
Natural Language Interface to Enterprise Data Management with Dr Ndivhuwo Makondo & Richard Young

Executive Summary
This webinar highlights significant advancements in the integration of artificial intelligence (AI) into enterprise data management, encompassing essential areas such as natural language processing (NLP), deep learning, and the development of text-to-SQL pipelines. Dr Ndivhuwo Makondo addresses the costs associated with foundation model development while emphasising the value of large language models (LLMs) in enhancing data accessibility and management.
Richard Young discusses the critical challenges faced in creating effective text-to-SQL systems, such as data generation, query execution, and the role of domain experts in ensuring data quality and governance. Additionally, the webinar explores potential improvements and strategies for optimising database pipelines, culminating in an overview of the future landscape of AI-driven data management in relational database environments.
Webinar Details
Title: Natural Language Interface to Enterprise Data Management with Dr Ndivhuwo Makondo & Richard Young
Date: 14/04/2025
Presenter: Dr Ndivhuwo Makondo & Richard Young
Meetup Group: DAMA SA Big Data
Write-up Author: Howard Diesel
Contents
Natural Language Interface to Enterprise Data Management
An Overview of the Major Advancements in Artificial Intelligence
Analysing the Costs in the Foundation Model Development
Application of AI Models for Enterprise
Value of LLMs for Enterprise Data Management
Natural Language Processing for SQL Queries
Deep Learning Models and Their Applications in Database Management
Challenges of Text-to-SQL Pipelines
Data Generation and Synthetic SQL Queries for Different Use Cases
Demonstration of a Research Project's Pipeline Capabilities
Database User Interface and Query Execution
Data Storage and Reinforcement Learning in AI Systems
Potential Improvements of a Query Generation System
Understanding the Components of a Text-to-SQL Pipeline
Script Generation and Database Management in AI
Developing a Text-to-SQL Pipeline
Optimising Database Pipelines for Use Cases
Data Management and Semantic Challenges in Natural Language Processing
Role of Domain Experts in Data Management
Data Management and Quality in the Context of Migration and Governance
Text to SQL Pipelines and Challenges in AI Research
Challenges and Strategies in Creating a Minimal Viable Product
Future of Data Management and AI in Relational Databases
Natural Language Interface to Enterprise Data Management
Howard Diesel opens the webinar and introduces Dr Ndivhuwo Makondo. Nidivhuwo encourages an interactive format. A question was asked about the establishment of IBM Research in South Africa, which Nidivhuwo confirmed to have begun over ten years ago, with significant contributions from both the Johannesburg and Kenya labs.
IBM Research Africa is a prominent research hub located in Johannesburg's Johnny Spec Lab, part of a globally distributed network of one of the largest and oldest industrial research labs. Led by a research manager and supported by senior research engineers like Richard Young, the team focuses on integrating advanced AI capabilities into IBM platforms and products, with an emphasis on developing major language interfaces for enterprise data management. The lab balances its global mission of fueling IBM's growth and advancing computing with local partnerships to create meaningful impacts across Africa.

Figure 1 Natural Language Interface to Enterprise Data Management
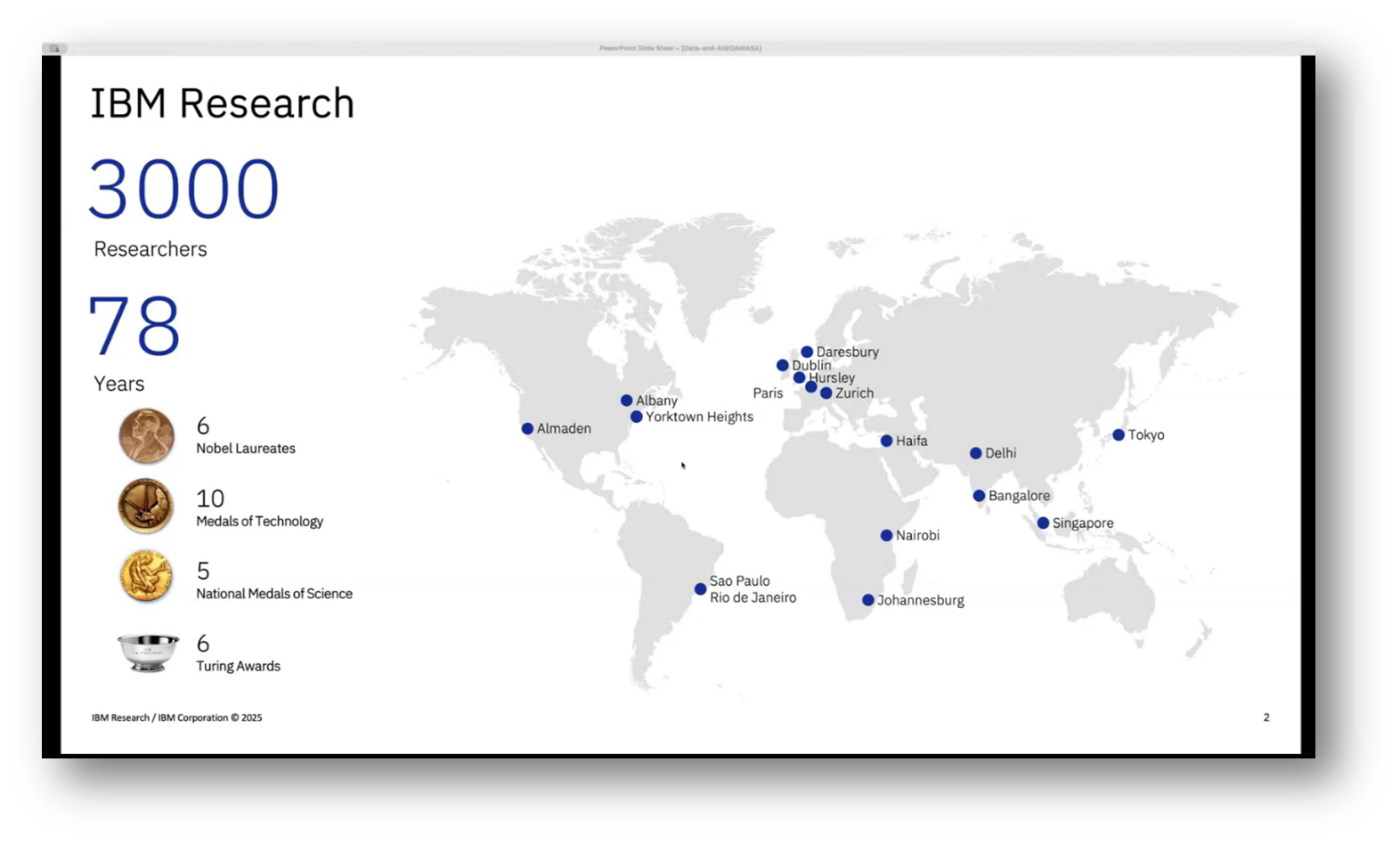
Figure 2 IBM Research
An Overview of the Major Advancements in Artificial Intelligence
Artificial Intelligence (AI) can be understood as the science of designing intelligent machines, with its history marked by four major advancements. The first era focused on encoding human expert knowledge into systems using handcrafted symbolic rules, which created a bottleneck due to the reliance on manual input. This led to the emergence of machine learning, where models based on data rather than explicitly coded rules were developed. However, domain knowledge still played a role in model design and evaluation.
The third advancement benefited from the availability of vast amounts of labelled data and improved computational capabilities, allowing for more automated learning of task-specific representations, while still requiring domain expertise in architecture and metrics. Recently, the rise of foundation models has revolutionised the landscape, enabling pre-training on large volumes of unlabeled data through self-supervised learning, which facilitates generalisation across tasks and reduces the need for extensive labelled datasets. This shift allows organisations to leverage these pre-trained models, customising them for specific use cases more easily and efficiently.
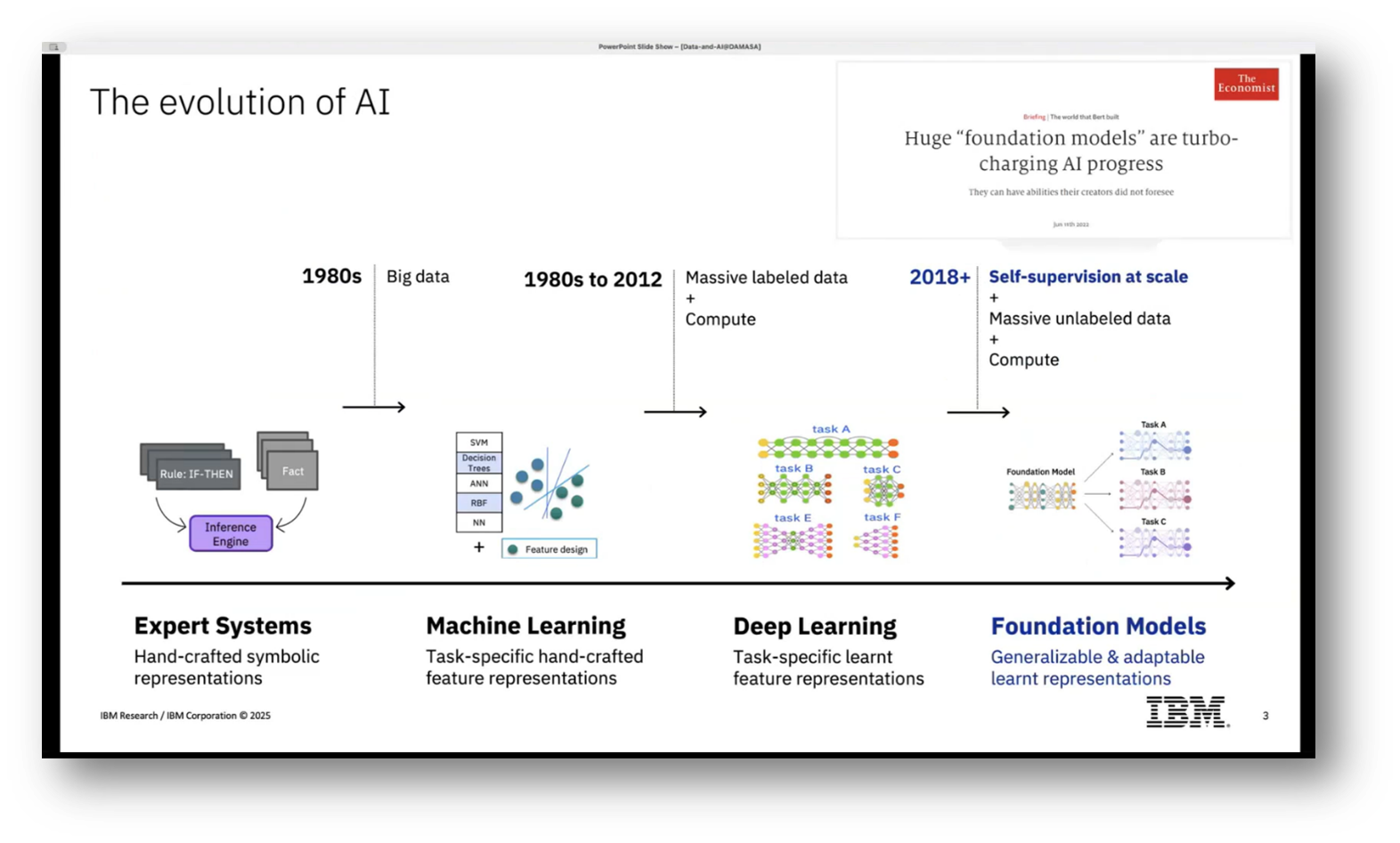
Figure 3 The Evolution of AI
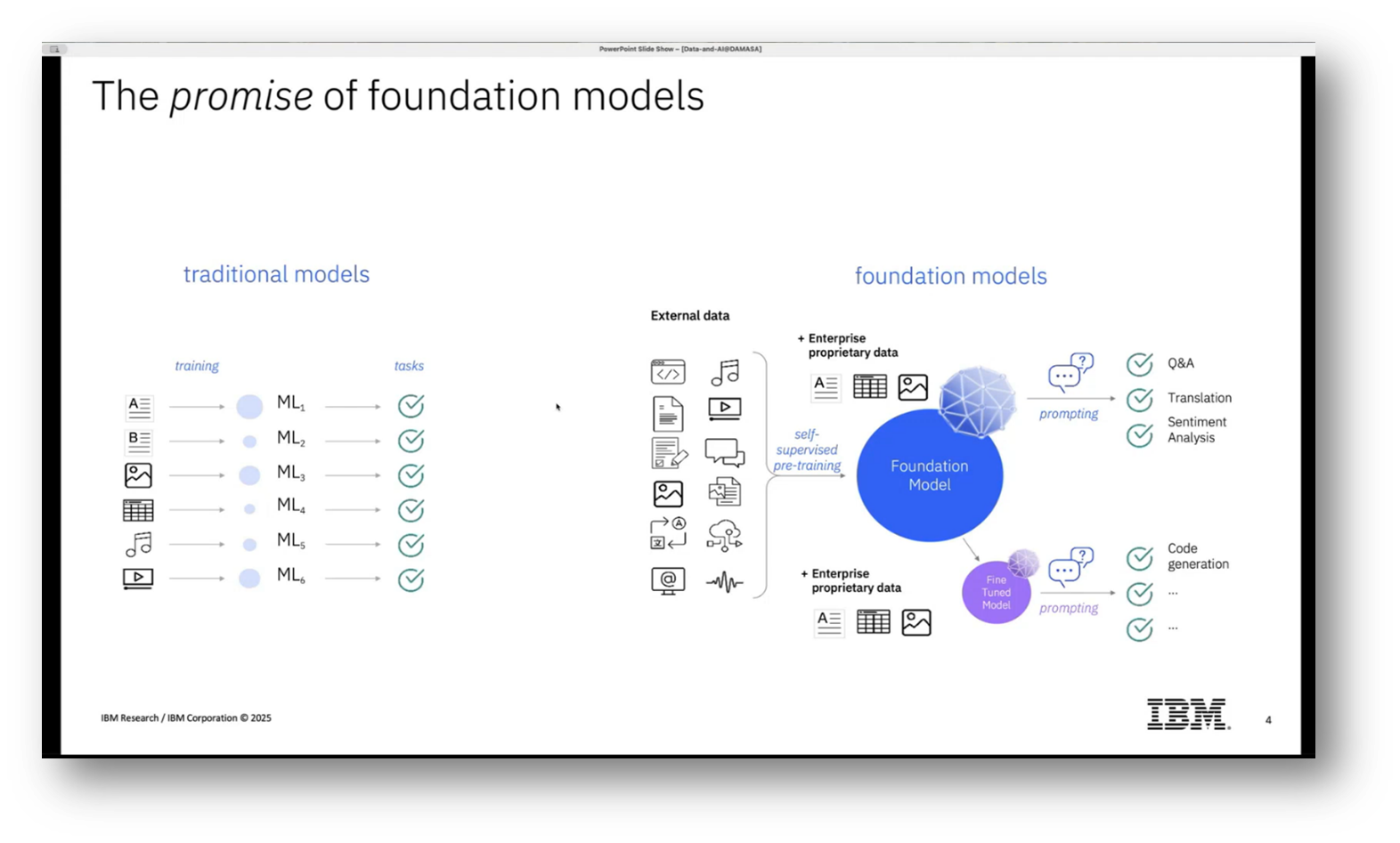
Figure 4 The Promise of Foundation Models
Analysing the Costs in the Foundation Model Development
The foundation model journey can be viewed through two key roles: the foundation model provider and the user. The provider is responsible for training models, which necessitates significant investments in data, computational resources, and expertise. In contrast, users can leverage these pre-trained models through various phases, including fine-tuning with available labelled data, prompt engineering using minimal examples, and post-processing to tailor outputs for specific applications. While the provider's role entails higher costs, complexity, and greater control over model development, users benefit from reduced costs and investments while relying on externally provided models.
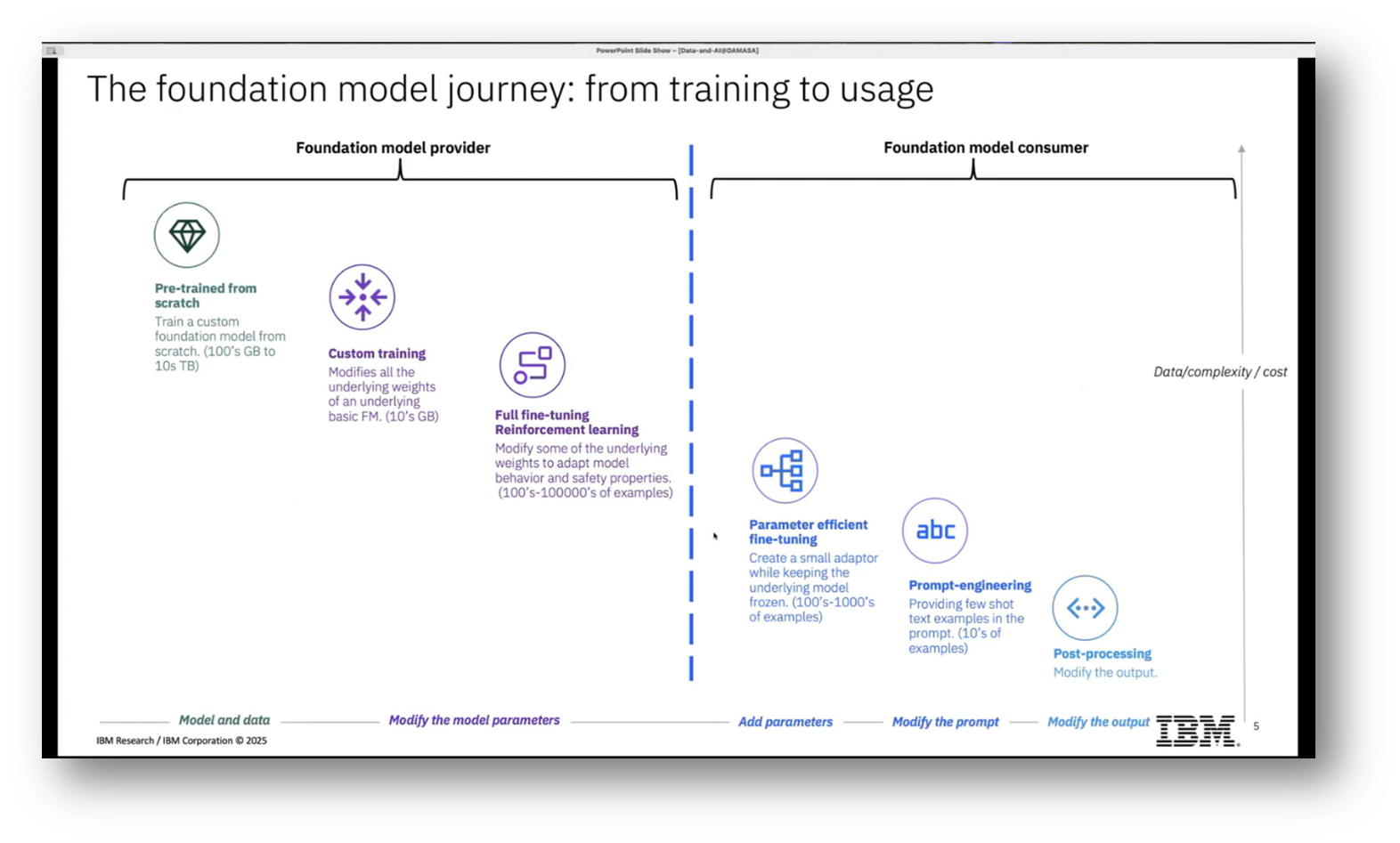
Figure 5 The Foundational Model Journey
Application of AI Models for Enterprise
IBM's perspective on foundation models and generative AI for enterprise emphasises the importance of developing models transparently and responsibly, leveraging open technologies. All base models are accessible in their development phase for further use and improvement, accompanied by published data curation and governance processes.
