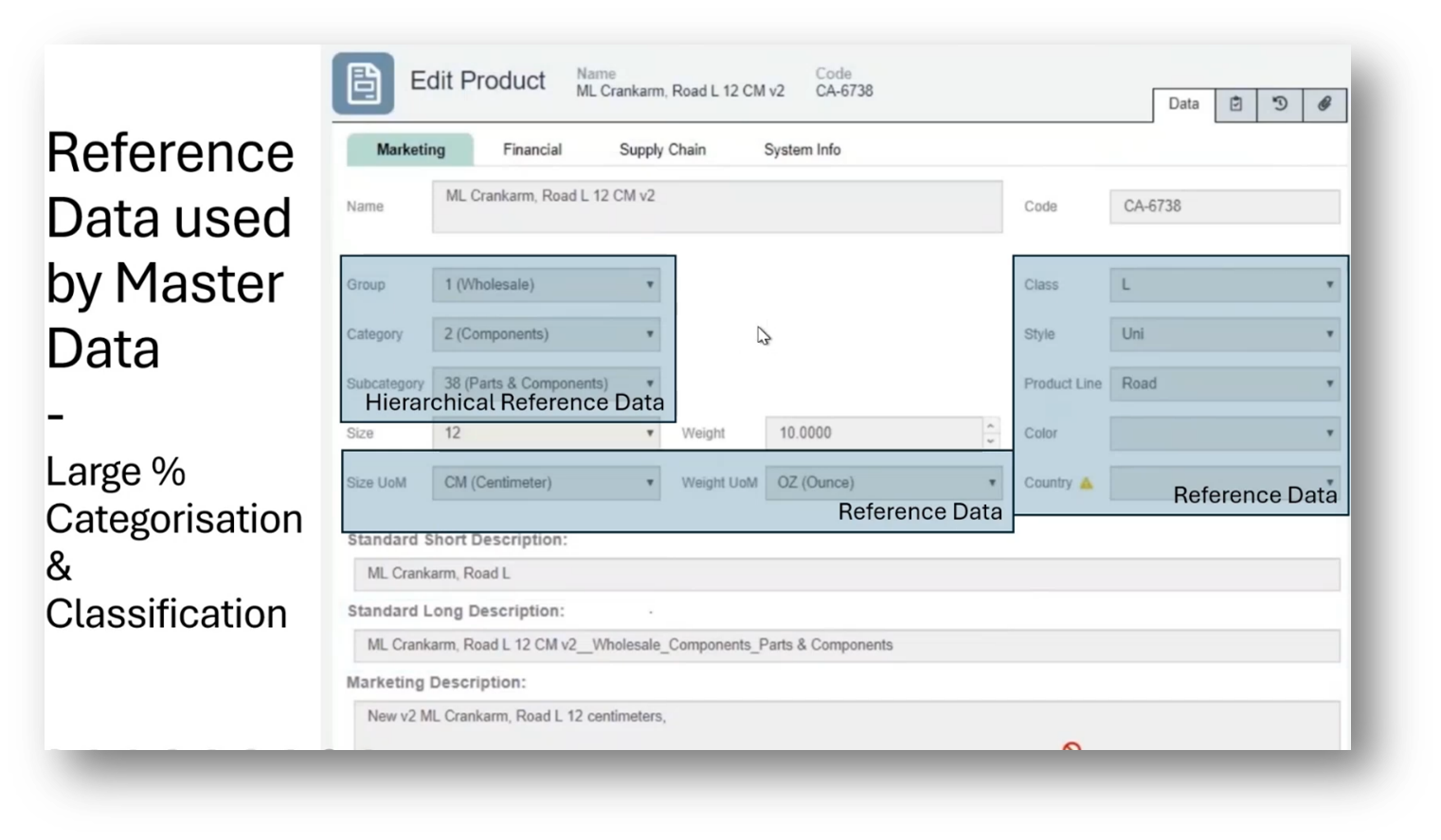
Figure 23 Reference Data used by Master Data
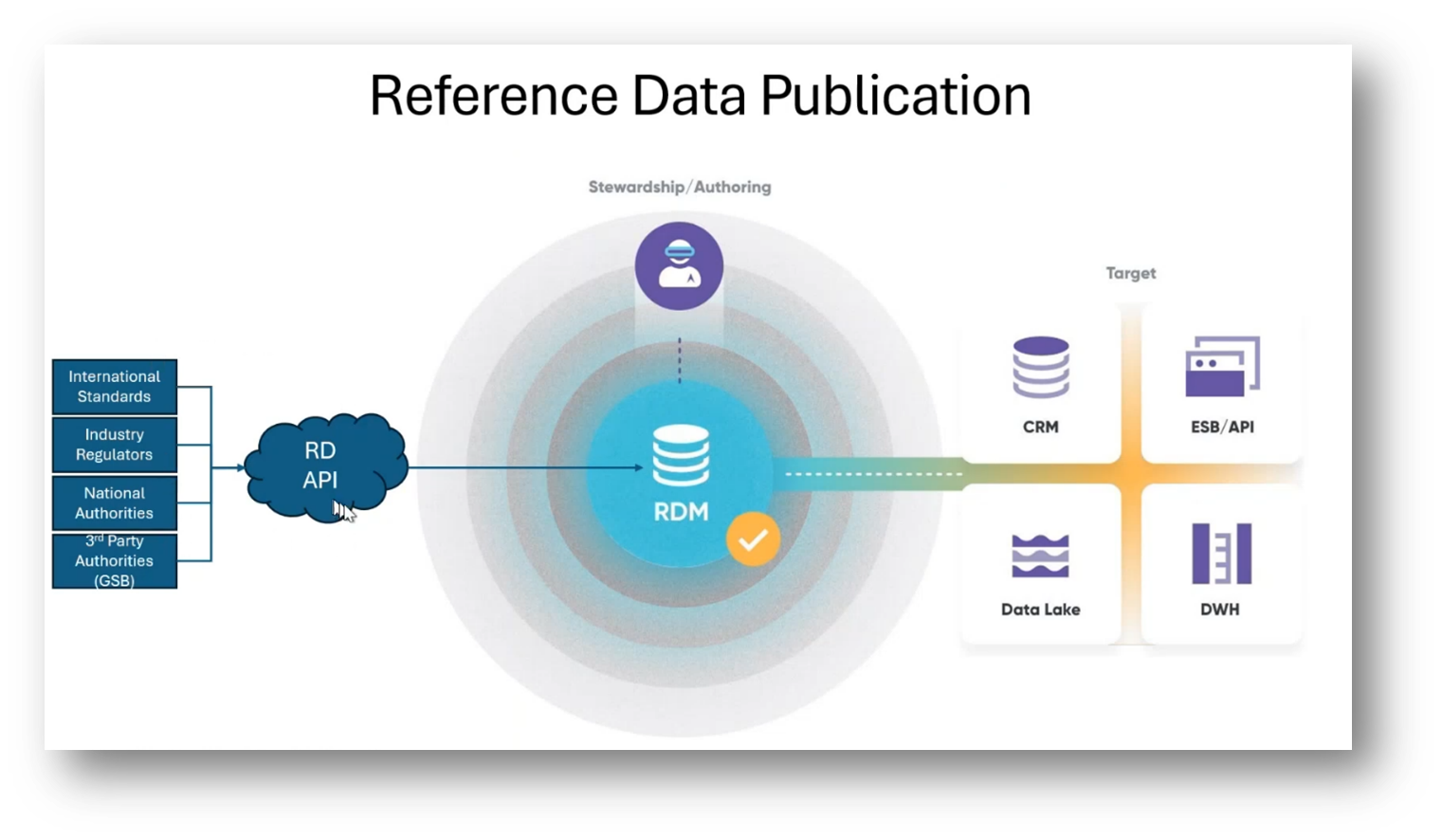
Figure 24 Reference Data Publication
Challenges of Master Data Management
The challenges of cataloguing Reference data standards emphasise the importance of Master Data management and the challenges of cataloguing Reference data standards. These challenges include the complexity of getting Reference data right and the high-level steps of Master Data management, including acquiring and validating data, entity resolution, and data sharing and stewardship. Additionally, Master Data Management processes require understanding the background work involved in day-to-day operations, as well as the benefits and cost drivers. It also involves evaluating different data sources and defining an architectural approach.

