
Data Mesh Diaries with Corné Potgieter
Executive Summary
This webinar outlines the key aspects of Data Mesh implementation, reflecting a personal journey into its conceptual framework and implications for organisations. Corné Potgieter highlights the future potential of Data Mesh, addressing various project implementations and the inherent challenges of early adoption, particularly within large-scale organisations. He emphasises the guiding principles for successful implementation while navigating complexities in decision-making, analytics, and regulatory compliance.
Corné discusses strategic initiatives for Data Mesh, focusing on data ingestion, security, product building, and transformation architectures. Furthermore, he examines data warehousing methodologies, the implementation of data contracts, vendor management, and the impact of global policies on data design. Lastly, the webinar offers insights into the ongoing debate between centralisation and decentralisation, autonomy in decentralised systems, and the critical roles of data quality and automation in product development.
Webinar Details
Title: Data Mesh Diaries with Corné Potgieter
URL: https://youtu.be/FRe-YVCpoSE
Date: 03 March 2025
Presenter: Corné Potgieter
Meetup Group: DAMA SA User Group
Write-up Author: Howard Diesel
Contents
Data Mesh Implementation: A Personal Journey
Understanding the Concept of Data Mesh in Organisations
Understanding the Implications of Data Mesh
Future of Data Mesh: its Potential and Future Prospects
The Implementation of Data Mesh in Various Projects
The Challenges of Early Adoption in Business
Data Mesh Implementation in Large-Scale Organisations
Guiding Principles for Successful Data Mesh Implementation
Challenges in Decision Making in Business Technology
Navigating the Balance between Analytics and Regulatory Compliance
Strategy for Data Mesh Initiative
Data Ingestion and Security in Data Mesh Platforms
Data Product Building and Transformation Architecture
Data Warehousing Methodologies and Challenges
Approaches in Data Warehousing
Data Transformations and Abstraction in Data Platforms
Implementation of Data Contracts in Business
Vendor Management and Tech Stack Selection in Organisations
Impact of Global Policies and Legislations on Data Design
Future of Data Mesh: Centralisation vs Decentralisation
Autonomy in Decentralised Systems
Data Quality, Automation, and Role in Data Products
Naming Strategies in Project Implementation
Data Mesh Implementation: A Personal Journey
Corné Potgieter opens the webinar and shares that he will be covering the concept of Data Mesh, including its definition, relevance, and his personal experiences implementing it in two organisations. Additionally, Corné shares that key topics of the presentation include the rationale for adopting a Data Mesh framework, insights from early adopters, and practical challenges faced in large-scale implementations. He adds that he will also highlight guiding principles for successful Data Mesh implementation and share anecdotes and examples related to its core components, such as integration, data modelling, logical layers, technology platform selection, and data security.
Figure 1 Data Mesh Diaries

Understanding the Concept of Data Mesh in Organizations
Data Mesh is a decentralised approach to managing and analysing data within organisations, addressing the limitations of traditional centralised analytics teams. Historically, companies relied on these centralised teams, which created bottlenecks and delays due to their sole ownership of technical skills and operational data pipelines. As a result, domain teams, which possess specific knowledge about their areas, were often frustrated by the slow response times and the heavy investment required for changes.
It is important to note that Data Mesh shifts the responsibility of data management from centralised teams to these domain teams. Furthermore, it empowers teams to develop their own data products and promotes a domain-oriented decentralisation of analytical data capabilities.

Figure 2 “What is Data Mesh?”

Figure 3 Why need Data Mesh?
Understanding the Implications of Data Mesh
Data Mesh is a social and technical approach to data management that emphasises domain-oriented decentralisation and team autonomy. Coined by Zhamak Dehgnhani in 2019 while at ThoughtWorks, Data Mesh transforms how organisations handle data by assigning domain teams responsibility for their own data products, effectively decentralising ownership from a central team.
Corné goes on to share that Data Mesh advocates treating data as a product, ensuring high quality and accessibility for other teams, and establishing a self-service data platform that equips teams with the necessary tools and technology. Additionally, it supports federated governance to standardize and ensure compliance across data products while allowing for interoperability within organizational and industry regulations.
Decentralised and federated terms are often used interchangeably, however, they have different implications for data strategy and organisational structure. Federated governance involves a governance group that establishes global policies but empowers teams to remain compliant without imposing strict mandates, thereby promoting autonomy within a controlled framework. This approach aims to strike a balance between centralized functions and team autonomy, avoiding the pitfalls of complete independence that can lead to unregulated shadow IT. Lastly, Corné underscores the importance of enabling domain teams to deliver high-quality data products, with a focus on finding the right equilibrium between centralisation and decentralisation.

Figure 4 Why need Data Mesh?