Recognising that a single large model cannot meet all business needs, IBM’s. Focus is on creating specialised, efficient, and affordable models tailored to specific business domains, including text-to-SQL translation and code generation across languages like Java and COBOL.’ Their offerings also encompass diverse applications, including time series analysis and climate modelling, ensuring the continual development of targeted solutions.
Nidivhuwo shares on IBM's efforts to develop foundation models for energy optimisation and the potential for expanding support for low-resource languages, particularly in Africa. While IBM is not currently engaged in specific projects for African languages like Swahili, Luo, or Yoruba, they are exploring partnerships through the AI Alliance, which was co-founded with Meta to foster open AI development and collaborate on important applications.
There is notable work being done by organisations like CSIR and grassroots initiatives such as Masakani to address language translation and NLP research in Africa. However, before developing models, significant challenges remain, particularly in data collection and availability for various languages, especially less-represented ones like Venda. All research efforts contribute to IBM's data and AI platform, enhancing its R&D capabilities.

Figure 6 Granite: A family of open LLMs released by IBM
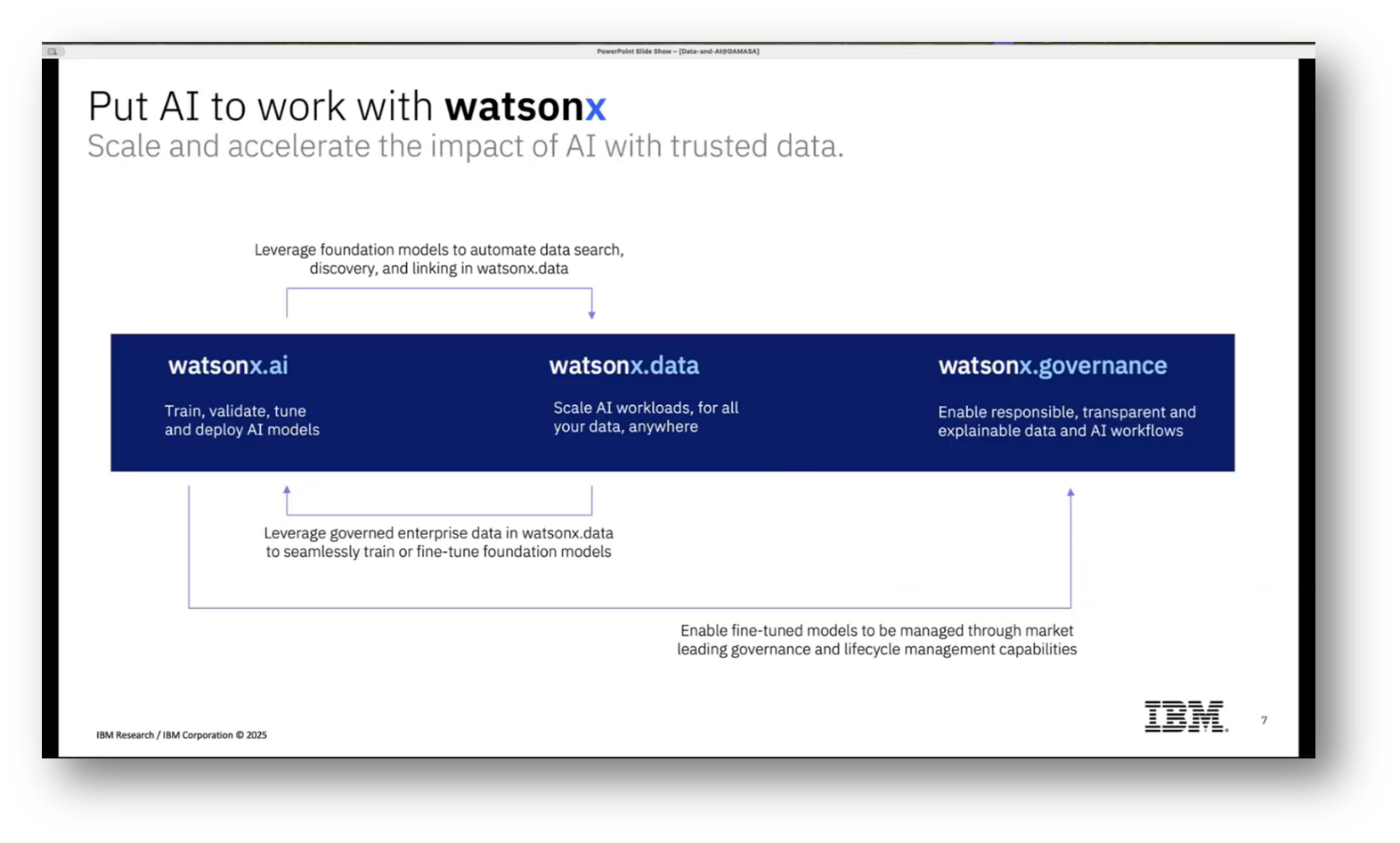
Figure 7 "Put AI to work wasonx"
Value of LLMs for Enterprise Data Management
The research focuses on leveraging large language models (LLMs) for enterprise data management, specifically by developing a natural language interface for SQL databases. This technology aims to accelerate insights from structured data by providing easier access, allowing users without SQL knowledge to query databases independently, thereby improving productivity. Data engineers can benefit as well by using the system as a coding assistant to prototype and refine data pipelines efficiently, even when faced with various SQL dialects.
A key scientific challenge lies in translating natural language inquiries into SQL queries. Additionally, the management and governance of these models are crucial, particularly regarding data curation and adapting to changes like data drift and evolving language usage, which are supported by the Watson X platform that ensures compliance with data governance policies.
Figure 8 "LLMs for Enterprise Data Management"
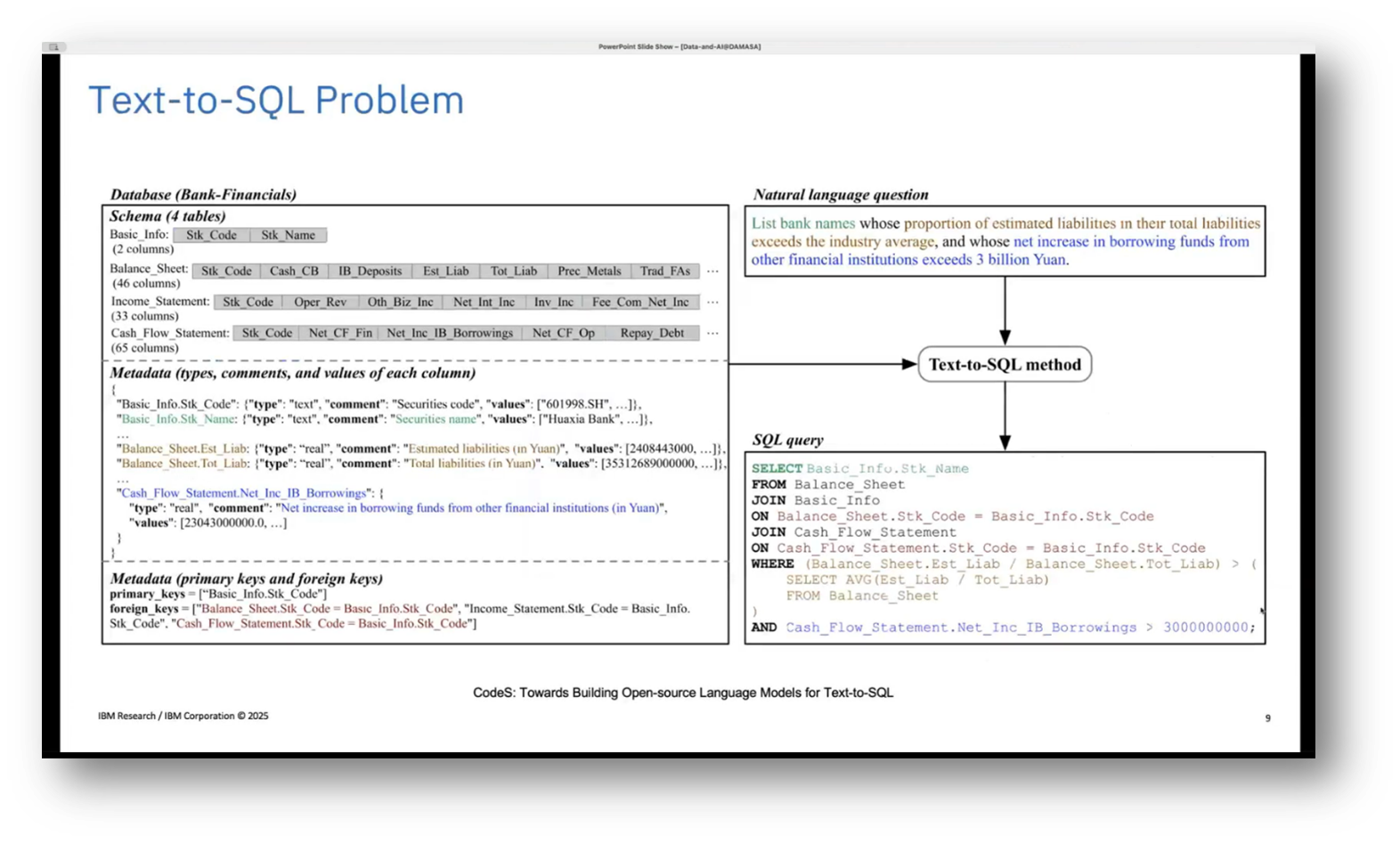
Figure 9 Text-to-SQL Problem
Natural Language Processing for SQL Queries
The problem of converting natural language queries into SQL involves leveraging language models to accurately extract user intent, comprising SQL keywords, schema details, tables, columns, and values. This task poses challenges on both the natural language front—due to variations in language use, jargon, context, and inherent ambiguity—and on the SQL side, where differences in database dialects (like IBM DB2, PostgreSQL, and MySQL) and the complexity of queries (often involving numerous joins and conditions) create difficulties.
Nidivhuwo mentions concerns about managing large databases with extensive rows and columns, fitting relevant schema information into language model prompts, and understanding domain-specific jargon, such as cryptic schema names. While pre-trained models may struggle with specialised terminologies, having natural language descriptions of the schema can aid in query generation; efforts to enrich schemas with these descriptions can enhance the overall process.
Deep Learning Models and Their Applications in Database Management
In the exploration of approaches for testing SQL generation, various methodologies are noted in the literature, particularly those involving sequence-to-sequence and encoder-decoder models, with a shift towards transformer-based architectures. Traditional deep learning models necessitate annotated data specific to each database, which can hinder flexibility. In contrast, recent advancements utilise pre-trained large language models that capture linguistic patterns, allowing them to adapt effectively to different databases.
Two primary strategies emerge: one involves leveraging a large model like ChatGPT for in-context learning, utilising database prompts and example queries to facilitate SQL generation; the other employs smaller, on-premises models that require fine-tuning with synthetic data tailored to specific databases before applying in-context learning to assess performance in SQL query prediction.
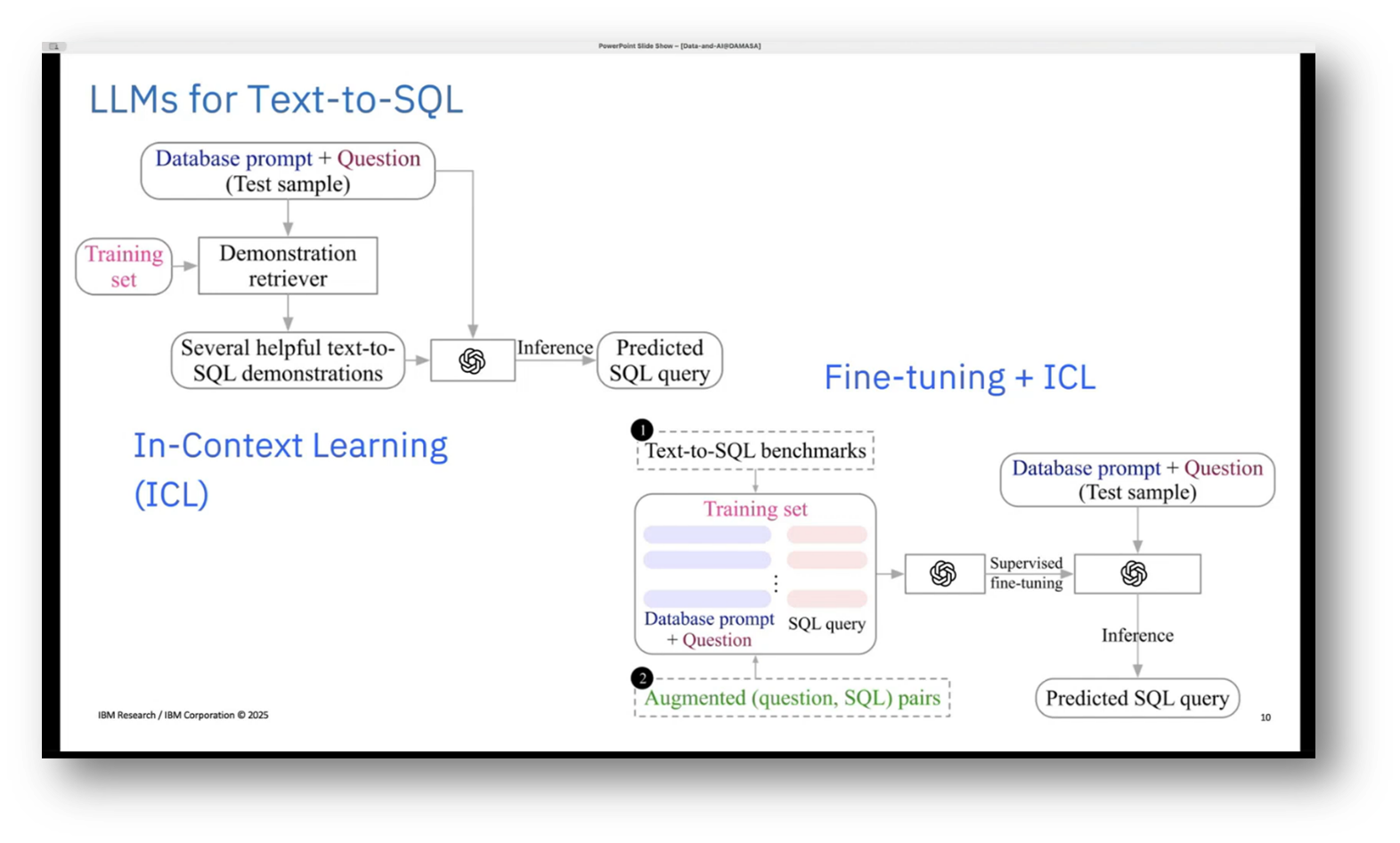
Figure 10 LLMs for Text-to-SQL
Challenges of Text-to-SQL Pipelines
Recent advancements in academic benchmarks have led to the development of a text-to-SQL pipeline, notably using pre-trained large language models, including those based on GPT technology. IBM's submission, utilising a smaller model, remarkably achieved a top ranking for several weeks and currently remains within the top five.
This innovative pipeline allows users to interact with their databases by generating and validating SQL queries, even on smaller models, which is particularly advantageous given the typical reliance on external APIs from companies like OpenAI and Google. The pipeline features reconfigurable components that facilitate feature generation, code generation, and execution feedback, enhancing the overall user experience in querying data.