Figure 25 High-Level Master Data Management Process
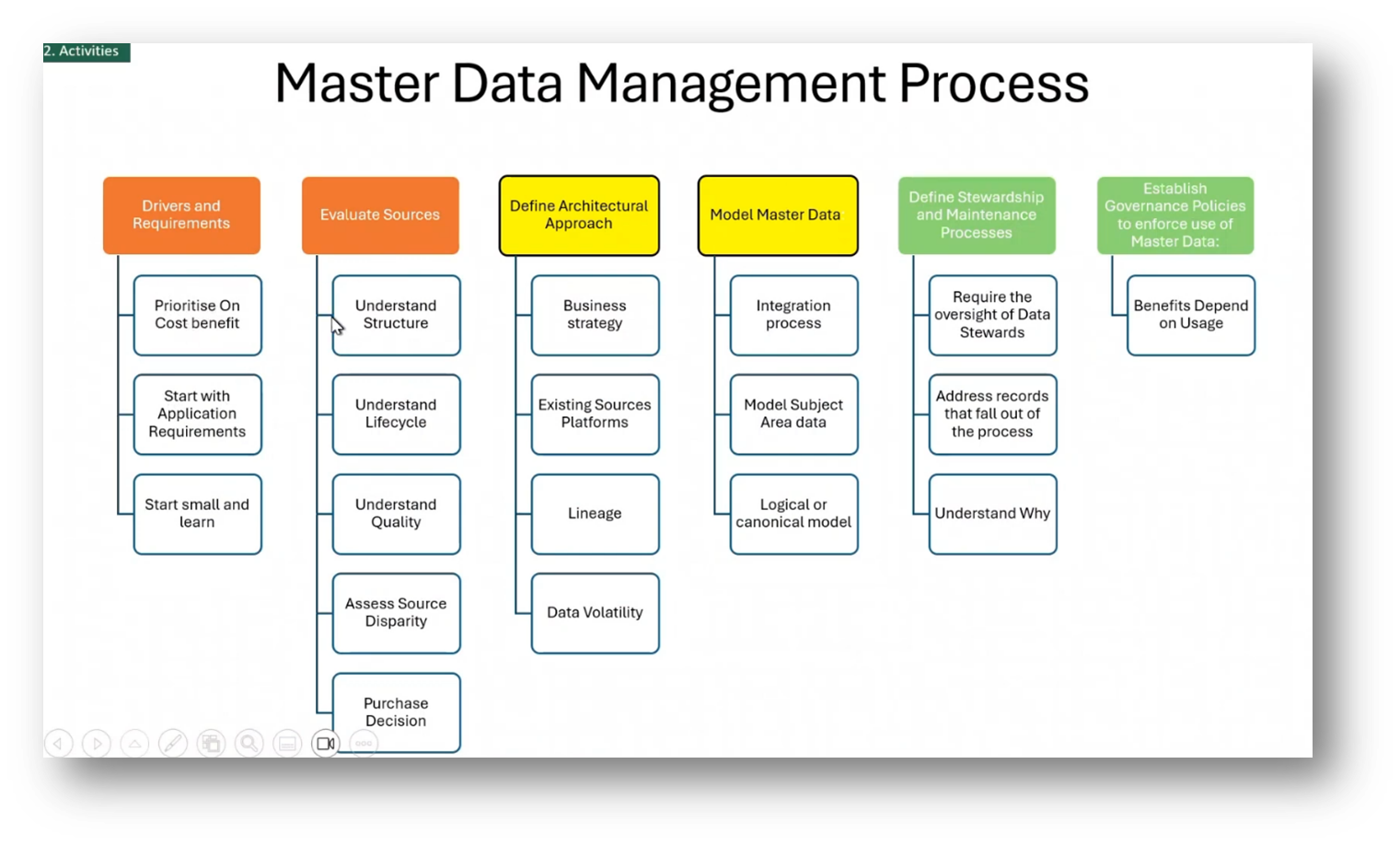
Figure 26 Master Data Management Process
Understanding Data Model Management and Record Acquisition
Data model management and cleansing begins with acquiring data from different sources and identifying similar records based on shared attributes. The next step involves cleaning and standardising the data, including addresses and telephone numbers. After enrichment, a match and merge process is used to identify potential duplicate records, followed by manual intervention if necessary. The goal is to create "golden records" by merging similar data sets. The process also includes resource matching, where different approaches, such as "survival of the fittest" and merging, are used to determine the most accurate and complete data. The original data is also kept and linked together for different perspectives and uses.