Figure 5 What is Data Mesh?
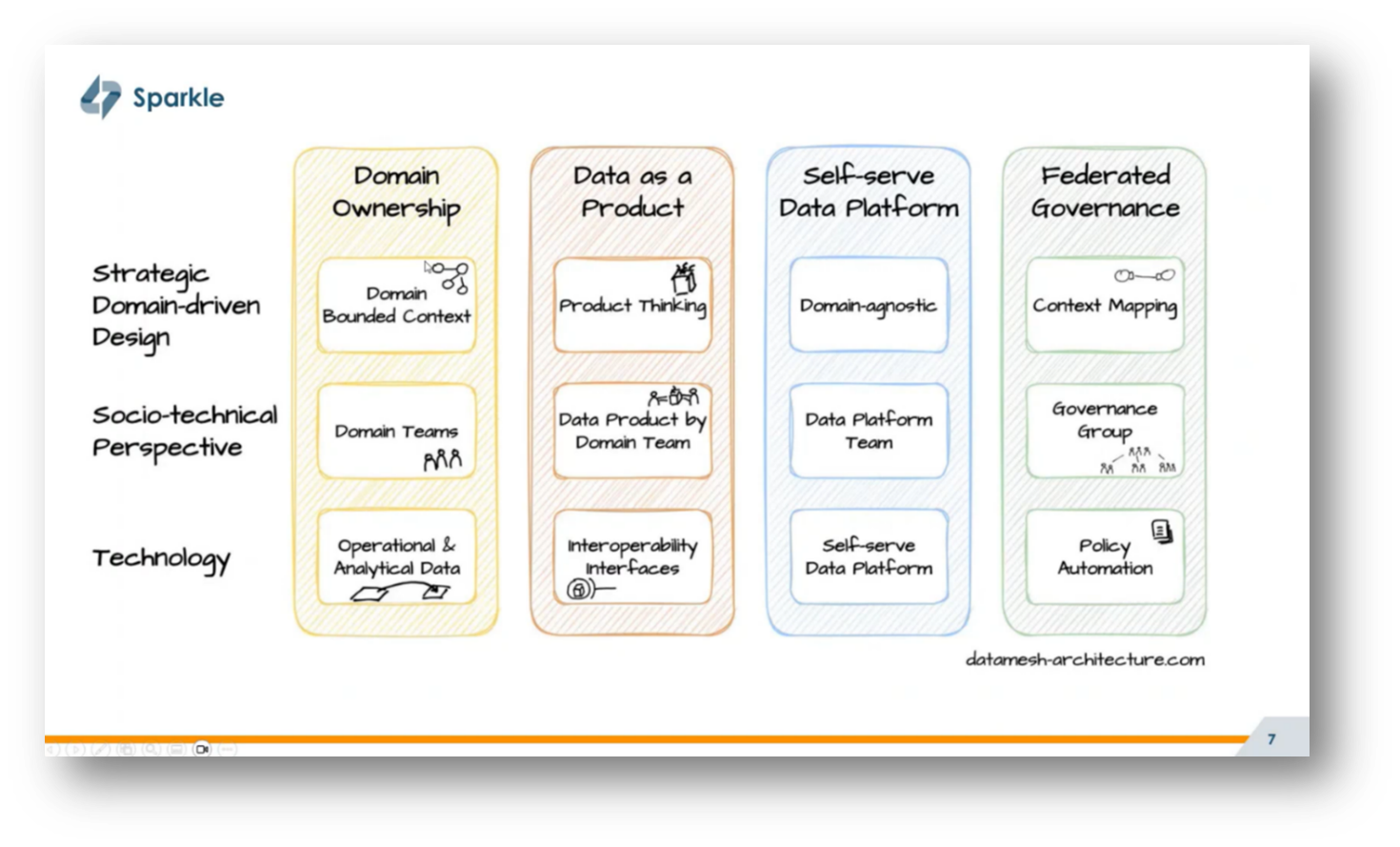
Figure 6 Four Pillars of Data Mesh
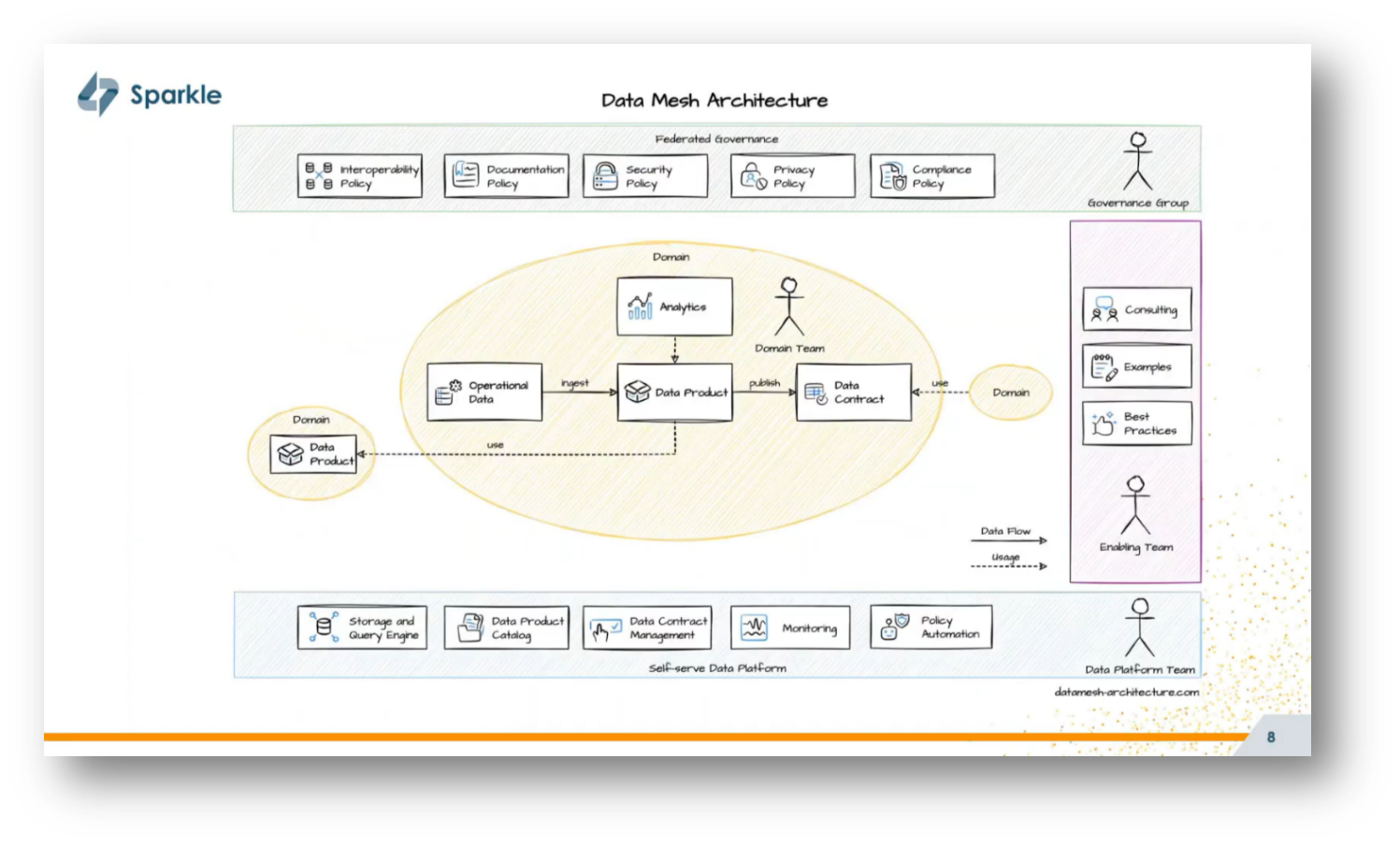
Figure 7 Data Mesh Architecture
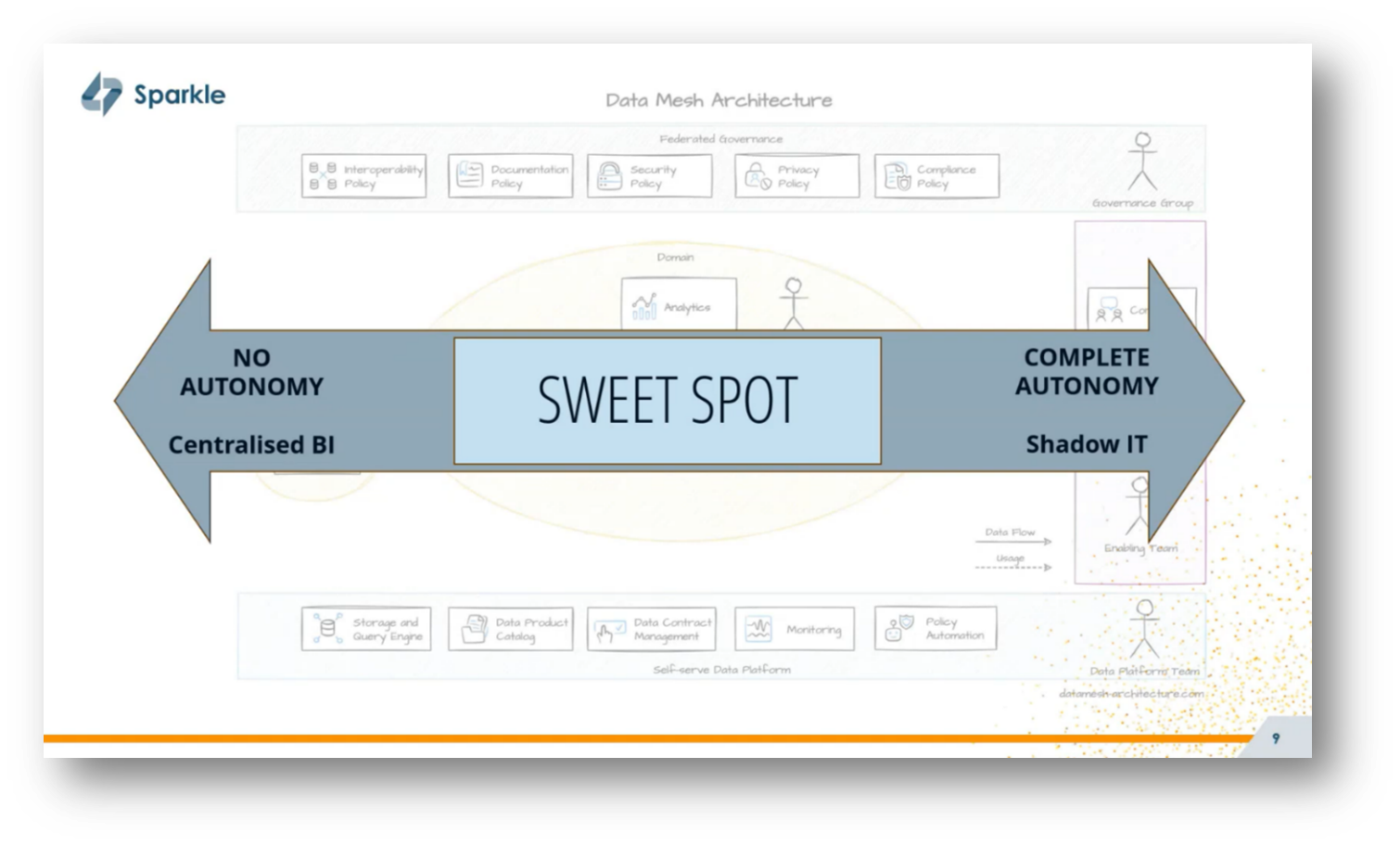
Figure 8 How much should be Centralised and Decentralised?
Future of Data Mesh: its Potential and Future Prospects
The Gartner hype cycle from three years ago categorises Data Mesh as potentially becoming obsolete before reaching maturity, raising questions about its viability. While skepticism around Gartner's forecasts is warranted, the idea behind Data Mesh—specifically the decentralised, domain-oriented approach to delivering data products—remains relevant. Corné notes that this suggests that although the term "Data Mesh" may be replaced or rephrased in the future, its core principles are likely to endure.
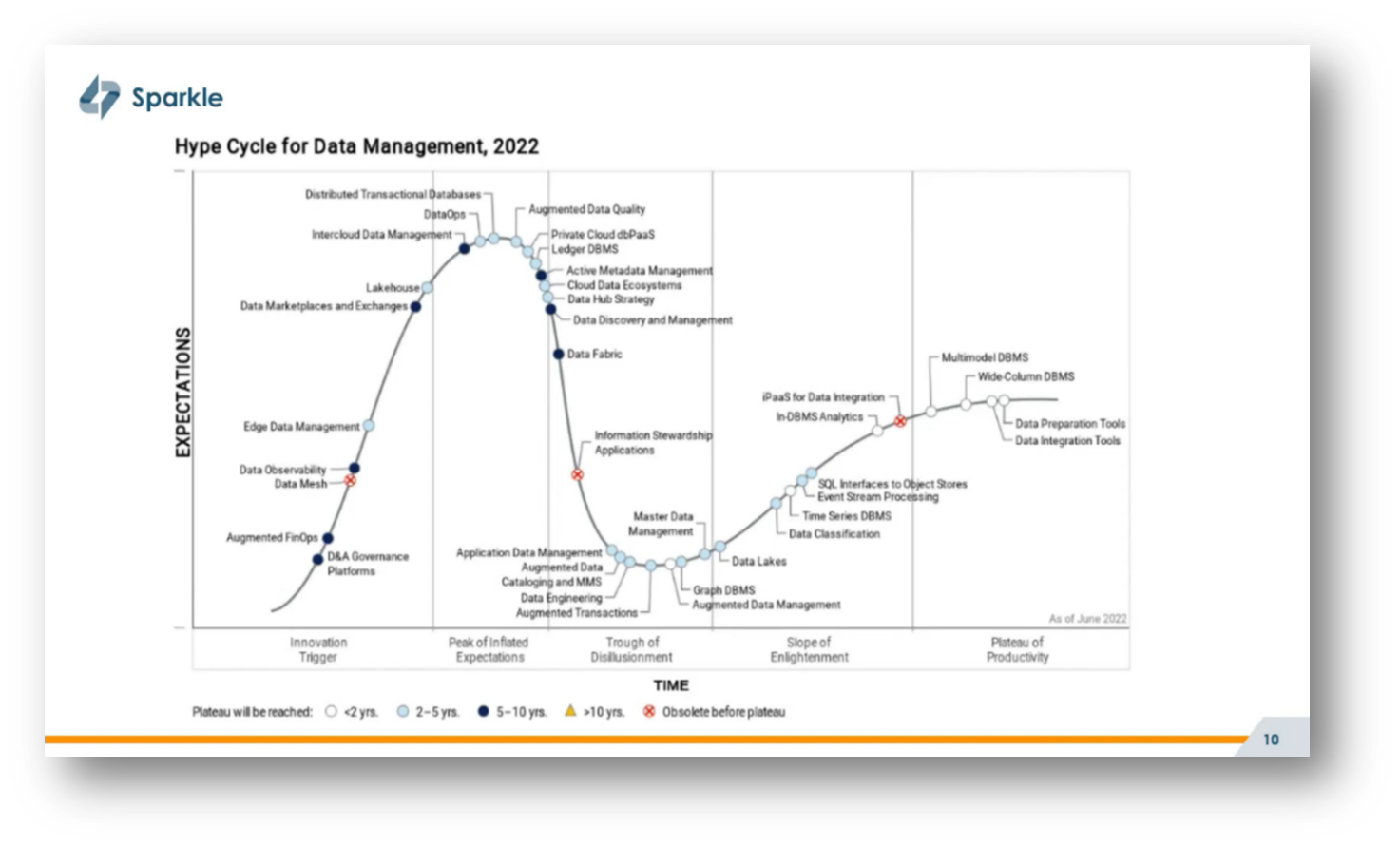
Figure 9 Hype Cycle for Data Management, 2022, Gartner, https://www.denodo.com/en/document/analyst-report/2022-gartner-hype-cycle-data-management