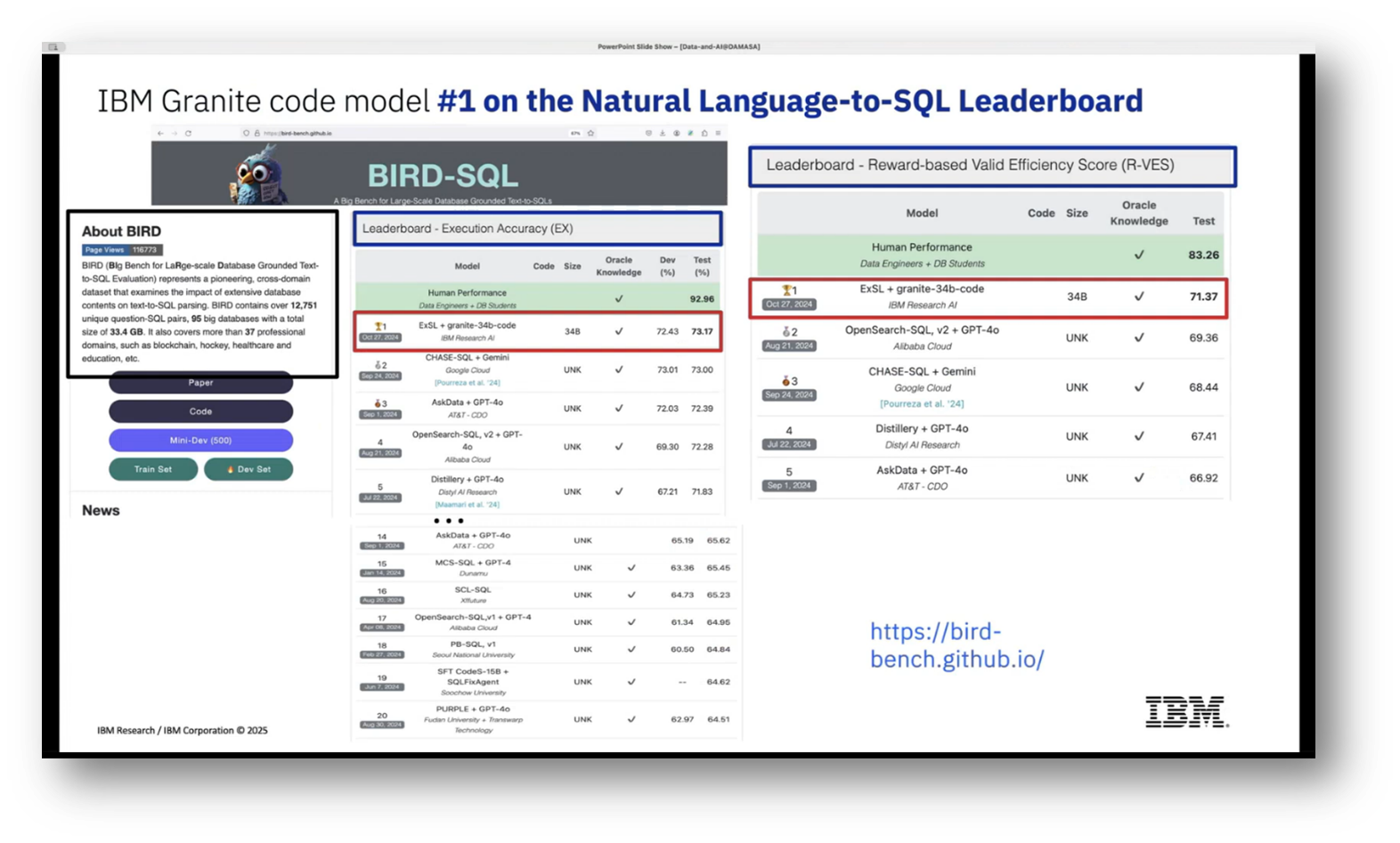
Figure 11 IBM Granite Code Model
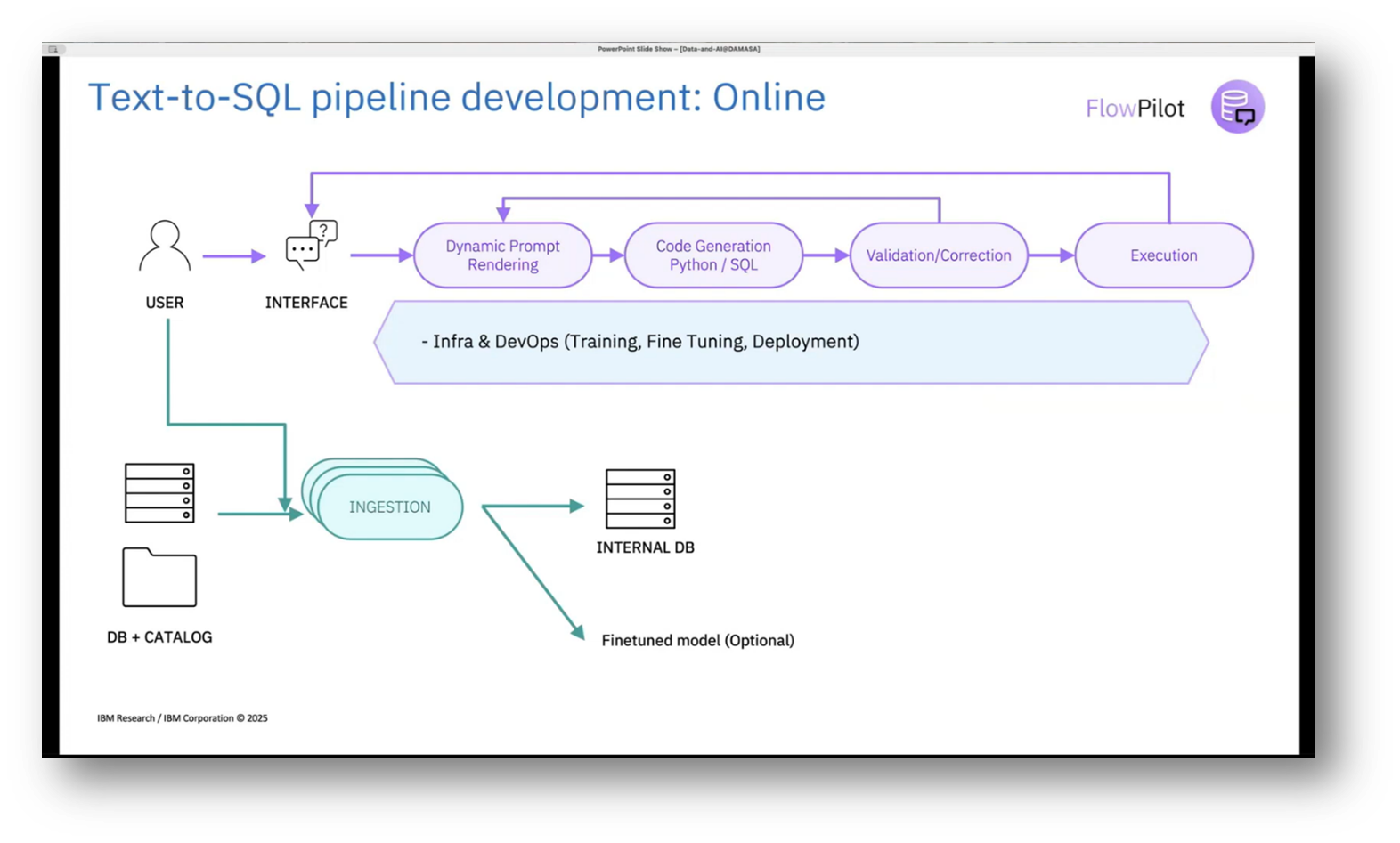
Figure 12 Text-to-SQL Pipeline Development: Online
Data Generation and Synthetic SQL Queries for Different Use Cases
The development of data generation tools for various use cases is underway, focusing on the ability to create synthetic data from database schemas, particularly when users provide limited input. This includes generating synthetic SQL queries that can be executed against the schema, alongside corresponding natural language queries. Additionally, leveraging query logs, synthetic utterances can be created for model fine-tuning.
While some clients may provide annotated examples, the challenge lies in validating the quality and diversity of the synthetic data generated. Current efforts also involve integrating text SQL capabilities into various IBM platforms, aimed at enhancing self-service, conversational access to structured data for non-technical users. This technology is also expanding into IBM's asset management platforms, utilising data collected via IoT sensors for tasks like alarm interpretation and fault analysis through a chat interface.
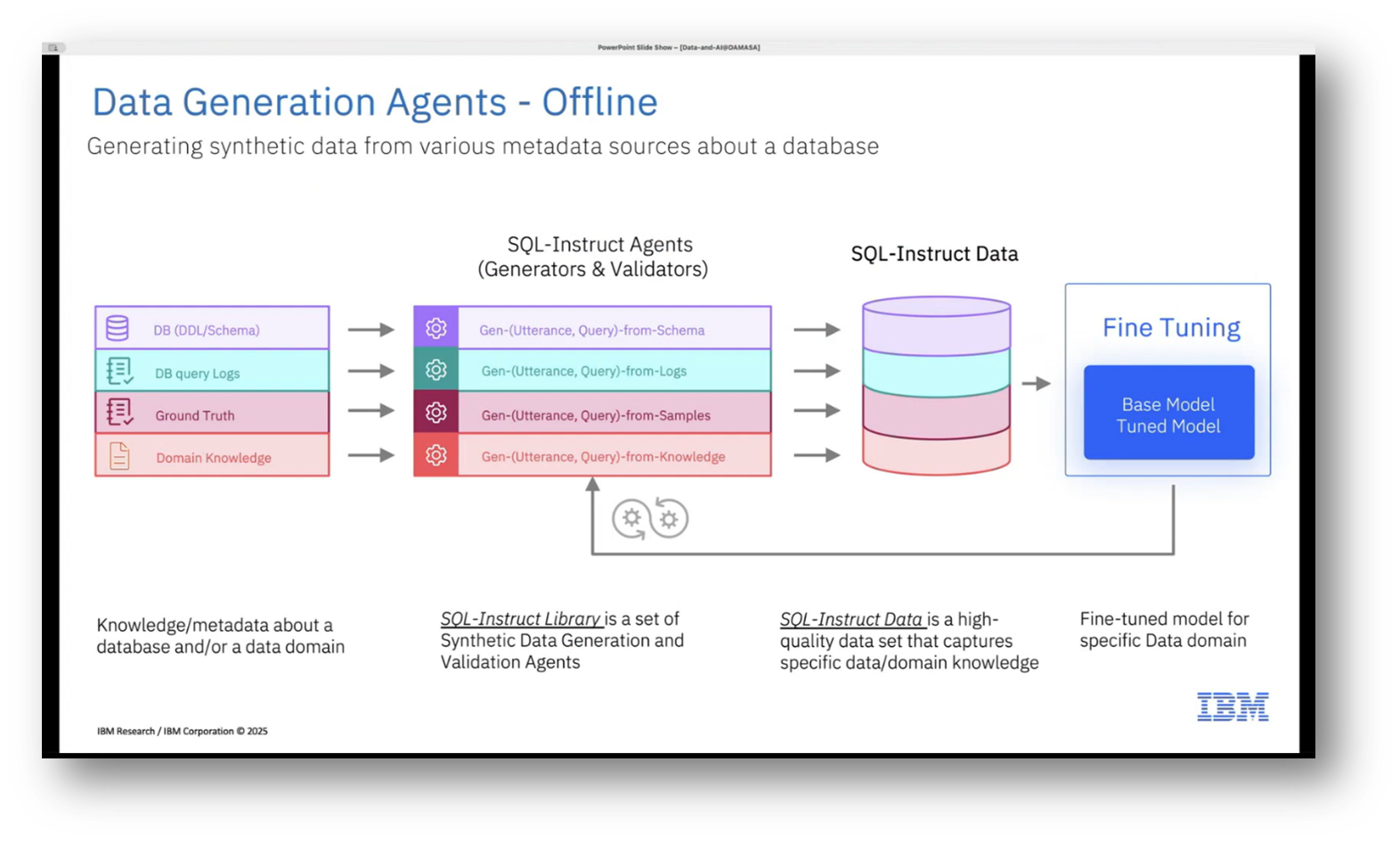
Figure 13 Data Generation Agents - Offline
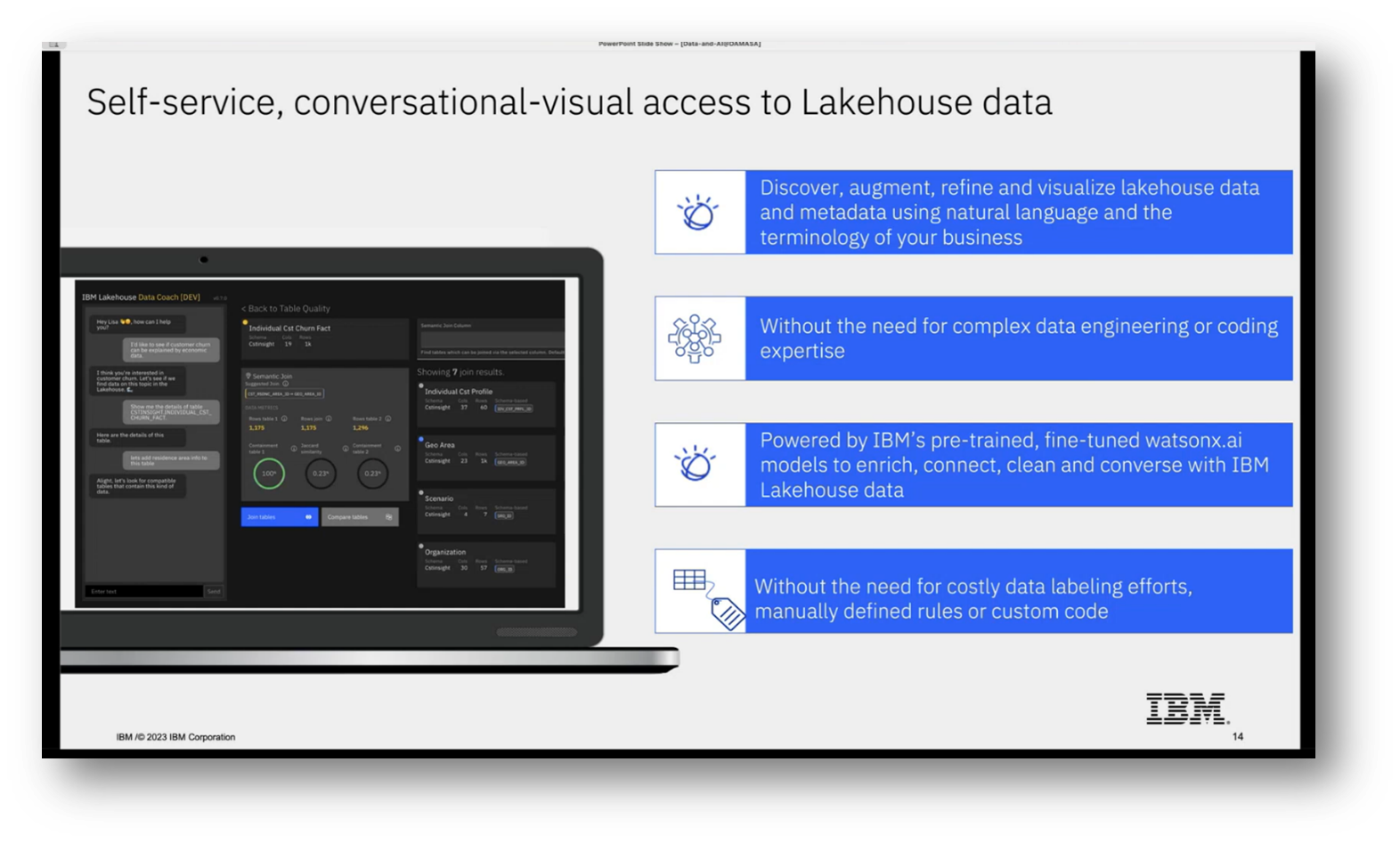
Figure 14 "Self-service, conversational-visual access to Lakehouse data"
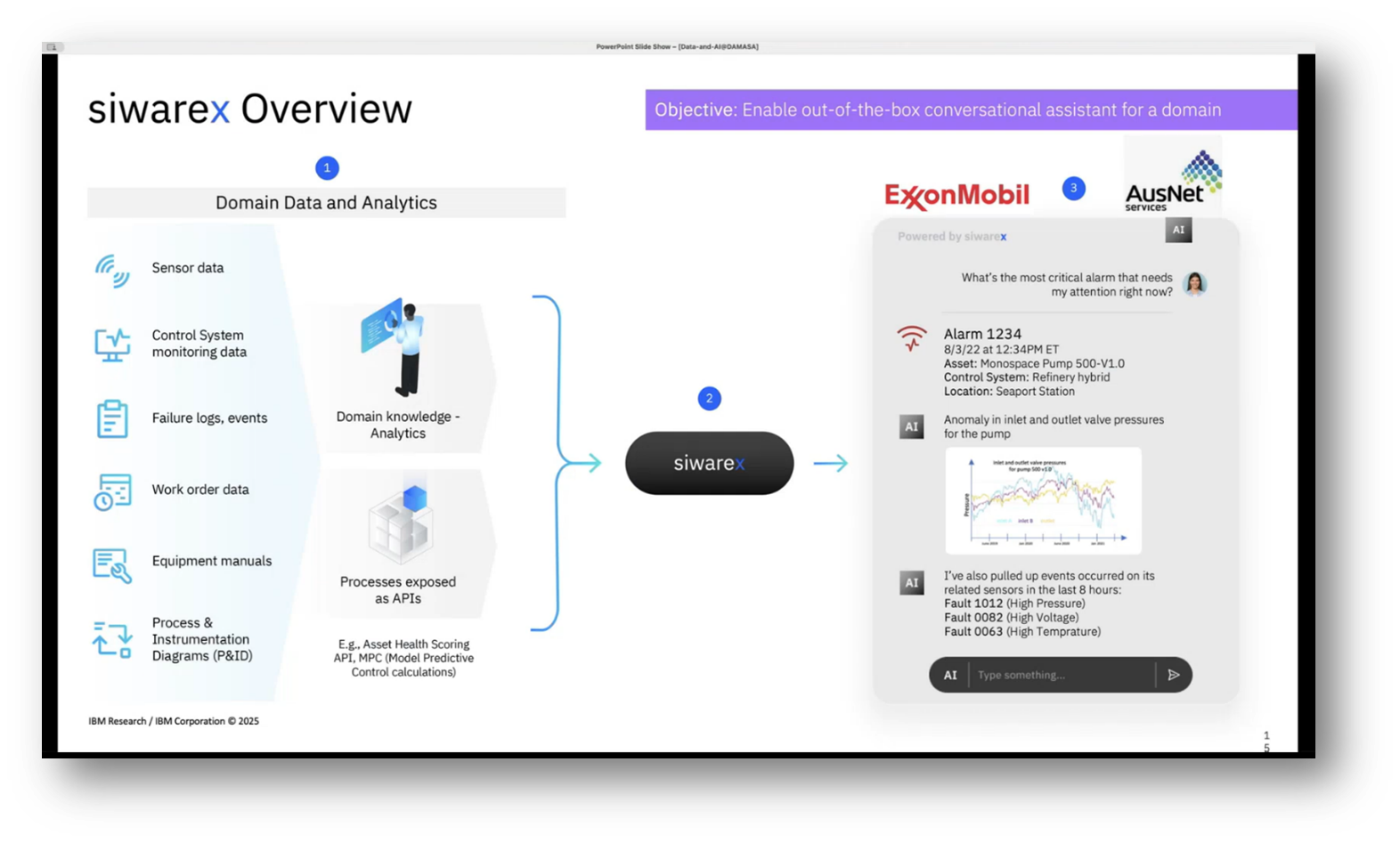
Figure 15 siwarex Overview
Demonstration of a Research Project's Pipeline Capabilities
Richard Young showcases a user interface developed as part of a research project, designed to illustrate the capabilities of an underlying pipeline, which will be integrated into various IBM products rather than being sold as a standalone product. Users can interact with the pipeline through the user interface, an API, or as a Python library, depending on their needs. Additionally, the pipeline is increasingly utilised in AI chat systems, such as HR chatbots, which can retrieve necessary information, like remaining leave days, by making calls to the pipeline to generate SQL queries and access relevant data for user responses.