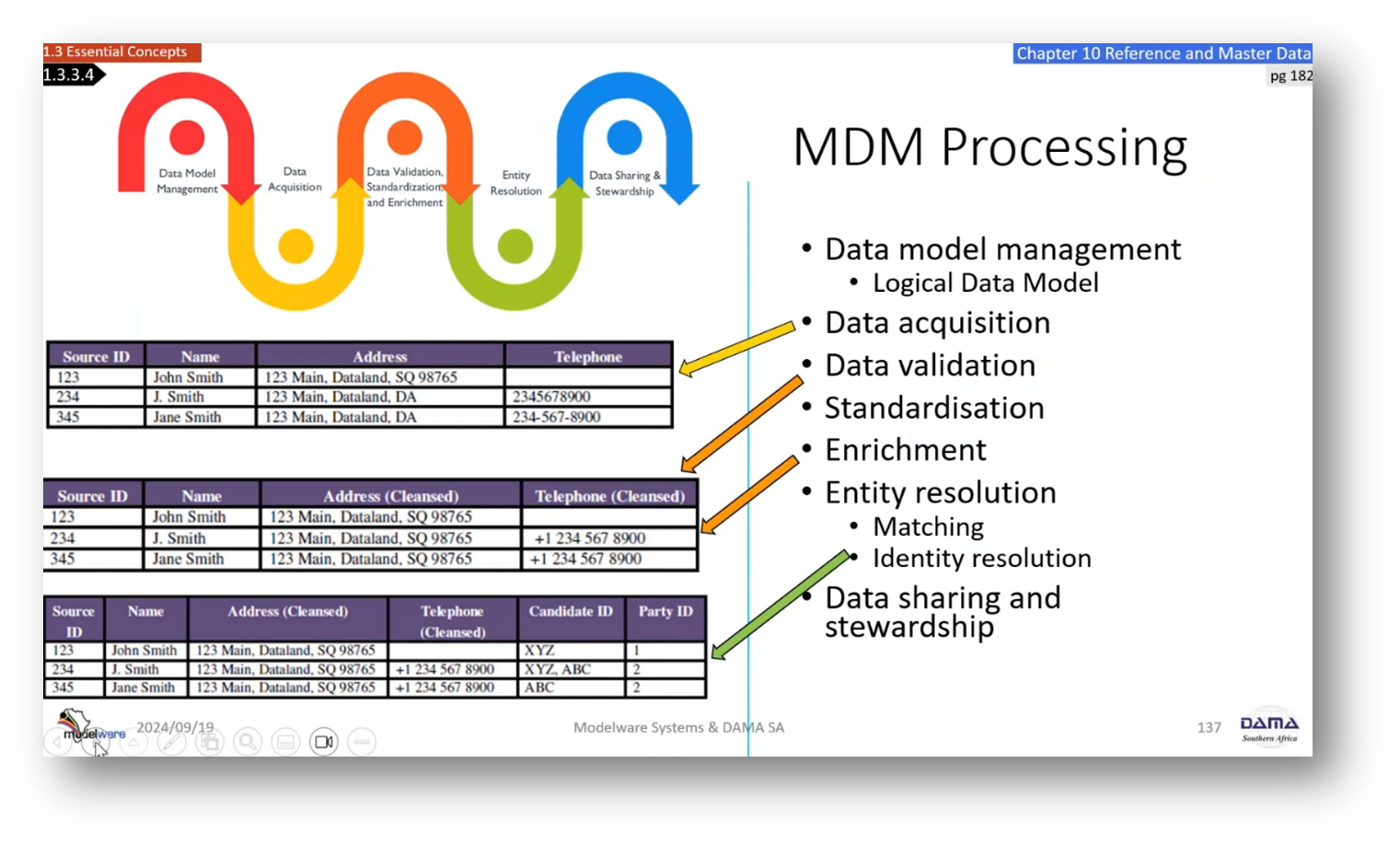
Figure 27 MDM Processing
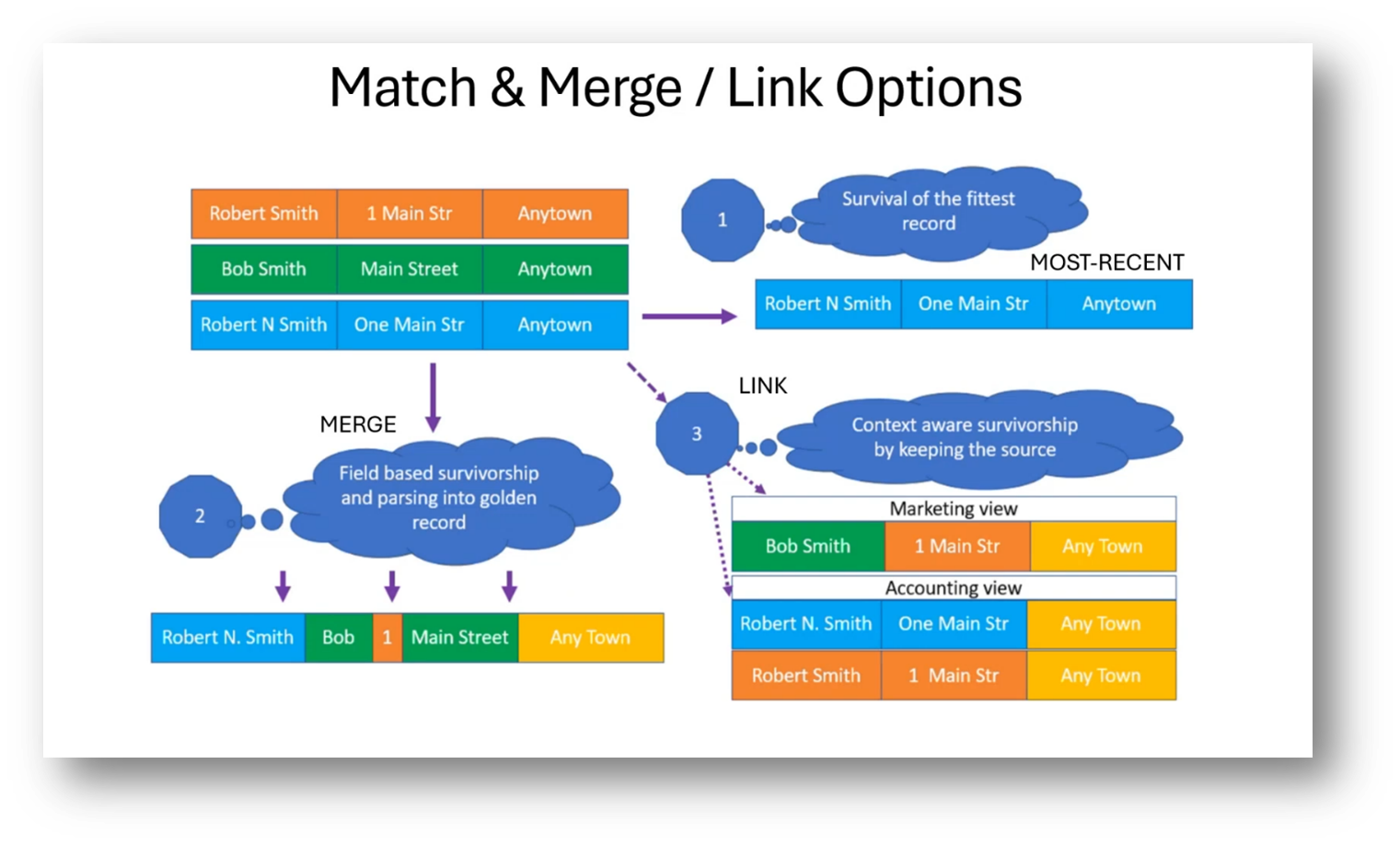
Figure 28 Match and Merge / Link Options
Use of New and Existing Records in Data Management and Compliance
The conversation revolved around the concept of a golden record and the use of existing records in data management. Howard emphasises the importance of maintaining traceability and audit information for compliance and regulatory purposes. He highlights that using existing records could complicate analytics and create potential issues with data accuracy. Additionally, the importance of considering a linking approach for master and Reference data is stressed.
Importance and Selection of Identifiers in Data Assessment
During the assessment of a product, Howard shares that attributes from different sources need to undergo a thorough examination of cardinality, completeness, uniqueness, common values, noise, words, and standardisation. Reltio is recommended to aid in this assessment process, and a report was generated to display the completeness and uniqueness of these attributes. Emphasis was placed on the importance of choosing suitable identifiers, with a discussion around the unsuitability of using customer IDs due to potential discrepancies across systems. Additionally, with the identification of duplicate account numbers led to the consideration alternative elements such as customer name, birth date, gender, and postal address to resolve the issue.