Figure 10 Interpretation of Gartner's Hype Cycle for Data Management, 2022

Figure 11 Offering more information on Learning about Data Mesh
The Implementation of Data Mesh in Various Projects
Corné has extensive experience with Data Mesh principles, beginning in 2017 while working at a large South African insurance company as part of a group-wide VI platform project. Although the term "Data Mesh" was not coined at that time, Corné shares that Data Mesh practices were already being implemented.
From 2019 to 2021, Corné was part of a centralised, enabling team that investigated and designed new patterns to support domain teams in their on-premise implementation using Cloudera and SAP HANA. He worked at a data automation vendor, conducting over 20 proof-of-concept projects that incorporated decentralised principles. Currently, Corné hold the role of a data architect for several domain teams in a large European automated company, focusing on a Data Mesh rollout using a cloud platform built on Snowflake, AWS, and Azure.
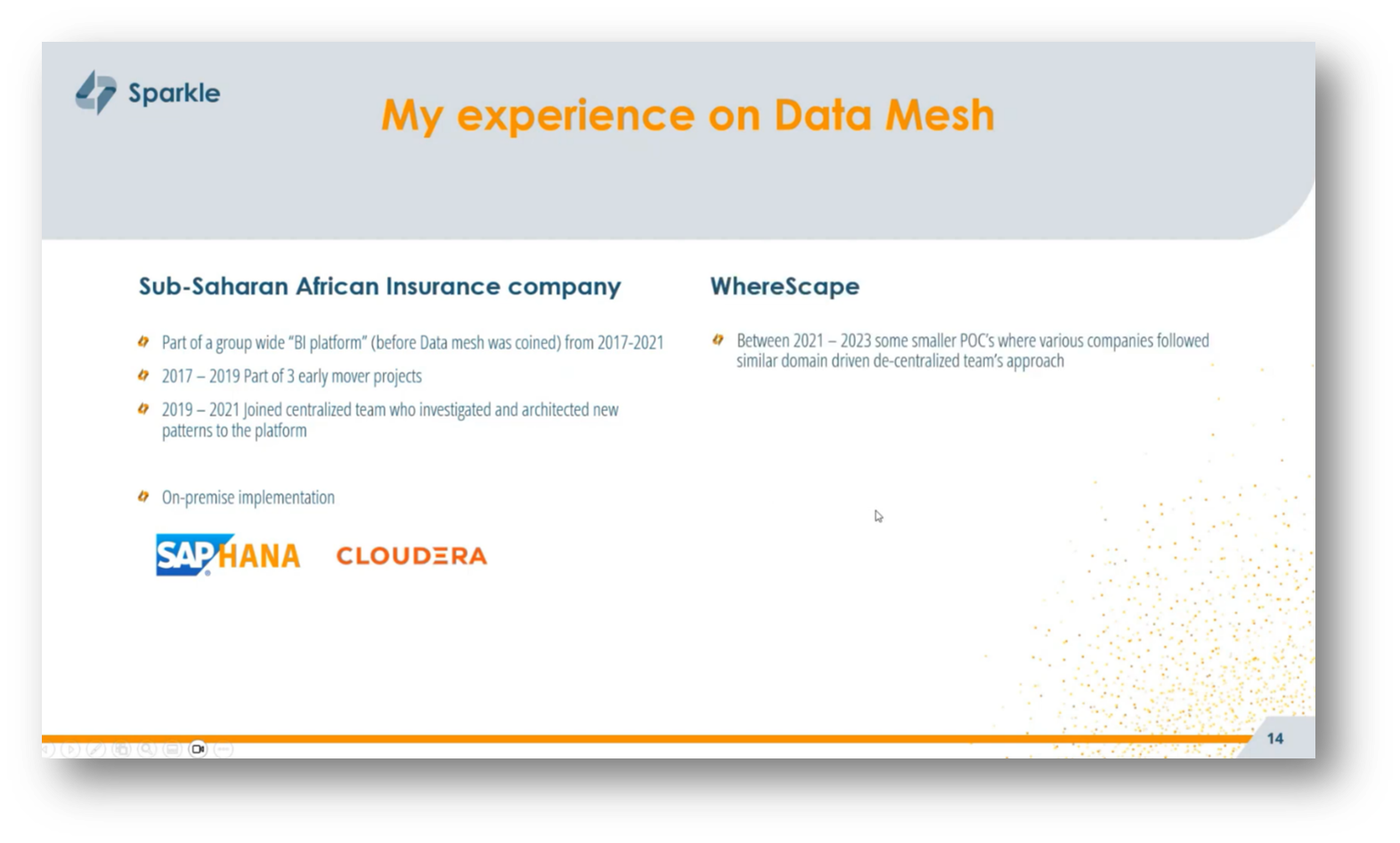
Figure 12 "My experience on Data Mesh"
The Challenges of Early Adoption in Business
As an early adopter in a project, securing buy-in from top management is crucial, as it helps navigate roadblocks and delays by aligning efforts with the company's strategic direction. It's important to recognise that the project may evolve while still in development, akin to a plane taking off before it's fully built; waiting for complete readiness could lead to missed opportunities and excessive costs.
Early adopters should expect to face challenges, as they are integral to refining the platform, akin to assisting with maintenance during a flight. Managing their expectations about their role in building and scaling the platform is essential for success.