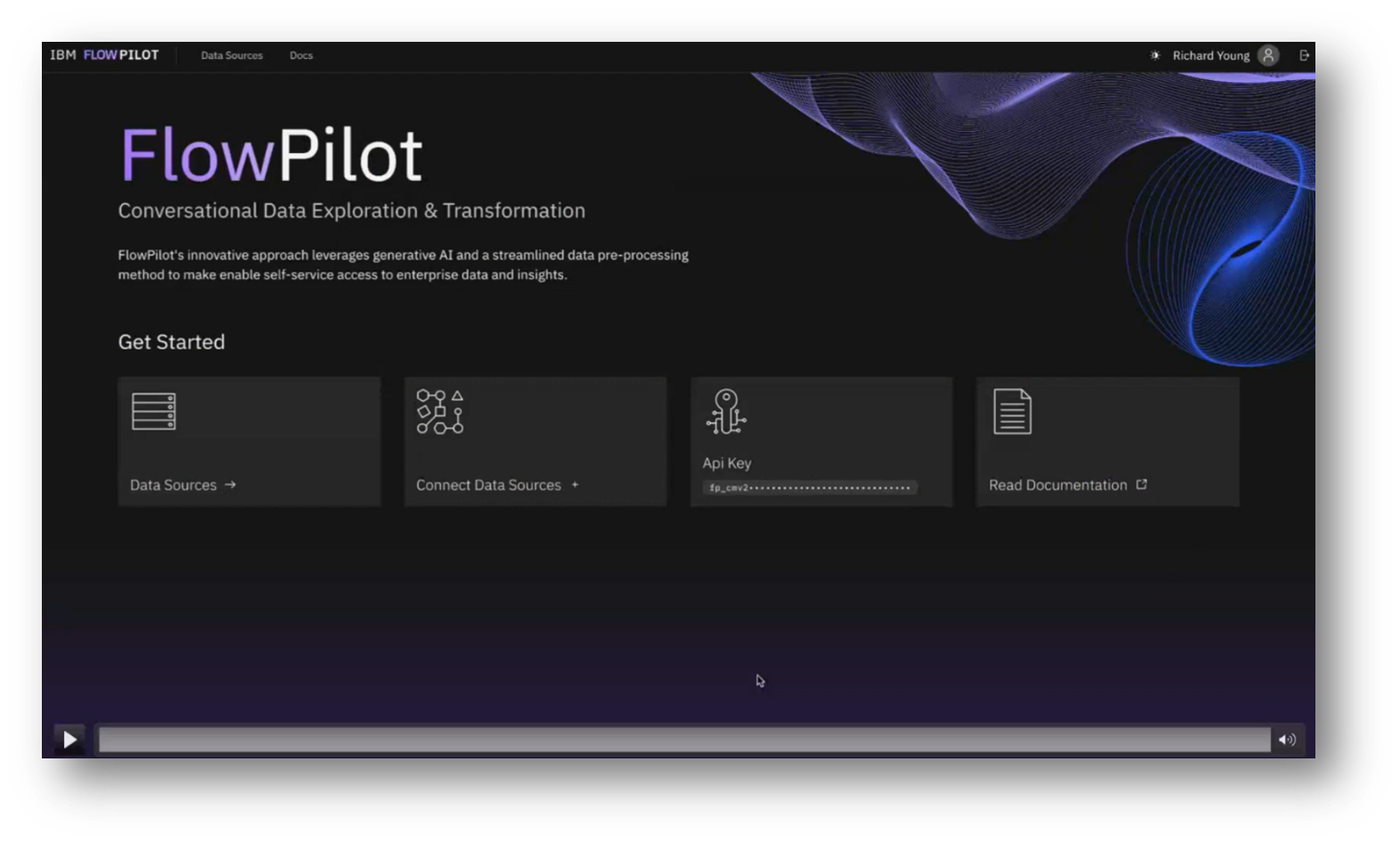
Figure 16 FlowPilot
Database User Interface and Query Execution
IBM’s Flowpilot user interface allows users to connect to various database types, primarily through read-only connections for data querying purposes. Users can select specific tables and schemas of interest, initiating an ingestion process that retrieves the database schema and data types and identifies categorical values.
Once ingestion is complete, users can interact through a chat interface, entering queries, such as requesting a list of the highest-grossing products, which triggers a pipeline that provides real-time feedback, including relevant tables and outputs a SQL query to fetch results.
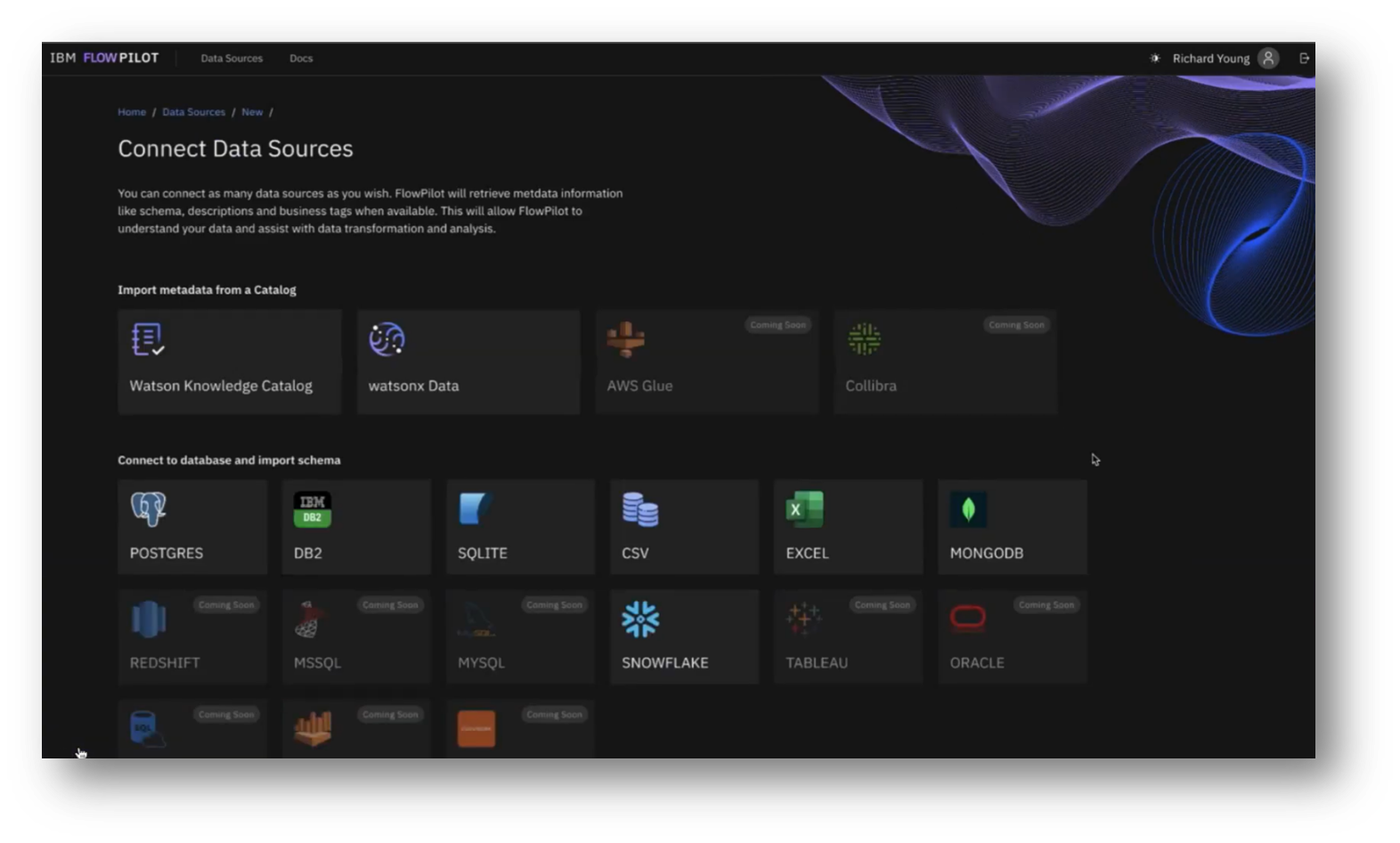
Figure 17 Connect Data Sources
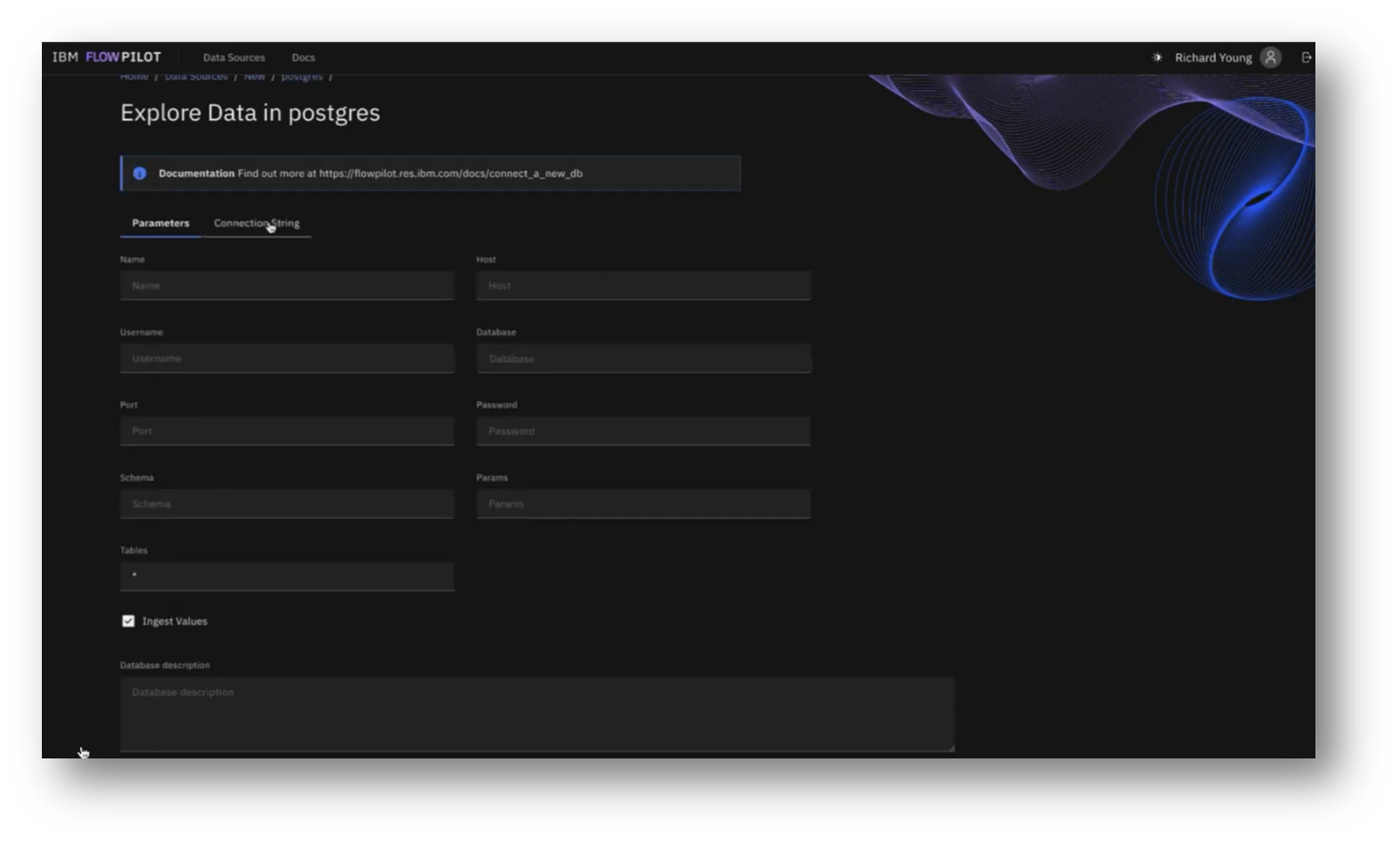
Figure 18 Explore Data in Postgres
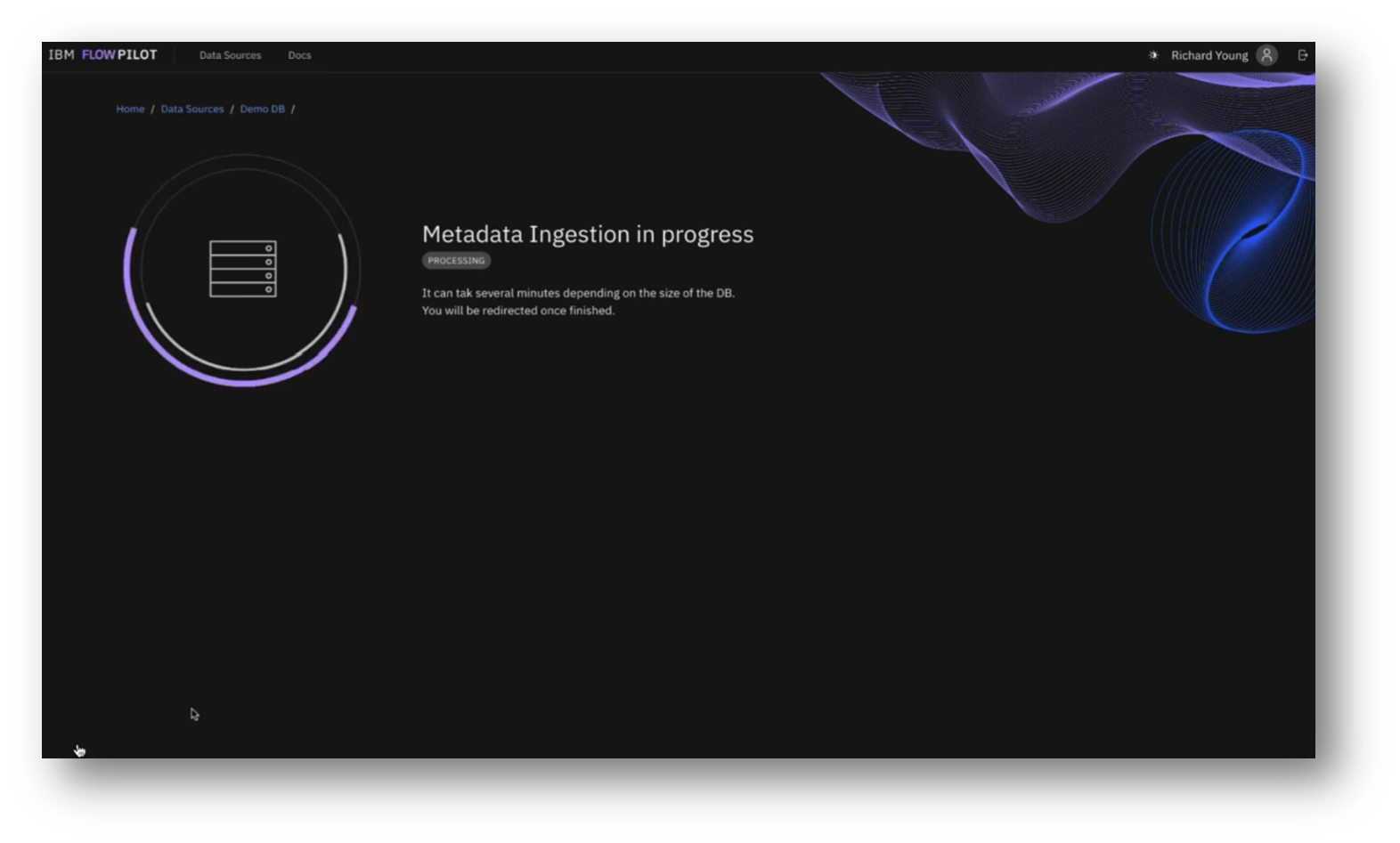
Figure 19 Metadata Ingestion
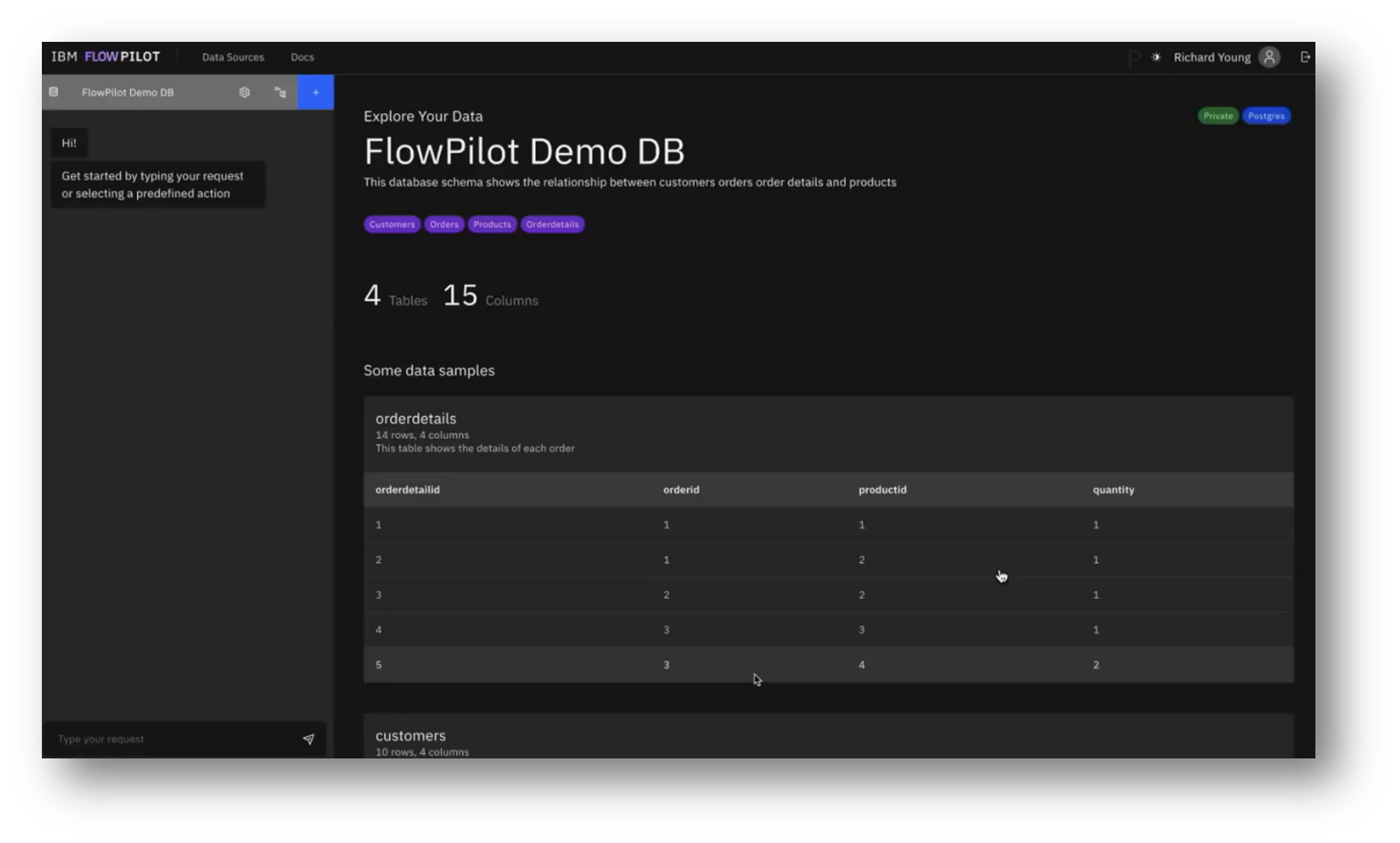
Figure 20 FlowPilot Demo DB
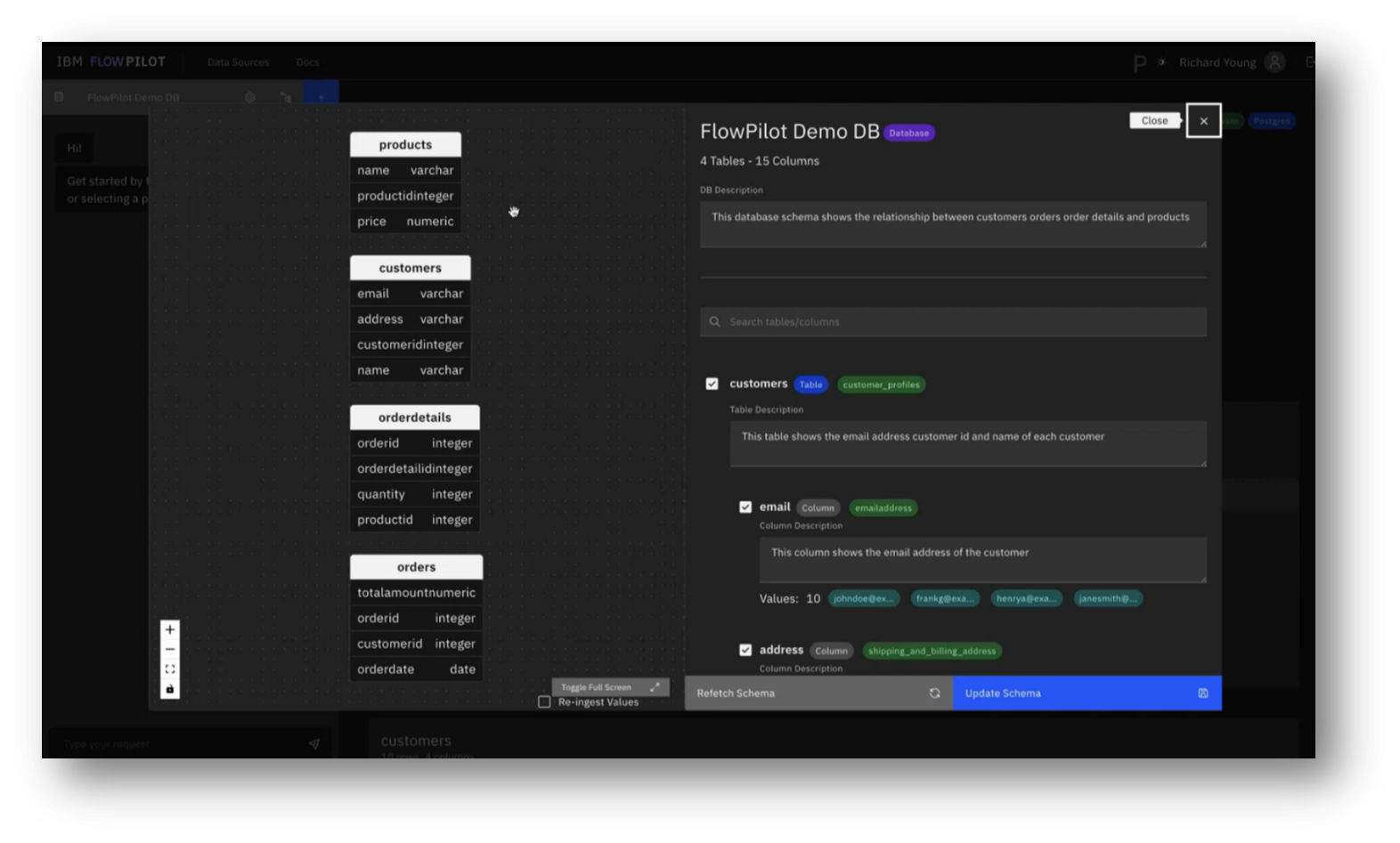
Figure 21 FlowPilot Demo DB: Schema
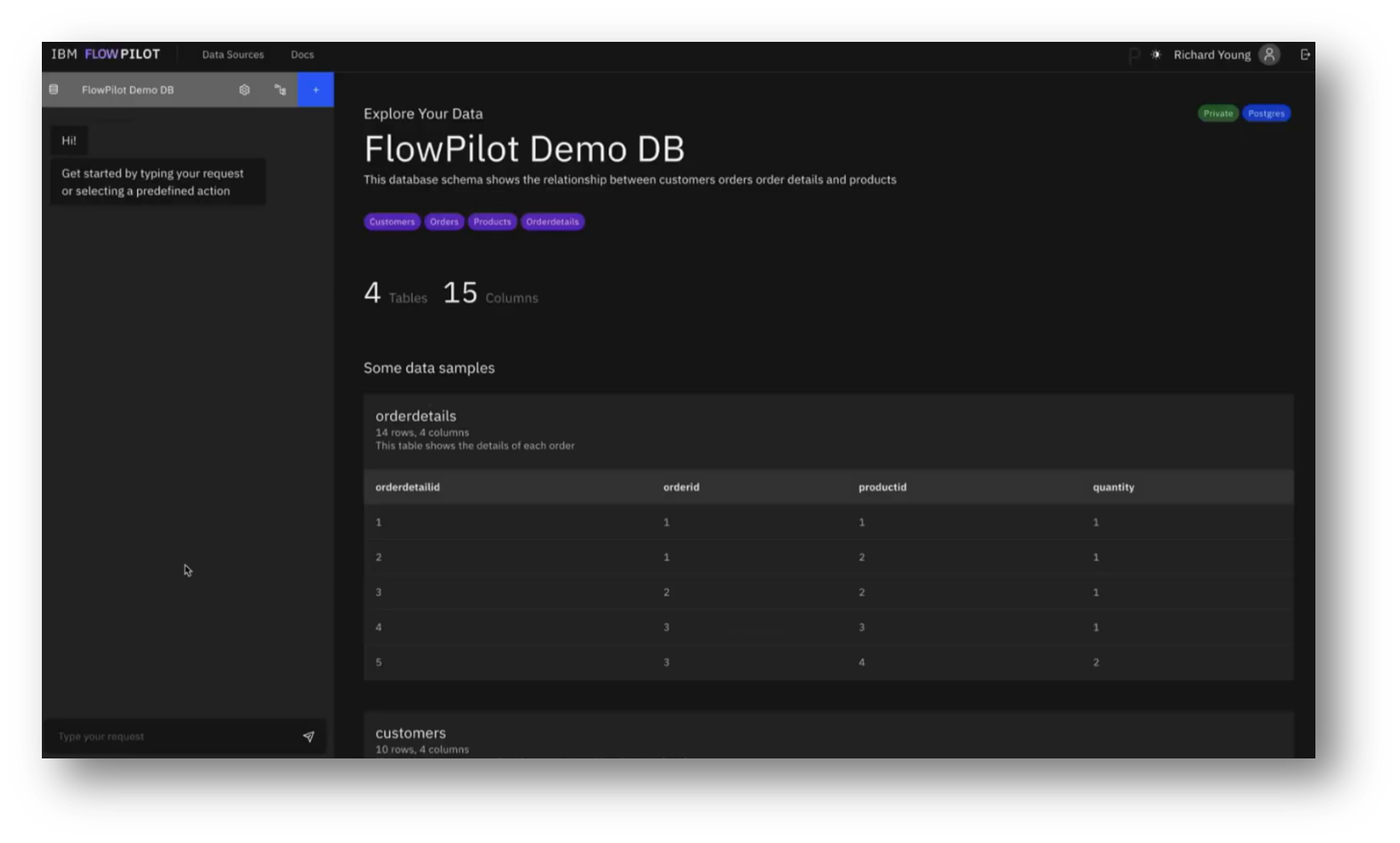
Figure 22 Prompting FlowPilot
Data Storage and Reinforcement Learning in AI Systems
Companies typically store their data within their own networks, ensuring it remains behind their firewalls and only allowing limited metadata extraction when necessary. IBM products facilitate this by enabling clients to interface with their data without transferring it off-site. The hybrid cloud approach allows businesses to run all code and models on their hardware, often requiring only one GPU, although there is exploration into CPU compatibility for clients without GPUs.