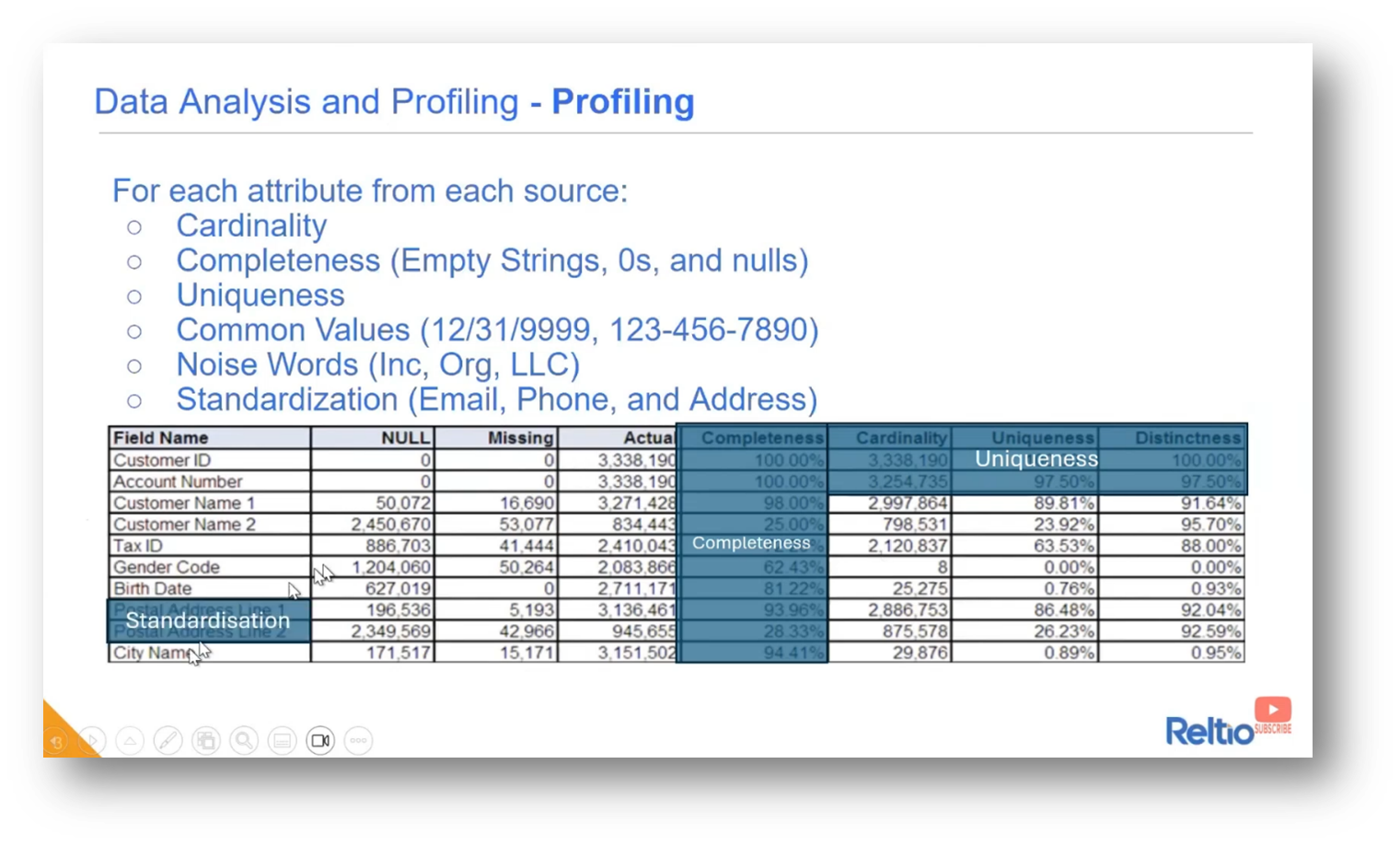
Figure 29 Data Analysis and Profiling - Profiling
Data Modelling and Identifiers
A discussion on the identification and management of data identifiers for data modelling focused on the challenges of finding and utilising identifiers while maintaining data quality and uniqueness. The attendees were encouraged to explore the use of natural keys, business keys, and surrogate keys as potential identifiers, as well as the complexities of matching and managing identifiers over time. Howard then touches on the use of probabilistic matching, machine learning, and statistical matching to enhance identifier accuracy. Additionally, he highlights the ongoing nature of identifier management and the goal of achieving automated matching, acknowledging the complexities and challenges involved in the process. Howard also suggests the allocation of codes for customers with regards to when a customer first visits a website as a method to combat the presence of minimal information.