Figure 13 "My experience on Data Mesh"

Figure 14 Realities from early adopters

Figure 15 Getting Buy-in from Top Management

Figure 16 "The plane needs to take off before it is completely built"

Figure 17 "Your early adopters are going to experience a lot of pain, make it as easy as possible for them"
Data Mesh Implementation in Large-Scale Organizations
Implementing a Data Mesh in a large organisation often reveals gaps in existing data processes, particularly in areas like cybersecurity and data privacy. This early adoption can lead to scrutiny, as individuals may be held accountable for filling these gaps, even if they predate the implementation. Rather than viewing these challenges negatively, Corné suggests that they should be seen as opportunities for improvement. Given that Data Mesh is typically suited for complex environments with multiple domain teams, practitioners will find themselves closely linked to established IT processes, which may hinder rapid progress. Ultimately, navigating these existing structures can be challenging, but addressing these shortcomings is essential for successful Data Mesh implementation.

Figure 18 “Data Mesh will unveil gaps in existing data processes, but now the early adopters will be involved in resolving them (and potentially even blamed)"

Figure 19 "If you are looking at Data Mesh, it means you already work in a "Complex and large scale environment," so it will be entrenched in IT processes which you won't be allowed to bypass"
Guiding Principles for Successful Data Mesh Implementation
To achieve success in implementing a Data Mesh, it's crucial to have strong support from top management, positioning it as a strategic objective within the organisation. This approach requires defining clear principles that guide the implementation, followed by the development of practical tools and practices.
Corné adds that it is essential to remain adaptable and open to revisiting these principles in the face of roadblocks, as real-world complexities may reveal flaws or nuances that necessitate adjustments. For instance, a principle advocating for the ingestion of data only from original sources may conflict with the autonomy of teams, highlighting the need for flexibility. Ultimately, this structured yet adaptable mindset fosters clarity and confidence in building a scalable data platform that genuinely meets the organisation's needs.

Figure 20 Guiding Principles in order to Succeed
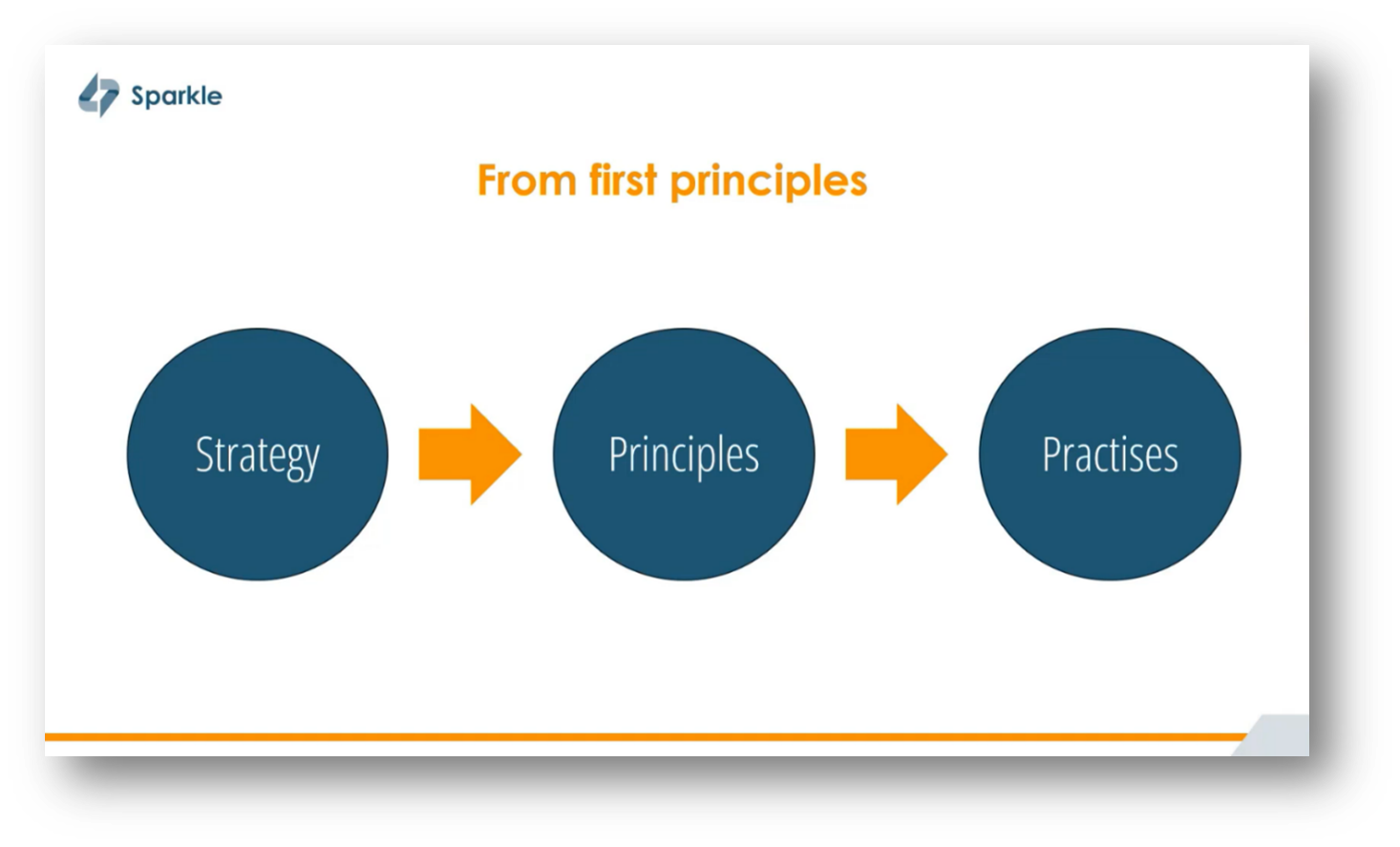
Figure 21 From First Principles

Figure 22 Conflict with Practices

Figure 23 Architecture get to decide if source is origin.