Additionally, some IBM mainframes equipped with specialised AI chips can handle inference for smaller language models. In terms of performance, IBM is investigating reinforcement learning techniques to enhance prompt analysis, allowing for pre-computation that could improve latency and semantic relevance.
An attendee shares that, in Zurich, research on reinforcement learning focuses on two main application areas: instruction fine-tuning with human feedback to enhance large language models (LLMs) in following instructions, and prompt generation to align generated SQL queries with expected data outputs.
The process involves assessing predicted and granted SQL sequences to refine the generation of future queries. Additionally, optimising SQL for enterprise use remains a challenge that requires adapting configurations and improving inference processes within existing hardware constraints. The Academy benchmark evaluates SQL outputs based on accuracy and optimisation, allowing for the potential use of both LLMs for SQL generation and optimisation, as well as non-LLM techniques to enhance unoptimised queries.
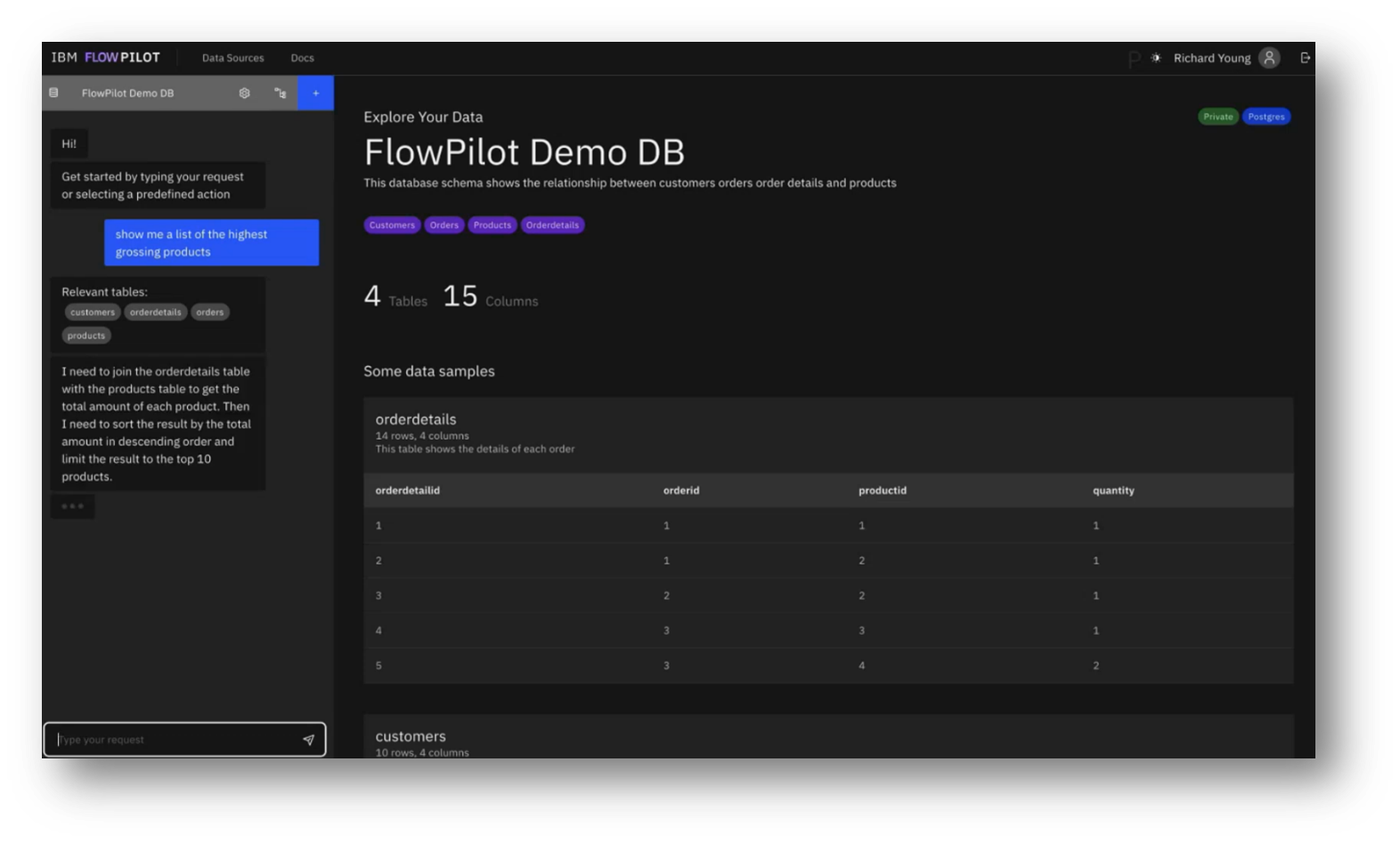
Figure 23 FlowPilot Prompting Pt.2
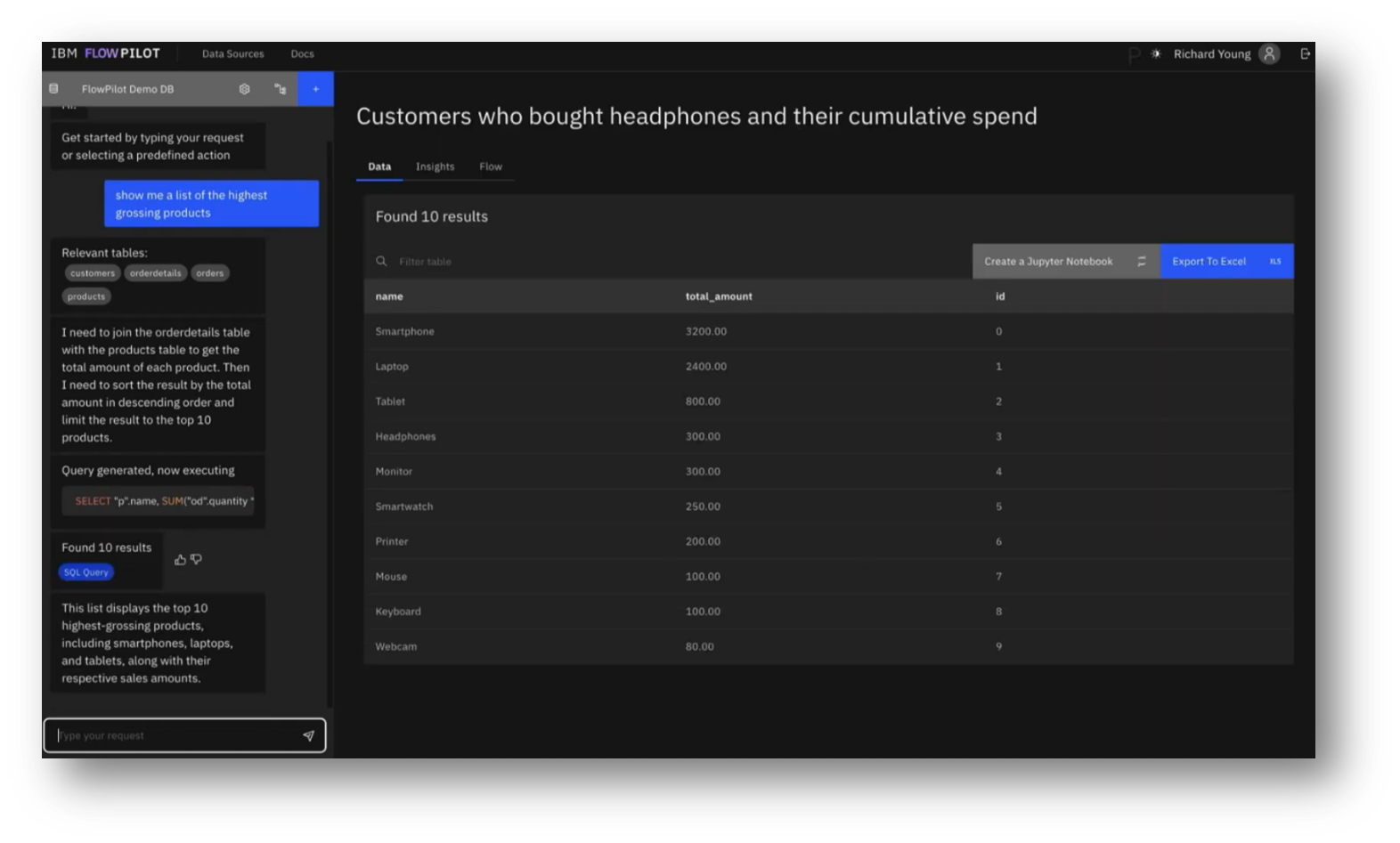
Figure 24 FlowPilot Prompting Pt.3
Potential Improvements of a Query Generation System
With a focus on a list of the highest-grossing products, they examined the complexities of modifying queries, particularly by excluding sales on Mondays, which introduced ambiguity requiring the context of previous queries and an understanding of the data structure. The generated SQL demonstrated a logical approach, including a WHERE clause to extract the day of the week from the order date.