Understanding and Managing Record Matching in Data Stewardship
The discussion covered the matching logic process, including automatic and suspect matching, data steward involvement, publishing match records, and setting matching logic parameters. The conversation also addressed the need for ongoing maintenance of matching rules and the generation of customer match status reports. Additionally, the group discussed the validation status, dashboard for unmatched customers, and managing potential matches. The meeting concluded with a request for a presentation on merging and using existing records for further training purposes.

Figure 30 What fields should we use as IDENTIFIERS?
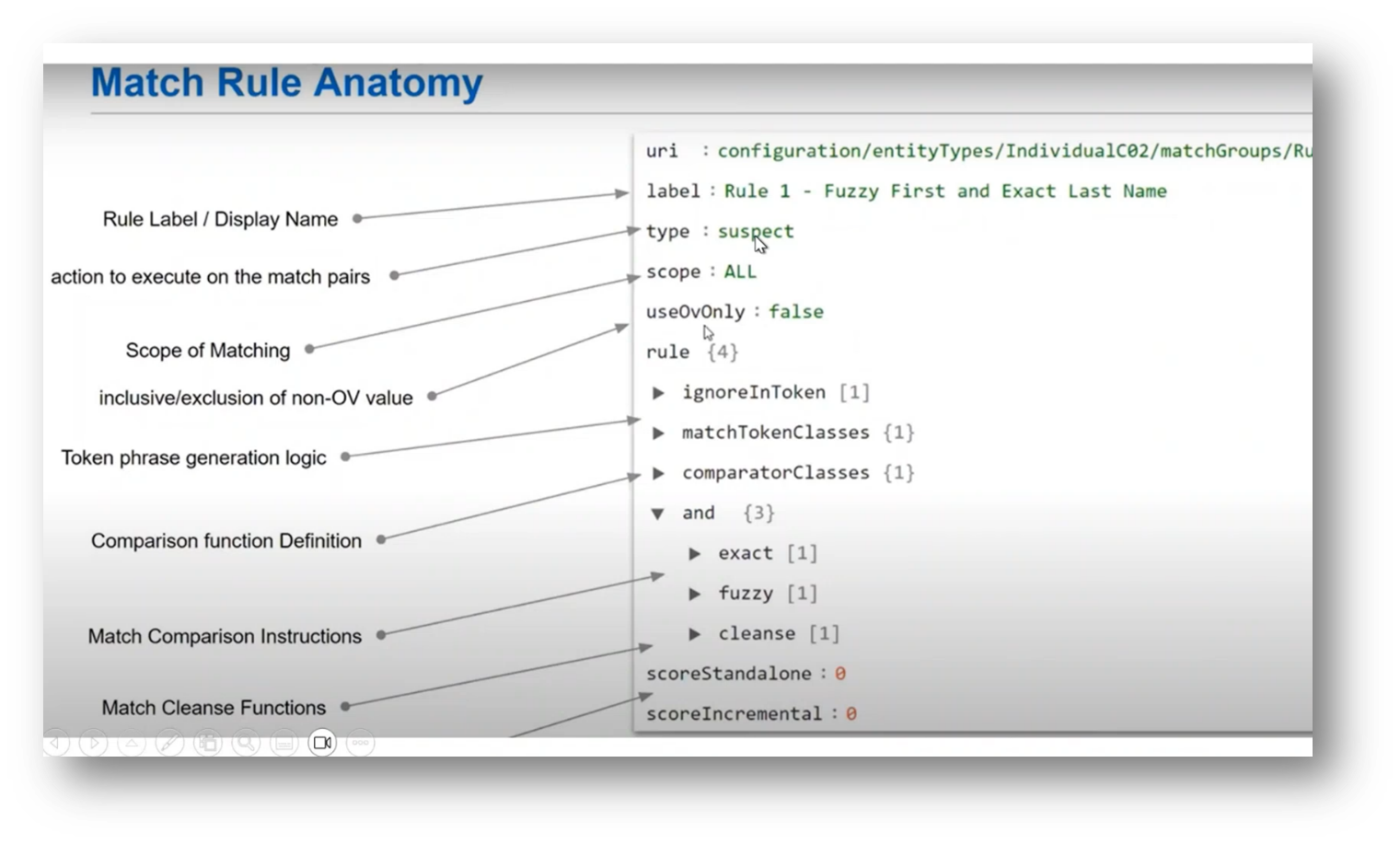
Figure 31 Match Rule Anatomy
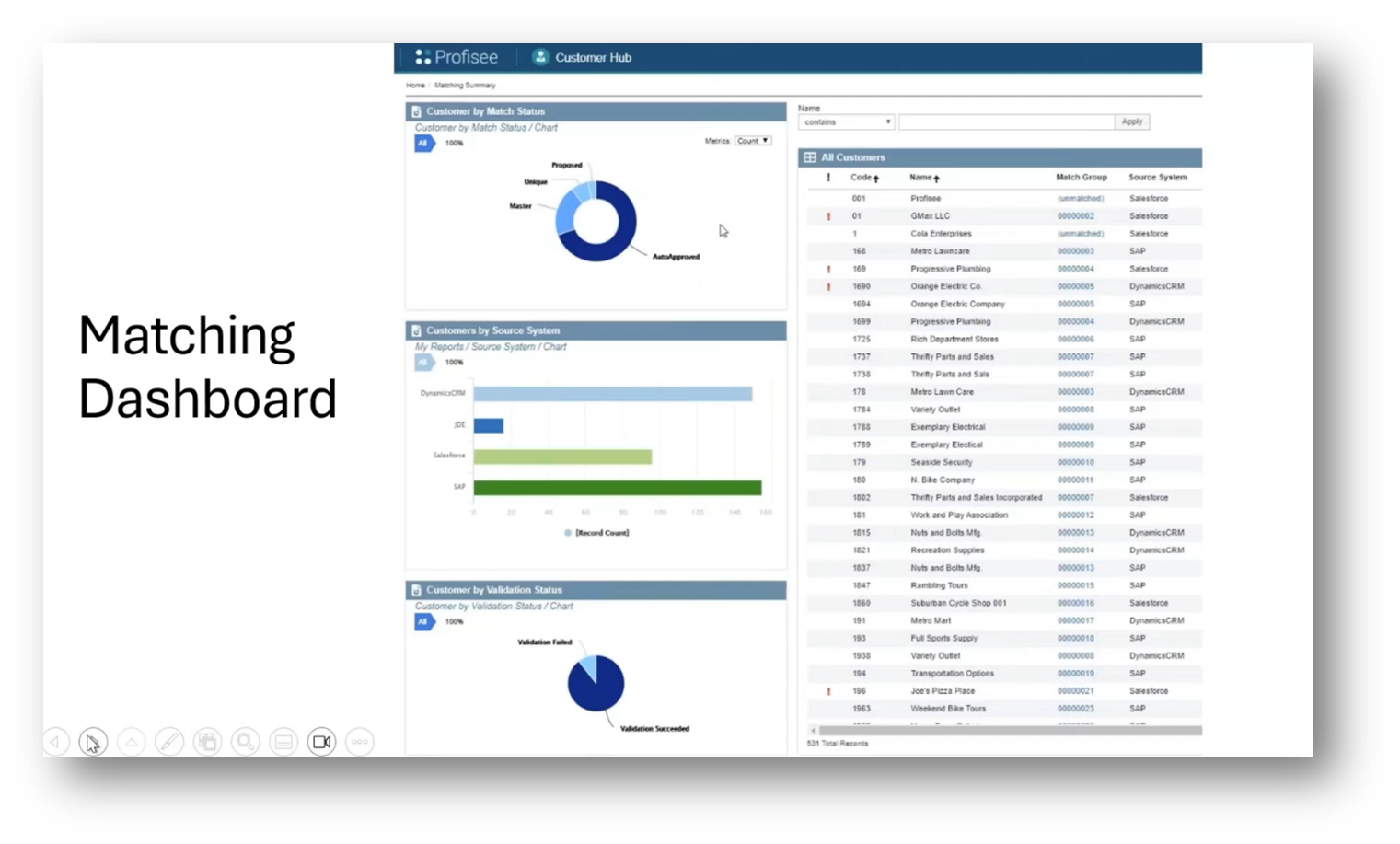
Figure 32 Matching Dashboard

Figure 33 Manage Potential Matches
If you would like to join the discussion, please visit our community platform, the Data Professional Expedition.
Additionally, if you would like to be a guest speaker on a future webinar, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!