Figure 24 Challenges with Practices of Ingest Origin of Source

Figure 25 Teams Can Decide Whether to Use Origin of Source or Ingest for their own needs
Challenges in Decision Making in Business Technology
In the realm of tool selection and integration, a common principle is to prioritise “best-of-breed tools,” often irrespective of budget; however, this can lead to challenges, as no tool or vendor is perfect. Another prevalent approach is to choose a single vendor for simplified integration, which may not guarantee seamless functionality, as multiple products under the same vendor can still function as separate entities.
The principle of ingesting all data without discrimination, such as replicating an entire relational database, poses risks, including the formation of a data swamp and regulatory concerns surrounding data security. Organisations are typically advised to only utilise data they genuinely need, rather than copying large volumes for potential future use, as this practice can raise security issues.

Figure 26 Some Examples of Principles ... and their Challenges
Navigating the Balance between Analytics and Regulatory Compliance
Navigating the balance between enabling fast analytics and ensuring regulatory compliance presents a significant challenge in privacy by design. While full autonomy for analytics teams can lead to chaos if left unchecked, overly strict compliance measures can hinder agility. Corné notes that a key approach is to focus on identifying and maturing patterns, which encourages architectural thinking and promotes automation.
By developing templates for processes such as data ingestion and resource deployment in cloud platforms using tools like Terraform, organisations can streamline operations and enhance efficiency. This pattern-based mindset not only aids in troubleshooting but also fosters a conceptual understanding of recurring issues, allowing for comprehensive updates to address systemic problems rather than relying on temporary workarounds.

Figure 27 Some Examples of Principles ... and their Challenges Pt. 2
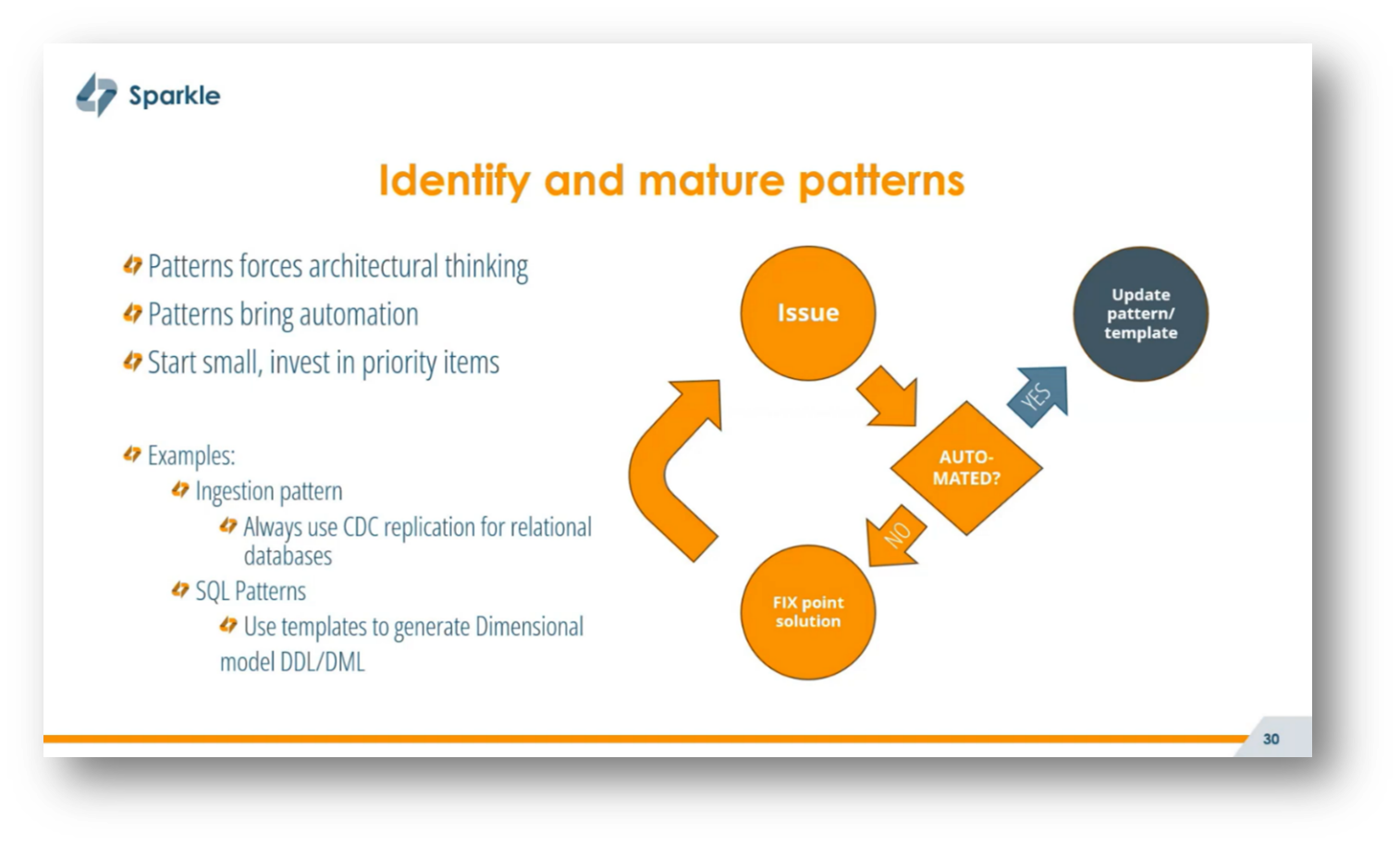
Figure 28 Identify and Mature Patterns
Strategy for Data Mesh Initiative
Corné focuses on the interplay between business strategy and data strategy, particularly in the context of implementing a Data Mesh initiative. Key considerations include understanding the specific business requirements that drive the need for a Data Mesh. Organisations often seek data products to facilitate decision-making, prompting the integration of a Data Mesh when conventional strategies prove inadequate. A common issue arises when rigid processes limit autonomy, leading departments to establish their own IT solutions, including hiring data engineers and utilising platforms like Snowflake, which can result in shadow IT. This indicates a growing recognition of the need for a more flexible and decentralised data approach to meet organisational goals.
Organisations often face challenges with shadow IT, leading management to seek a balance between centralised control and team autonomy. A strategic decision to invest in a trusted data platform can enable departments to operate independently while ensuring compliance with data governance policies. While teams may not fully embrace all principles of Data Mesh, they might align with the core idea of a unified platform for data management that allows for autonomous development. The key issue is finding a way to consolidate data from various domains to ensure quality and governance, which varies by organisation and requires careful navigation of autonomy and oversight.
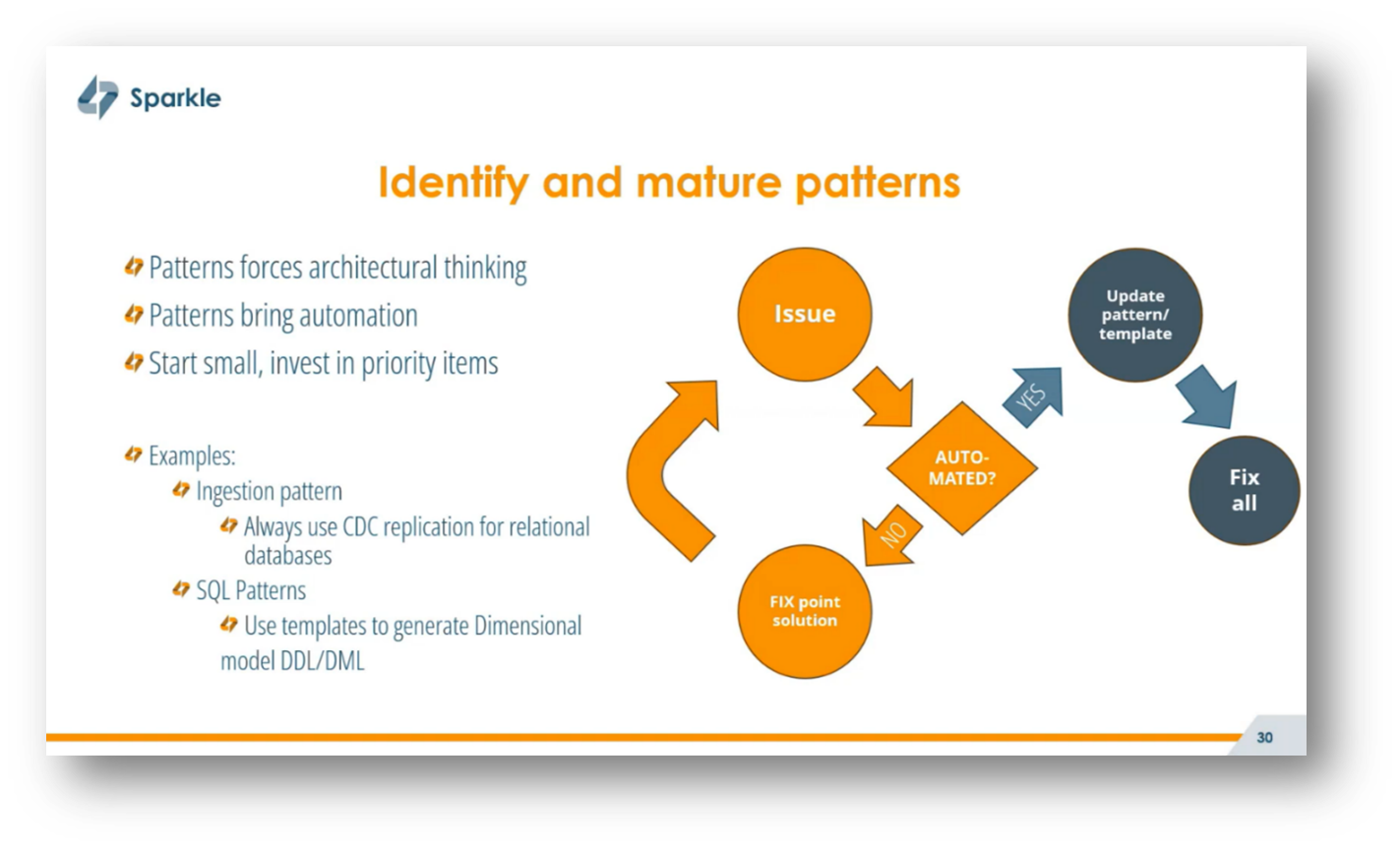
Figure 29 Identify and Mature Patterns