The primary challenges identified were not in SQL generation but in understanding user intent and data characteristics. To enhance the model's effectiveness, the team emphasised the importance of configuring the data source, setting descriptions for tables and columns, and providing example utterances and SQL pairs. They also highlighted the value of including static context, such as domain-specific language and reference dates, and mentioned various pre-trained models available for testing.
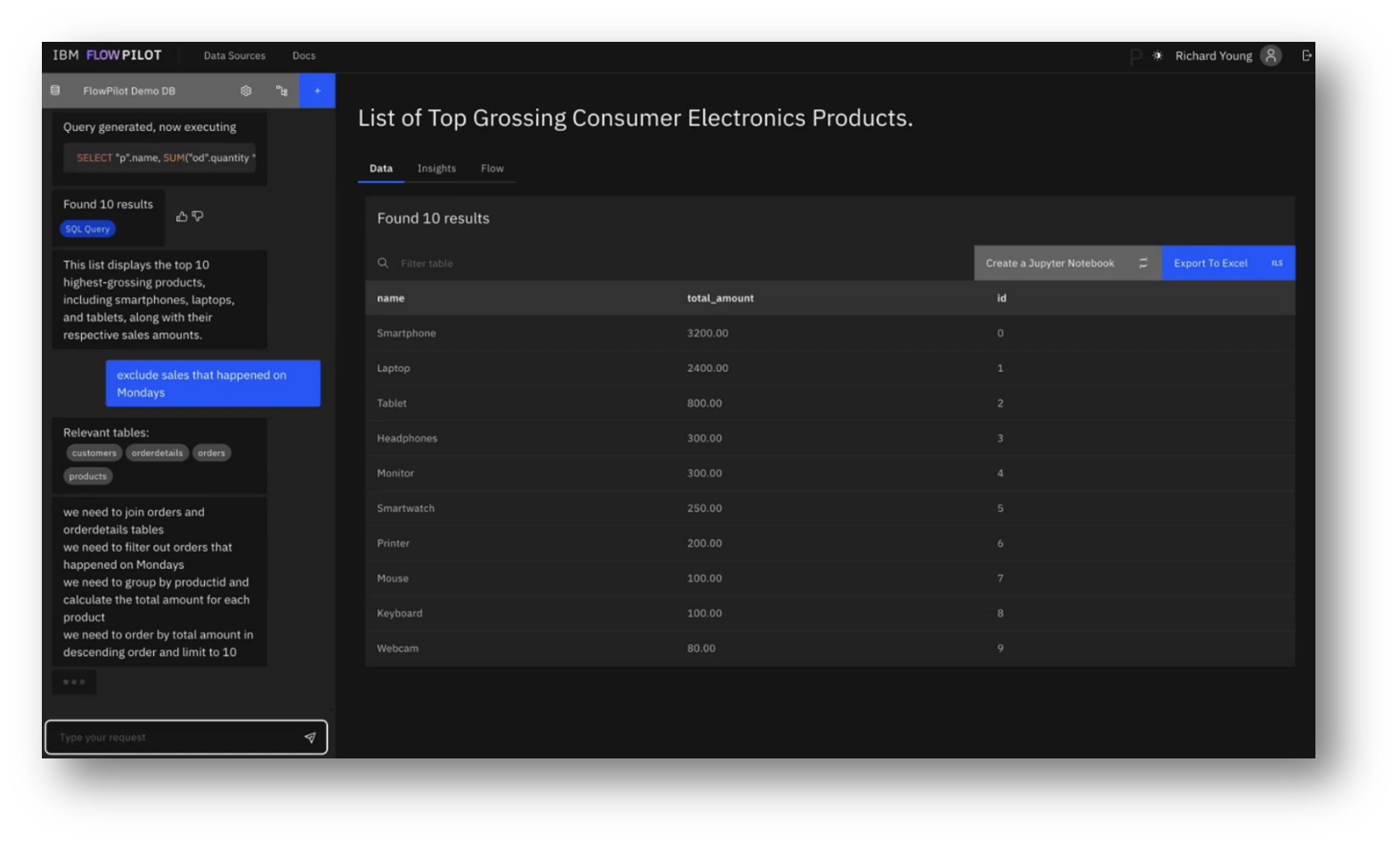
Figure 25 FlowPilot Prompting Pt.4
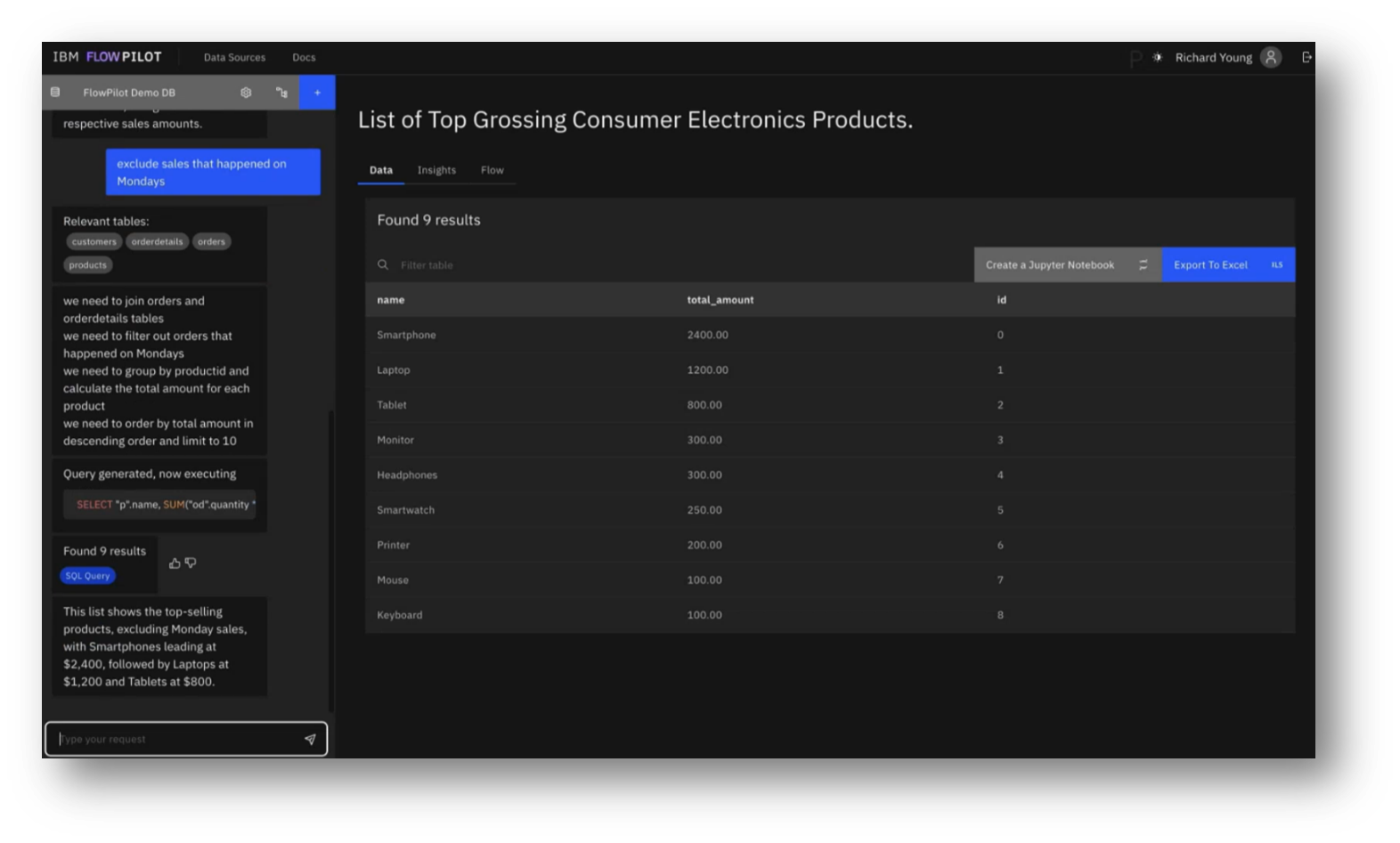
Figure 26 FlowPilot Prompting Pt.5
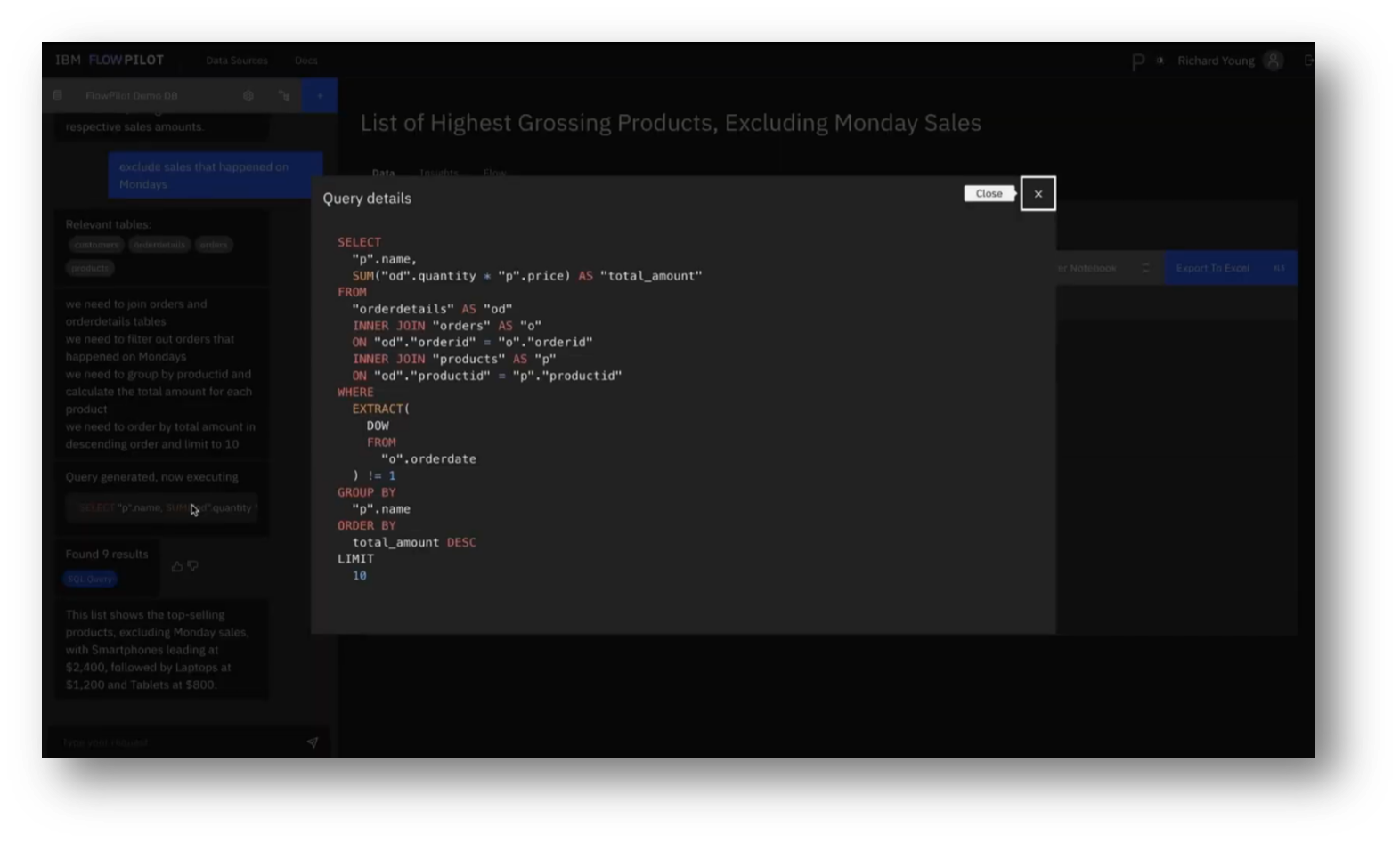
Figure 27 Query Details
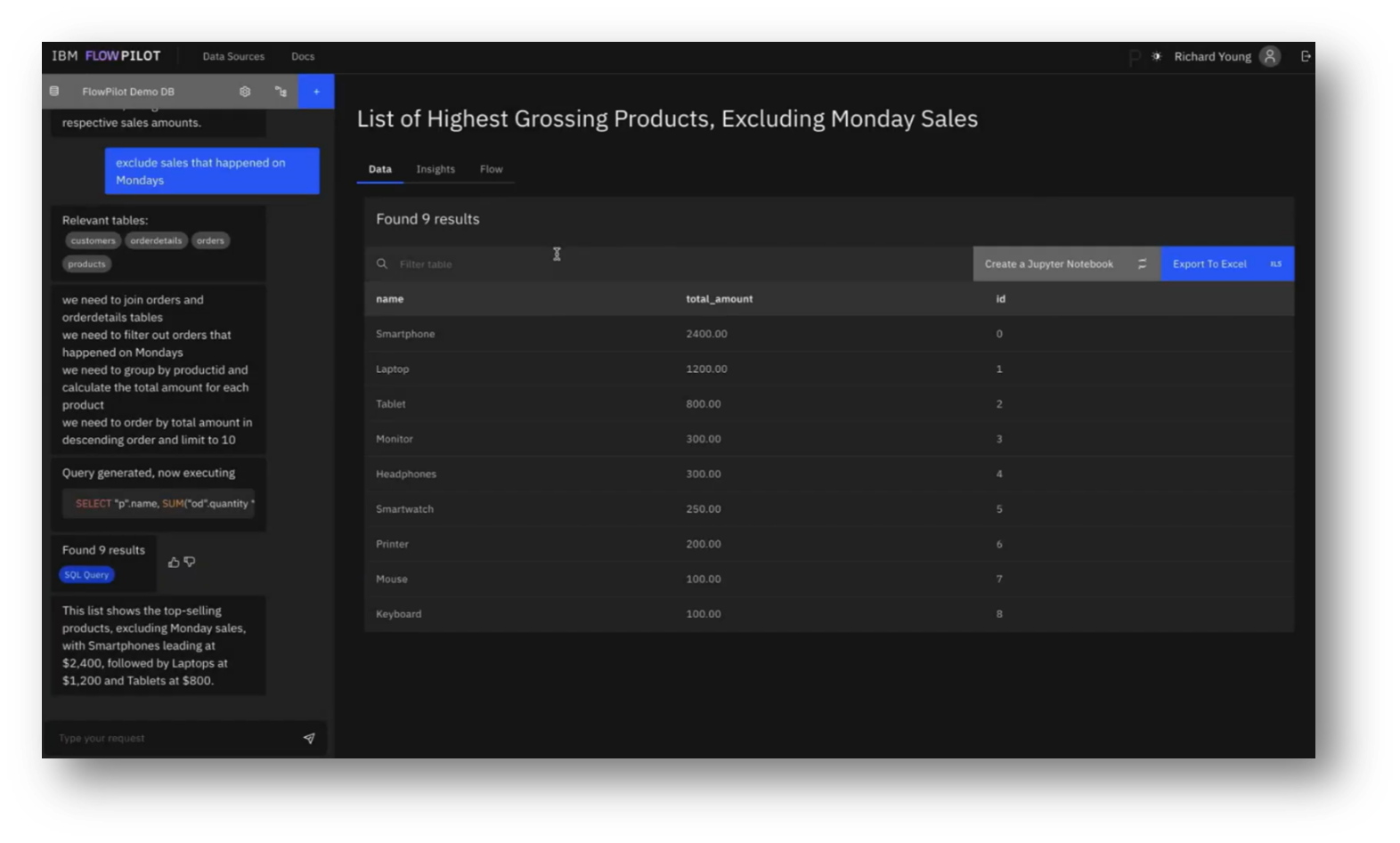
Figure 28 FlowPilot Prompting Pt.6
Figure 29 Data Sources
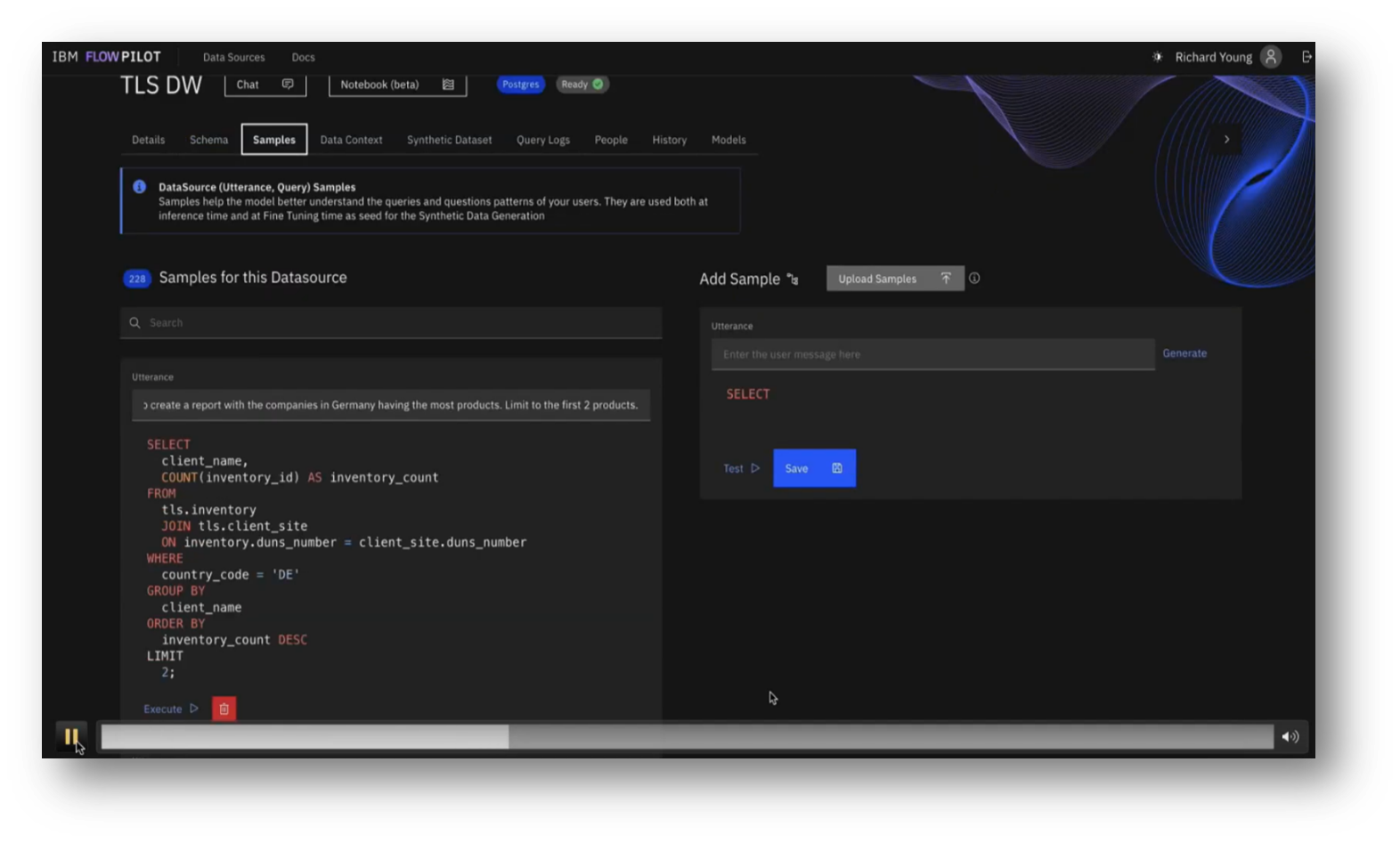
Figure 30 Data Source Utterance
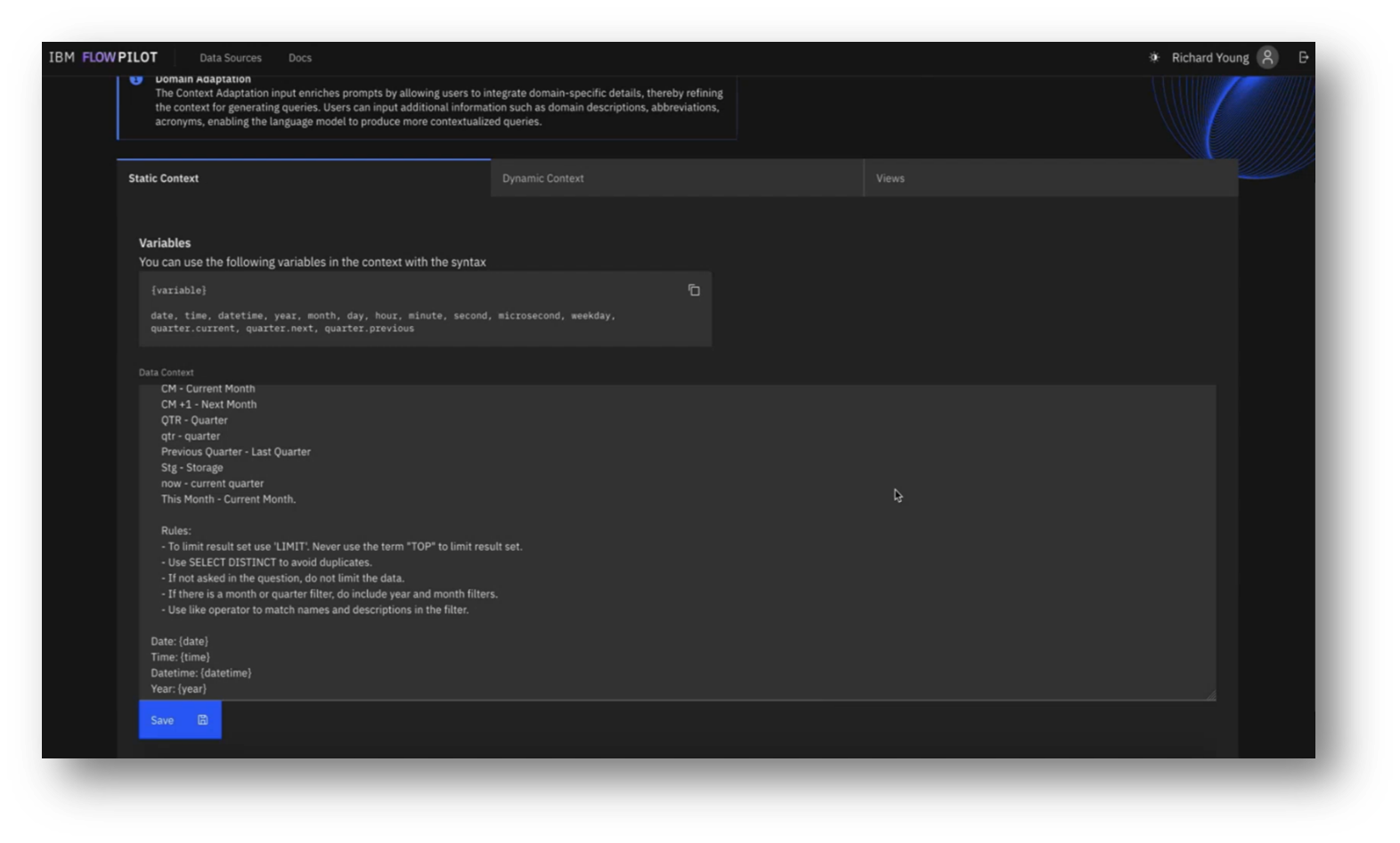
Figure 31 Static Context
Figure 32 AI Models
Understanding the Components of a Text-to-SQL Pipeline
In a typical text-to-SQL pipeline, the process begins with prompt rendering, which is crucial for guiding the model's output. Since most large language models (LLMs) are stateless and cannot access external data, the prompt must comprehensively include all necessary information for generating the SQL query. This usually starts with setting the context through system instructions and providing the schema, often formatted as CREATE TABLE statements.