Figure 30 Anecdotes and Examples Across Key Components
Data Ingestion and Security in Data Mesh Platforms
Effective data ingestion is critical for any Data Mesh platform and should be centrally managed to ensure consistency and security. For instance, at an insurance company, a centralised data ingestion approach established clear patterns for handling various source types, such as databases, files, and APIs, while incorporating historical data views and standardised metadata fields. This model not only streamlined processes but also enhanced regulatory compliance by limiting access to a dedicated team, thereby reducing potential risks.
Corné shares on his own Lessons learned and emphasises the importance of central control over ingestion patterns to avoid confusion around historical data management and ingestion cadence, as well as the need for self-service ingestion under restricted conditions. Early adopters may encounter technical debt due to vendor negotiations and workaround solutions, underscoring the necessity for ongoing investment in sustainable data ingestion practices to avoid accumulating unsustainable complexities.
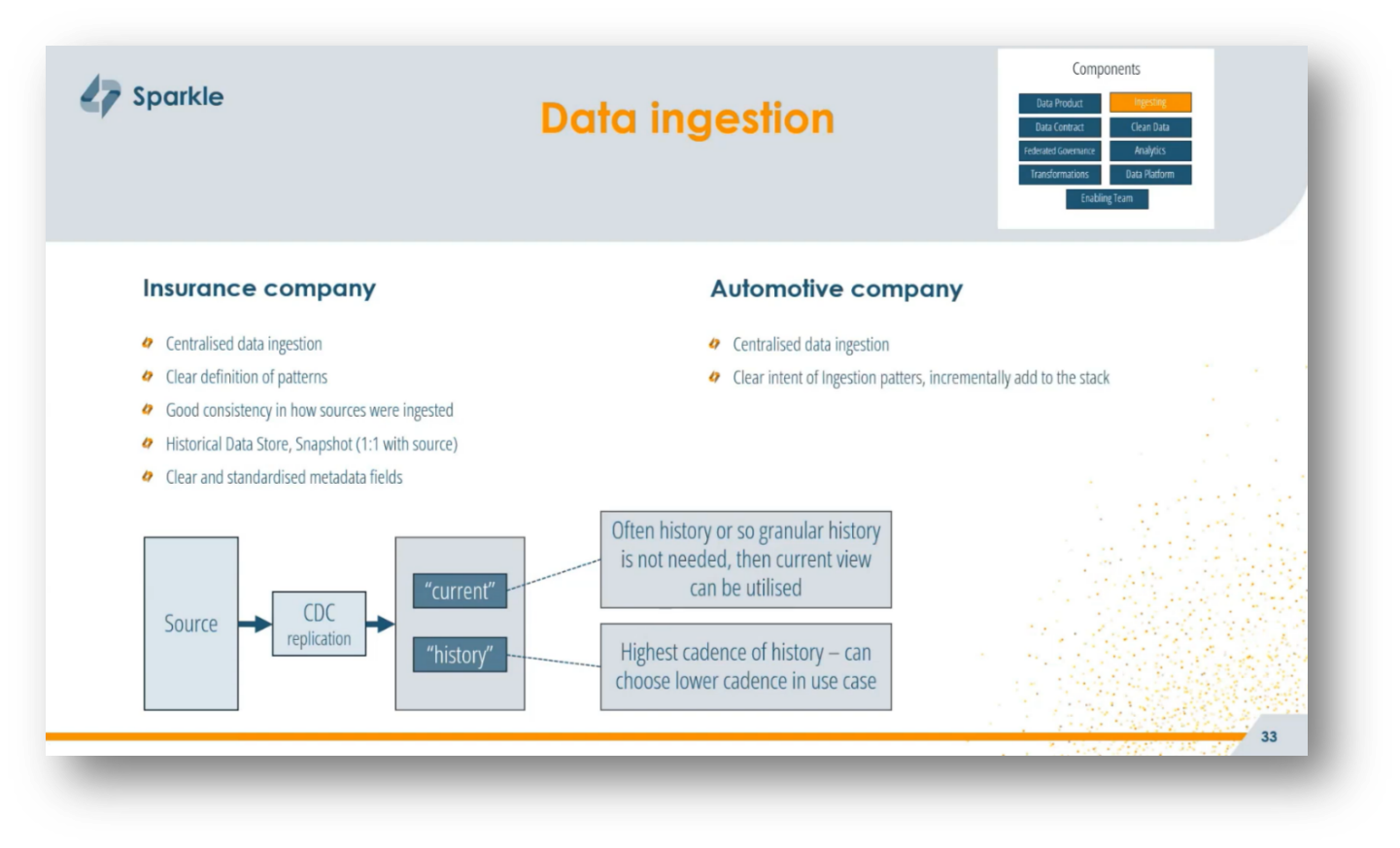
Figure 31 Data Ingestion