For smaller databases, the entire schema can be included, but larger databases require schema linking to identify relevant tables while considering prompt size limitations. This involves selecting essential tables to ensure the model has the necessary context, as excluding any critical table can lead to incorrect SQL generation. Additionally, examples of utterance and SQL pairs can help clarify expectations, while rules and contextual information may be added to address recurring errors. Finally, the dialogue history with the user is included to maintain context, as LLMs do not retain memory of past interactions.
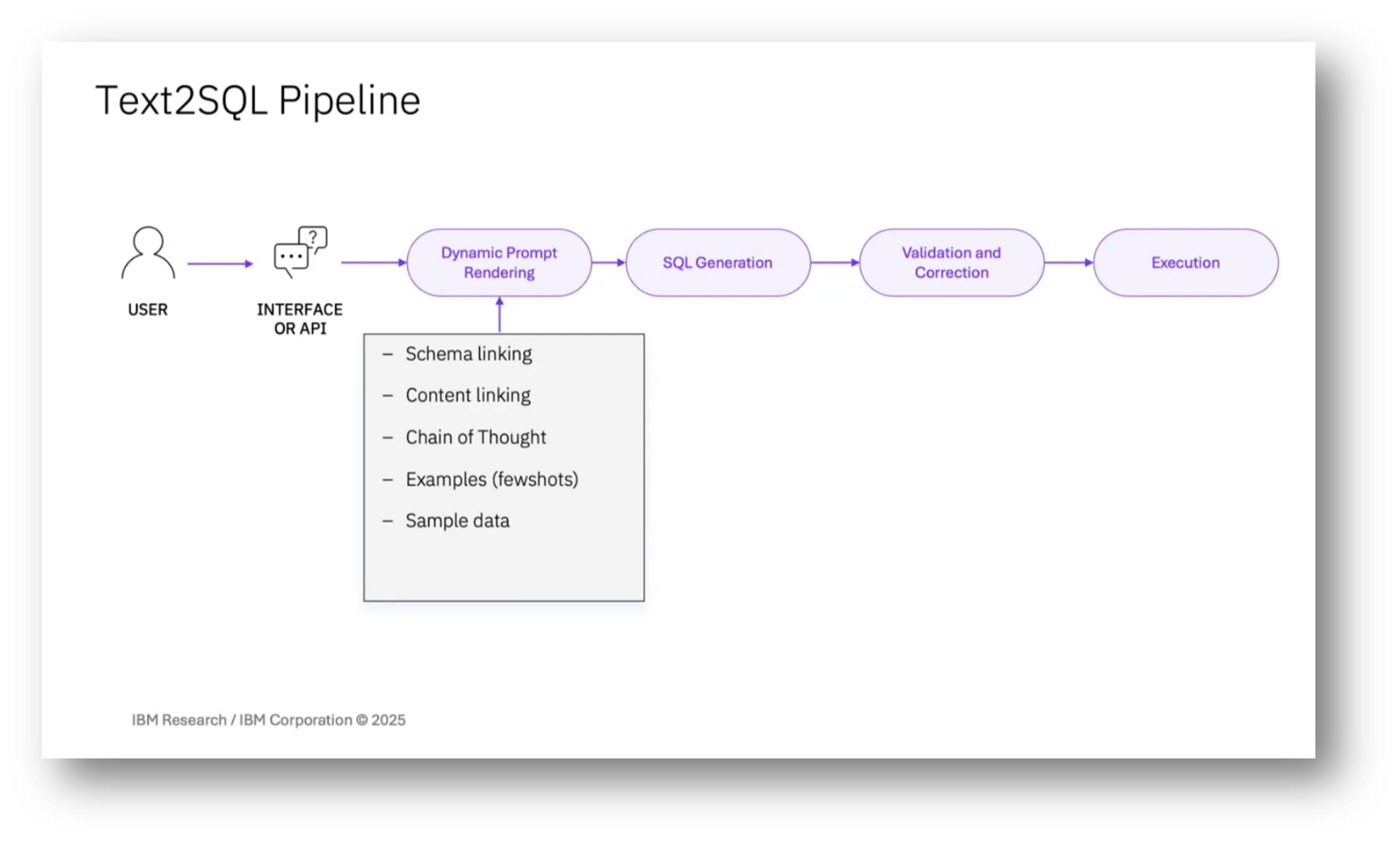
Figure 33 Text2SQL Pipeline Diagram
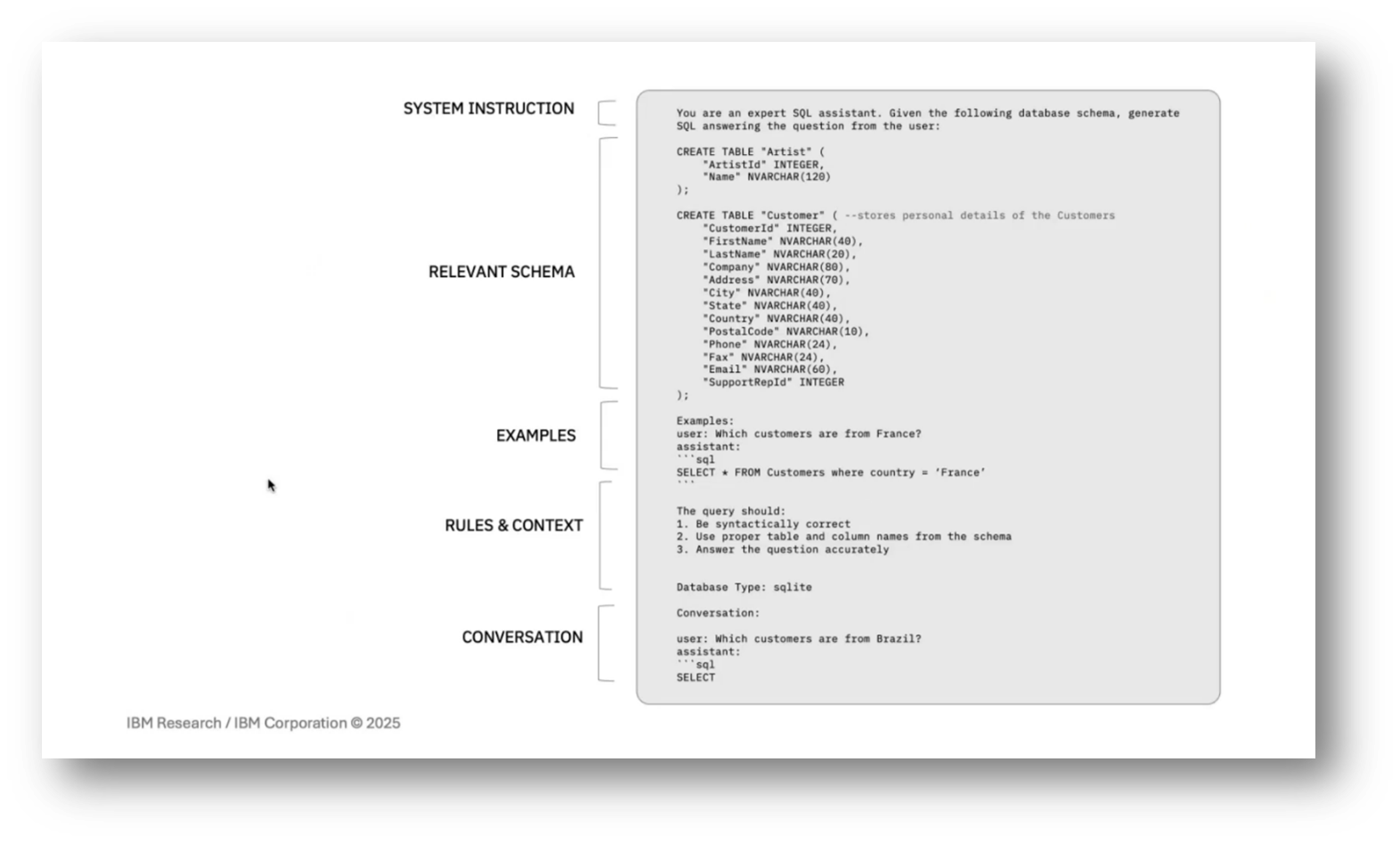
Figure 34 IBM Research
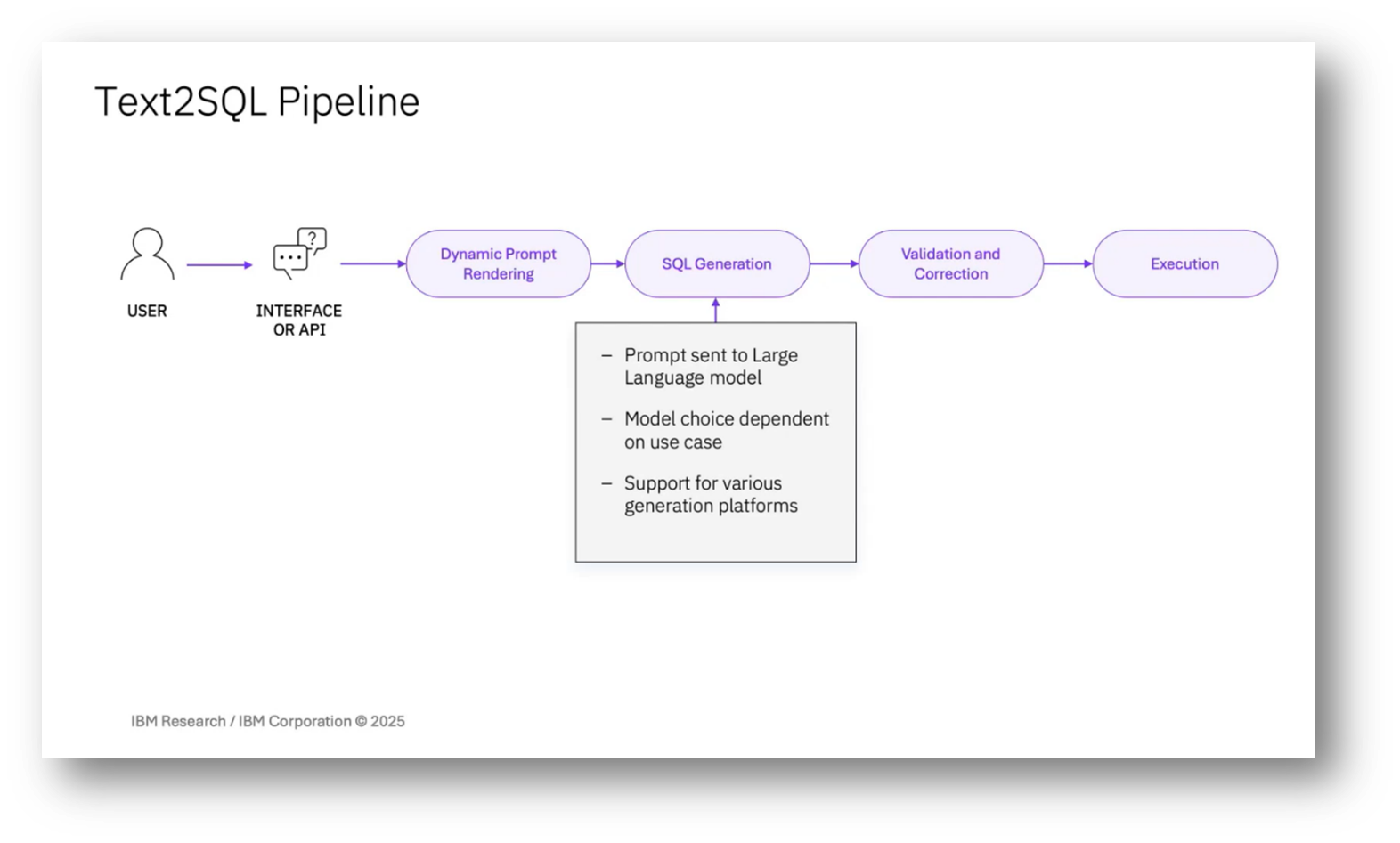
Figure 35 Text2SQL Pipeline Pt.2
Script Generation and Database Management in AI
The process of SQL generation involves sending prompts to a selected large language model, typically chosen based on the client's GPU resource budget, with a general preference for smaller models. Various generation platforms are supported, including OpenAI and others, and models may be fine-tuned for clients with substantial data. After receiving a successful response, a validation and correction component checks for the validity of the query, ensuring that it is safe to execute on a database without altering its state, and verifies that it adequately addresses the user's question. Execution of the sequel in the database is optional, as some clients prefer human oversight, and when executed, result sets are limited to prevent database issues.