Figure 32 Lessons Learnt
Data Product Building and Transformation Architecture
When building data products, understanding the logical layer architecture is crucial, as it varies significantly across different projects. Organisations may adopt widely recognised frameworks like the medallion architecture with bronze, silver, and gold layers, or develop their own variations, such as layers for data provisioning, business transformation, or integration.
Clarity in naming and function is essential to avoid confusion among teams; each layer should have well-defined roles that everyone understands. Providing autonomy to teams can be beneficial, but it's important to establish clear guidelines regarding what is permissible within each layer to prevent divergence and ensure some level of standardisation across projects.
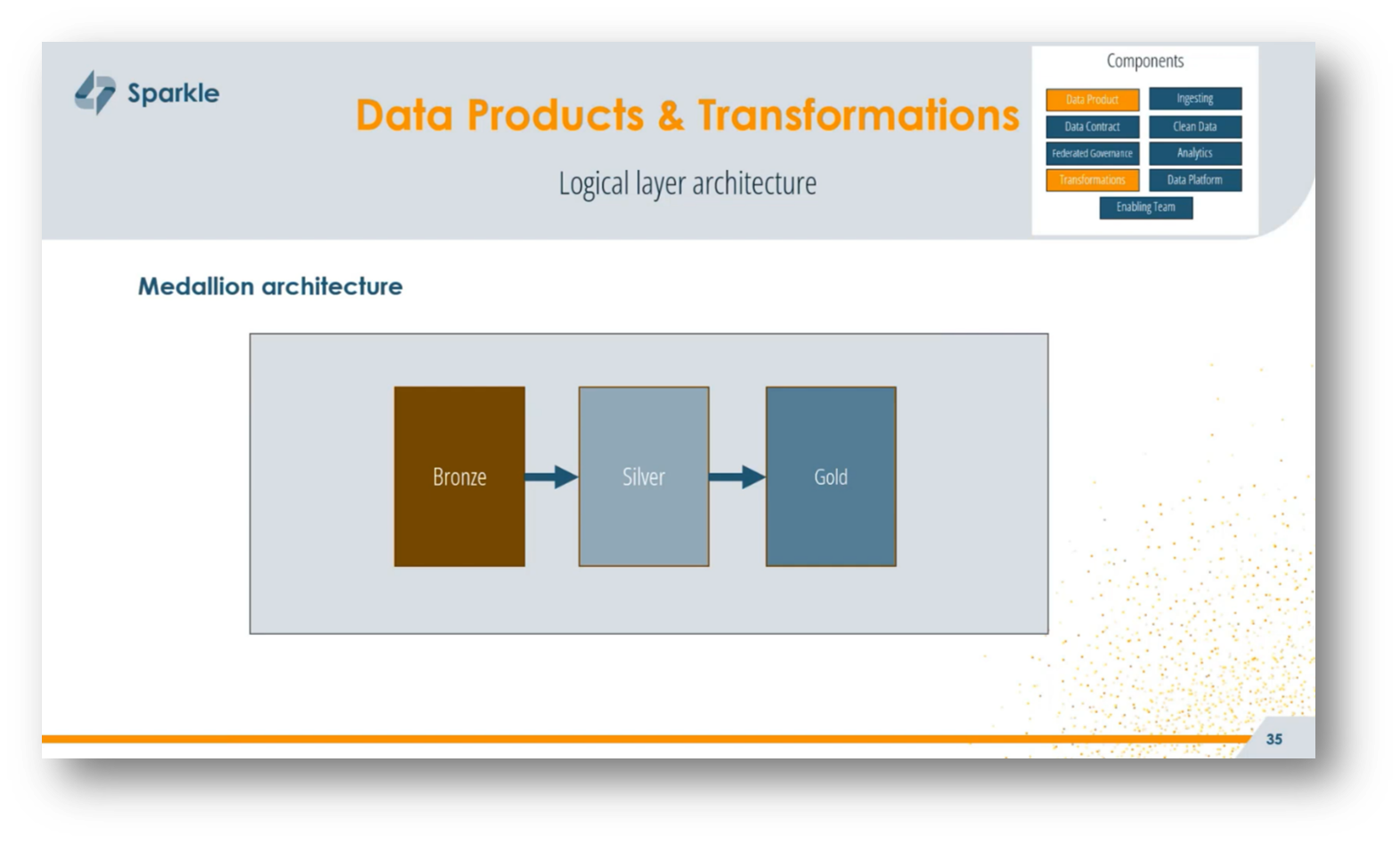
Figure 33 Medallion Architecture
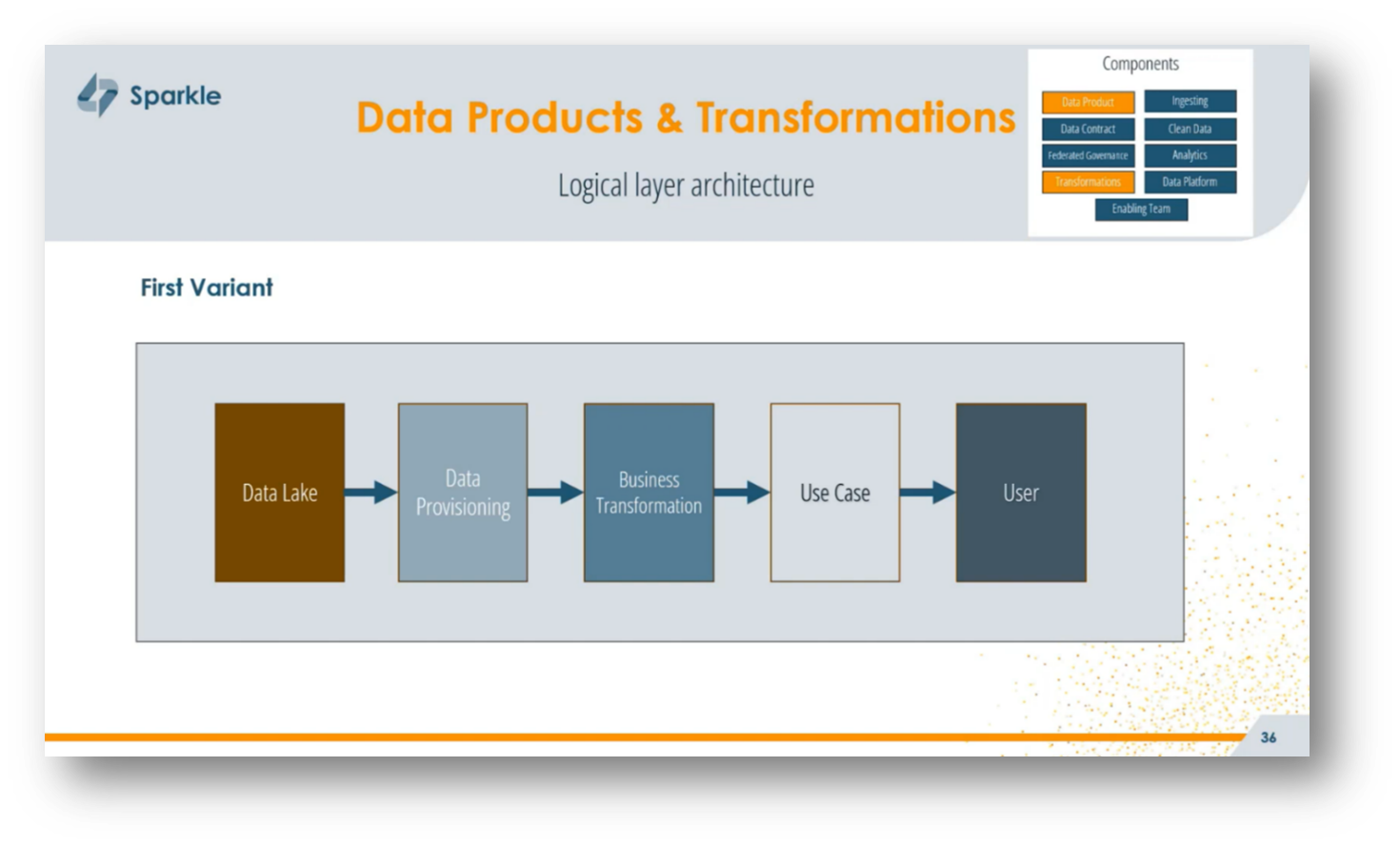
Figure 34 First Variant

Figure 35 2nd Variant

Figure 36 Data Products & Transformation Lessons Learnt
Data Warehousing Methodologies and Challenges
A significant challenge encountered during a data migration project involved navigating five layers of transformations from operational sources to various outputs, leading to the proliferation of business logic across multiple locations. This lack of clear guidelines prompted an internal audit within the insurance company, revealing the necessity for more structured guidance to create a scalable data warehouse.
Consequently, extensive research was conducted on methodologies suitable for large organisations, ultimately leading to the adoption of Data Vault 2.0. This approach focuses on establishing a centrally managed raw vault that provides a passively integrated, enterprise-wide view, where business objects align with a global business glossary, and satellites are organised by source and context, ensuring flexibility and adaptability for future changes.
The approach emphasises providing teams with autonomy within a well-defined framework to ensure consistency across data management, avoiding disparate data warehouse creations. The Data Vault methodology was selected for its adaptability, with centrally managed raw vaults allowing a dedicated team to define business objects and code generation. Individual teams enjoy more freedom in defining business rules for decentralised business vaults while still using automation tools.
A "freedom in a box" concept allows teams to independently determine how to build their data products, within their domain ownership, without strict guidelines. Although many teams still opt for a Kimball-style data mart for their analytics projects, the choice of modelling techniques is influenced by overall goals. While Data Vault demands significant change management and can be seen as overkill for smaller scale initiatives, it remains the preferred option for building a scalable, enterprise-wide data warehouse when implemented effectively.

Figure 37 Data Products & Transformations: Lessons Learnt

Figure 38 Modelling Methodologies
Approaches in Data Warehousing
A key topic with regards to Data Warehousing is the definition and application of domains, which can be classified as functional domains aligned with the organisational structure, and conceptual domains that span multiple functions, such as customer data. Corné notes that ownership of data products within these domains is crucial, as clarity in responsibility is essential to address common challenges in data management frameworks like Data Mesh. The idea is to adapt the theoretical principles of Data Mesh to fit the unique organisational context, ensuring that there are designated owners for data products to minimise ambiguity and enhance accountability.
To effectively define organisational domains, it's essential to consider customer-centric approaches while allowing flexibility in structure rather than enforcing a rigid framework. Organisations can choose to organise teams based on subject areas or functional business units, recognising that there may be a need for sub-domains due to varying team levels. Engaging in discussions to assess levels of decentralisation or federation is crucial for making informed decisions on how to split these domains. Once a structure is established, it should be adhered to in order to maintain control and prevent unstructured growth, all while understanding that ongoing debates about domain division are common and solutions may vary.

Figure 39 Modelling Methodologies
Data Transformations and Abstraction in Data Platforms
Corné highlights the importance of abstracting logic from data platforms in data products and transformations, particularly observed in two projects: an insurance company using Data Vault with automation through tools like We Escape, and an automotive company employing DBT for data transformations. This architectural approach ensures that business logic remains external to the chosen data platform, enhancing autonomy and enabling easier migration if the data platform changes in the future. The emphasis on template-driven design promotes reusability and efficiency in coding, a practice that gained recognition during the author's tenure at a vendor and continues to see adoption in the field. The concept of data contracts alongside abstracted logic is identified as a noteworthy area for further exploration.

Figure 40 Abstracting the Logic from Data Platform
Implementation of Data Contracts in Business
The concept of data contracts is essential for facilitating the consumption of data products across different domains, serving as agreements between consumers and producers. While discussions around this concept were limited in the insurance sector, focusing on aspects such as quality assurance, SLAs, and collaboration between teams, the understanding has matured in the automotive industry with more accessible resources and tools like DBT for implementing contracts.
Despite the availability of literature and technical solutions, the practical implementation of data contracts remains challenging, primarily due to the lack of incentives for teams to maintain their data products, quality, and interface. For successful rollout, companies may need top-down directives or financial motivation to ensure compliance with contractual obligations and standards in the increasingly complex data landscape.

Figure 41 Data Contracts
Vendor Management and Tech Stack Selection in Organizations
When choosing a technology stack and managing vendors in large organisations, it's crucial to adhere to established vendor management processes while taking care not to rush decisions, as poor selections can have long-lasting consequences. Engaging with the teams that will use the tools can provide insights into potential shortcomings. Building strong, professional relationships with trusted vendor representatives is essential, as documentation may not always reflect practical realities. Corné suggests preparing for the inevitability of issues arising with vendors, regardless of the caution taken, and being ready to adjust your tech stack as needed.

Figure 42 Setting up the Tech Stack and Dealing with Vendors

Figure 43 Selecting the Data Platform
Impact of Global Policies and Legislations on Data Design
Corné highlights the differences in the implementation of global privacy policies such as GDPR and South Africa's POPI Act, particularly in the context of data governance for insurance and automotive companies. While GDPR has been well-established since 2016, the POPI Act sparked confusion during its early implementation, impacting data retention practices for life insurance.
The concept of "privacy by design" is emphasised as essential in developing data platforms, encouraging organisations to avoid indiscriminate data collection and instead focus on specific processing purposes. The variability in legal interpretations underscores the necessity for compliance oversight from legal professionals, as only their opinions guide adherence to regulations. Overall, the evolving legislative landscape necessitates close collaboration between data teams and legal departments to navigate the complexities of data privacy laws effectively.

Figure 44 Global Policies like POPIA and GDPR

Figure 45 Global Policies like POPIA and GDPR Pt.2

Figure 46 Final Remarks
Autonomy in Decentralized Systems
Corné addresses questions related to data quality and governance within the context of centralised versus decentralised data management. He highlights key points, including the importance of implementing minimum data quality standards for data products and ensuring that rules such as checks for null values are defined and adhered to before deployment. A suggestion is presented for Federated Governance teams to oversee the establishment of these quality policies, with tools like Collibra or Purview used for monitoring and maintaining data integrity. Additionally, the use of observability tools is proposed by Corné to track the deterioration of data quality over time, with a balanced approach allowing autonomy for data product teams while ensuring compliance with central standards.

Figure 47 Final Remarks Pt.2

Figure 48 Closing Slide
Data Quality, Automation, and Role in Data Products
In data product development, it's crucial to establish clear quality expectations, which often originate from downstream consumers who may not be known to the data product team. A data contract, envisioned as a comprehensive YAML file, outlines these expectations, including required fields and quality rules, serving as a binding agreement that defines minimum standards for data quality that consumers expect.
Initially, a data product may be developed based on the creators' quality standards, but once consumers are identified, a formal contract should be established to specify detailed requirements. Additionally, in the context of Data Vault architecture, while much can be automated within the raw Data Vault, it's essential to clearly define core business concepts, ideally in a centralised manner or in collaboration with relevant domains.
The role of a functional domain splits in defining core business concepts and shaping data hub structures, emphasising the potential for automation in processing raw data. By utilising a logical data model or business data model that incorporates business rules in pseudocode, organisations can streamline the generation of business vault views on top of raw vault objects. Automation tools can facilitate the creation of approximately 70-80% of the necessary code, which can then be refined by decentralised data engineering teams to incorporate specific best practices and nuances. While the process allows for centralised automation, it also empowers business teams to define and adjust business logic as needed, illustrating a hybrid approach to data modelling that enhances efficiency and collaboration across teams.
Naming Strategies in Project Implementation
Corné shares a humorous anecdote regarding the frequent changes in the names of domains and business units in their projects. He mentions his own experience with three separate instances where this occurred. These changes stemmed from mergers, acquisitions, and management decisions to reorganise departments. Corné then emphasises that such name changes often impact technical implementations, including database names. To mitigate these issues, he advocates for a clear separation between logical definitions and technical implementations, suggesting that if logical descriptions can be decoupled from their technical counterparts, name changes could be managed more easily without significant disruption to the technical aspects.
If you would like to join the discussion, please visit our community platform, the Data Professional Expedition.
Additionally, if you would like to be a guest speaker on a future webinar, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!