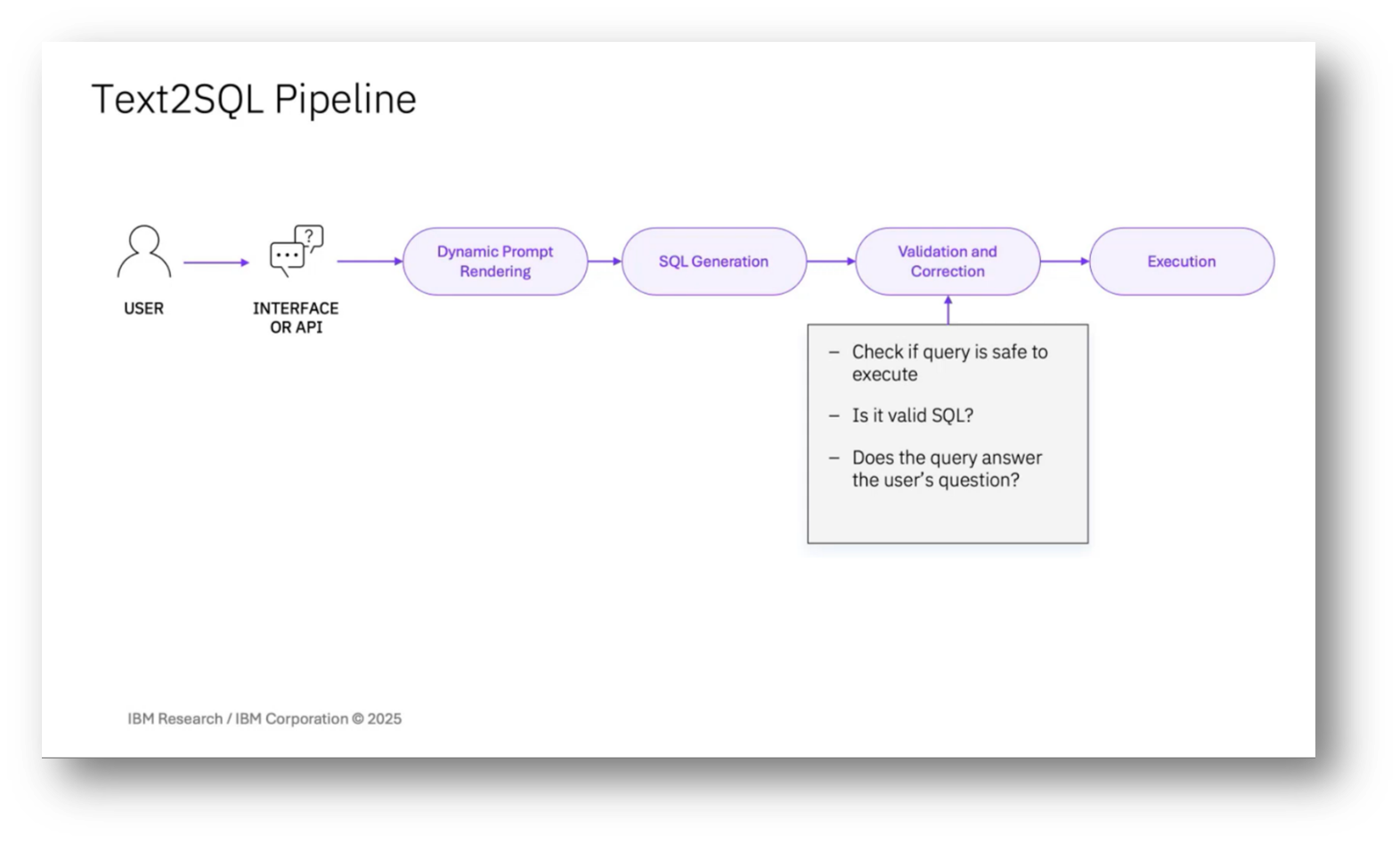
Figure 36 Text2SQL Pipeline Pt.3
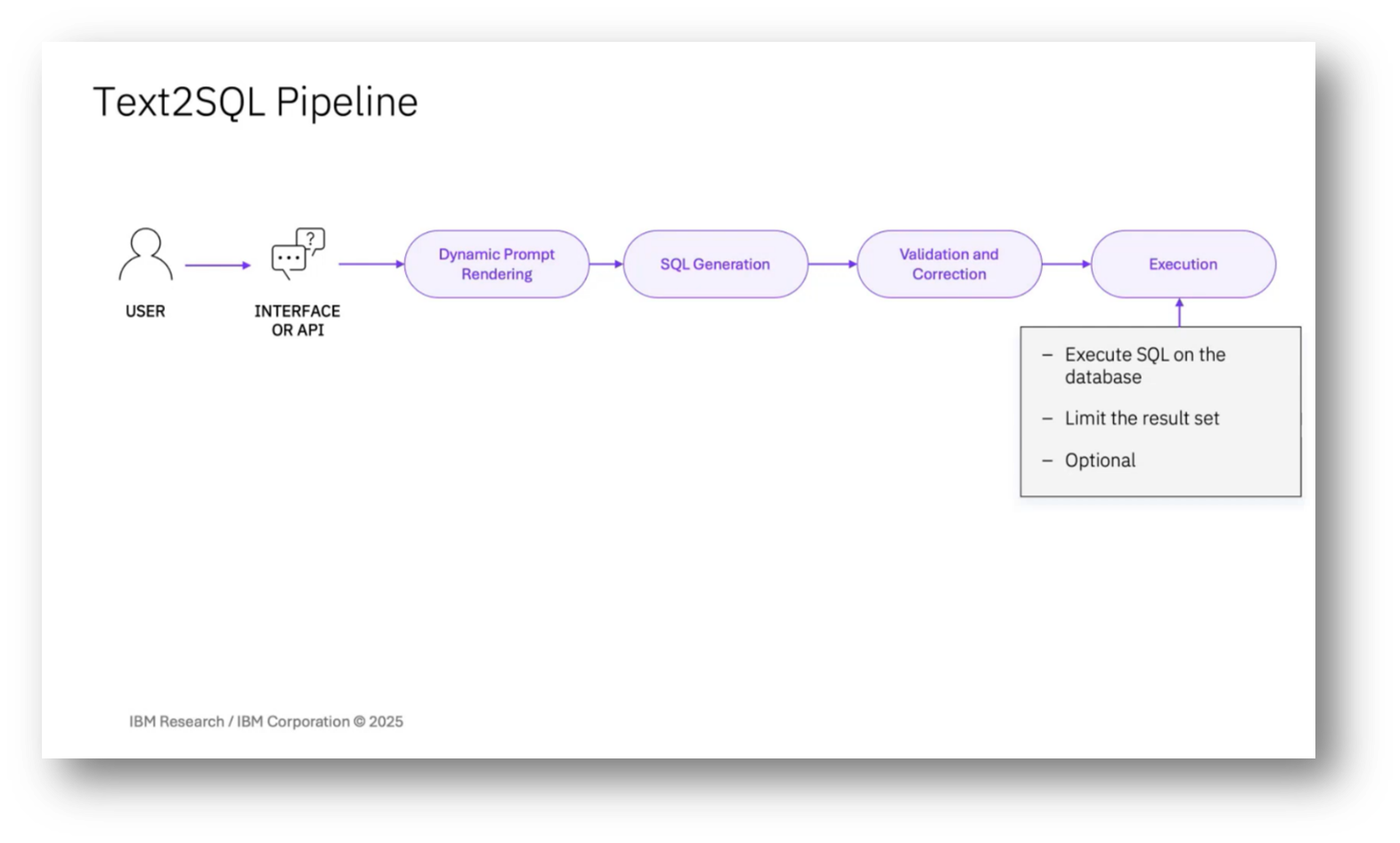
Figure 37 Text2SQL Pipeline Pt.4

Figure 38 "Pipeline configurations don't generalise well"
Developing a Text-to-SQL Pipeline
The development of a text-to-SQL pipeline initially aimed for optimisation based on academic benchmarks, but it became clear that a one-size-fits-all approach was inadequate. This led to the redesign of the pipeline into a composable graph-based framework, allowing for customisable configurations in nodes and connections.
The framework supports parallel node execution for speed and facilitates error handling by reconnecting errors from database queries back into the prompt for LLM correction. IBM researchers have the flexibility to create and test their own nodes within this environment, enabling them to conduct benchmarks and explore various approaches. Each node represents a distinct area of research requiring dedicated teams for improvement.
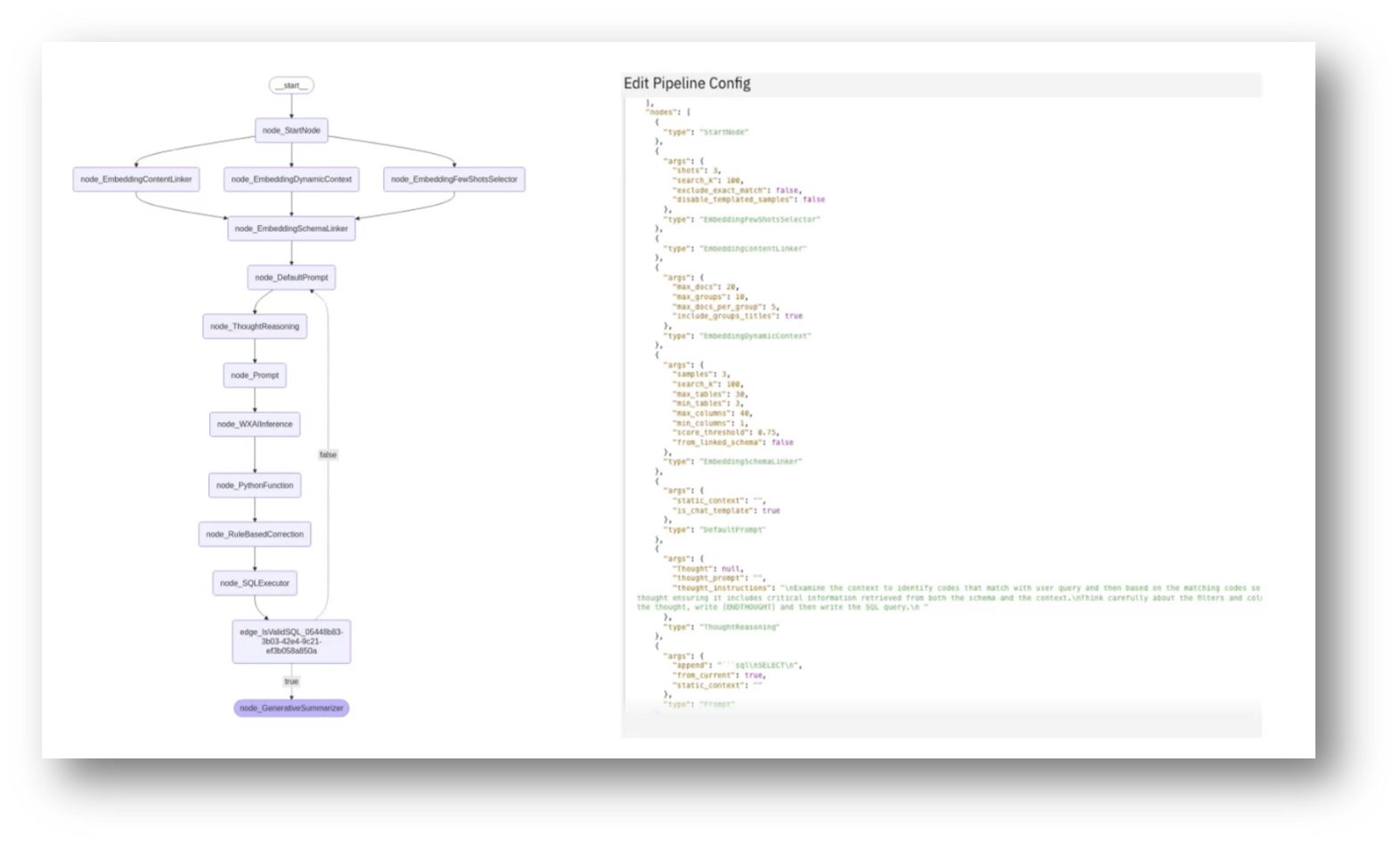
Figure 39 Pipeline Configuration

Figure 40 How to Optimise a Pipeline for A Use Case
Optimising Database Pipelines for Use Cases
A comprehensive evaluation component is essential to optimising a pipeline for generating SQL queries. Users input a test set of utterances and expected SQL queries, which allows for performance benchmarking through comparison of generated and expected results against the database.
Automation of configuration changes is explored to identify improvements in performance, while error analysis helps pinpoint issues, such as missing tables during schema linking, which can affect query generation accuracy. Additionally, the involvement of domain experts is crucial, especially in complex enterprise databases, as their understanding of the structure is necessary for effective pipeline setup. While AI can enhance and expedite data extraction processes, human expertise remains vital in these scenarios.
Data Management and Semantic Challenges in Natural Language Processing
An attendee raised a question regarding the handling of varying spellings of metadata and data values that refer to the same entity, specifically in contexts where different applications use distinct metadata labels. They highlighted the challenges of schema mapping, where equivalent terms, like "stock name" and "STK-NM," might not match directly.
Richard responses with emphasises on the strategies for addressing these issues, including the use of column and table descriptions to provide aliases, as well as leveraging vector stores to facilitate searches for semantically similar terms, despite differences in spelling or terminology, such as "province," "state," or "county."
In the ongoing research, Richard shares that they are exploring methods to enhance schema correction by identifying semantically similar column names when a requested column does not exist within a schema. For example, if a query requests customers with the province "carting," but the "province" column is absent, we can utilise a vector store to find a similar column ", state," and substitute it accordingly.
Lastly, Richard shares that they are investigating the integration of traditional NLP techniques with knowledge graphs to better understand domain-specific jargon and abbreviations, which can often hinder accurate SQL generation. This approach aims to leverage existing knowledge graphs that describe entity relationships and contextual information from relevant business documents, although it is still in the research phase and not yet fully integrated.
Role of Domain Experts in Data Management
An attendee inquired about the concept of domain experts, particularly in the context of IBM's internal clients who focus on specific product areas. A domain expert typically has in-depth knowledge of a data warehouse's schema and how data fields are utilised, but may lack insight into the actual values and their corresponding business processes.
Scepticism was also expressed by an attendee on the current capabilities of using large language models (LLMs) to connect these definitions back to business processes, suggesting that the technology is still in the research phase and not yet suitable for larger projects. Additionally, Richard shares that the potential for LLMs to serve not only as tools for data quality but also for deeper insights into business processes remains an area of interest for future exploration and feedback as the tool's usage expands.
Data Management and Quality in the Context of Migration and Governance
The discussion between Richard and an attendee highlights the critical importance of data quality in management and executive buy-in during data migrations. The attendee emphasises that without proper data cleansing, organisations risk simply transferring flawed data, resulting in dissatisfaction with the tools used. To ensure successful outcomes, it is essential to establish a separate data store for quality data, reinforcing the necessity for only high-quality information to be migrated.
It was pointed out that potential challenges exist if technology and data quality efforts do not run parallel, suggesting that focusing solely on technology may lead to the development of tools that ultimately do not meet user needs. Effective communication of these points is crucial for driving business results and securing executive support.
IBM has developed data management and governance platforms, with IBM Knowledge Catalogue serving as a key example. Ndivhuwo shares that the team is currently collaborating with the product team to enhance the integration of text-to-SQL capabilities within this data governance platform, which assumes that users have effectively managed and governed their data for optimal use. While the team focuses on developing research, the product team works on the actual platform and provides insights and best practices to facilitate innovative solutions that enhance user experience and functionality.
Text to SQL Pipelines and Challenges in AI Research
Another attendee enquired about the application of text-to-SQL pipelines in critical quantitative settings, such as petrochemical refinery set point recommendations; however, the current use is primarily in AI systems and chatbots that extract data from databases to answer queries, rather than in mission-critical processes. Nidivhuwo elaborated on the challenges faced by the research team, highlighting the need to balance product development demands with the time required for advanced research. The team aims to enhance IBM products while contributing to the scientific community, necessitating a strategic alignment between short-term and long-term research goals, which is a common challenge faced by many organisations.
Challenges and Strategies in Creating a Minimal Viable Product
Richard highlights the challenges of developing a minimal viable product for text conversion, particularly emphasising the need for accuracy. To mitigate risks associated with using only academic datasets, he adds that the team prioritises the use of real-world datasets, referred to as "client zeros," to ensure practical applicability and avoid potential failures during product delivery.
Prototyping efforts involve collaboration with product teams to gather requirements, ensuring continuous feedback for incremental improvements. Additionally, the team seeks to establish partnerships with external entities to co-create solutions that incorporate the latest technologies for specific use cases.
Future of Data Management and AI in Relational Databases
The current focus on structured or relational databases is highlighted, with an emphasis on text-to-SQL applications, while acknowledging the growing importance of exploring unstructured data. Researchers are working on bridging the gap between structured and unstructured data, aiming to enhance data management processes in preparation for AI applications, particularly showcasing this at an upcoming IBM Think event.
If you would like to join the discussion, please visit our community platform, the Data Professional Expedition.
Additionally, if you would like to be a guest speaker on a future webinar, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!